
Escenario 1: Cualquier banco global hoy en día tiene más de 100 millones de clientes que realizan miles de millones de transacciones cada mes.
Escenario 2: Los sitios web de redes sociales o los sitios web de comercio electrónico rastrean el comportamiento del cliente en el sitio web y luego brindan información / producto relevante.
Los sistemas tradicionales tienen dificultades para hacer frente a esta escala al ritmo requerido de manera rentable.
Aquí es donde las plataformas de Big Data vienen a ayudar. En este artículo, te presentamos el fascinante mundo de Hadoop. Hadoop es útil cuando tratamos con datos enormes. Puede que no haga que el proceso sea más rápido, pero nos da la capacidad de utilizar la capacidad de procesamiento paralelo para manejar big data. En resumen, Hadoop nos da la capacidad de lidiar con las complejidades de alto volumen, velocidad y variedad de datos (conocido popularmente como 3V).
Tenga en cuenta que, además de Hadoop, existen otras plataformas de big data, por ejemplo, NoSQL (MongoDB es la más popular), las veremos más adelante.
Introducción a Hadoop
Hadoop es un ecosistema completo de proyectos de código abierto que nos proporciona el marco para tratar con big data. Comencemos con una lluvia de ideas sobre los posibles desafíos de lidiar con big data (en sistemas tradicionales) y luego veamos la capacidad de la solución Hadoop.
Los siguientes son los desafíos en los que puedo pensar al tratar con big data:
1. Alta inversión de capital en la adquisición de un servidor con alta capacidad de procesamiento.
2. Enorme tiempo invertido
3. En caso de una consulta larga, imagine que ocurre un error en el último paso. Perderás mucho tiempo haciendo estas iteraciones.
4. Dificultad para generar consultas sobre el programa
Así es como Hadoop resuelve todos estos problemas:
1. Gran inversión de capital en la adquisición de un servidor con alta capacidad de procesamiento: Los clústeres de Hadoop funcionan en hardware básico normal y mantienen varias copias para garantizar la confiabilidad de los datos. Se pueden conectar un máximo de 4500 máquinas juntas usando Hadoop.
2. Enorme tiempo invertido : El proceso se divide en partes y se ejecuta en paralelo, lo que permite ahorrar tiempo. Se puede procesar un máximo de 25 Petabytes (1 PB = 1000 TB) de datos usando Hadoop.
3. En caso de una consulta larga, imagine que ocurre un error en el último paso. Perderás mucho tiempo haciendo estas iteraciones : Hadoop crea copias de seguridad de conjuntos de datos en todos los niveles. También ejecuta consultas en conjuntos de datos duplicados para evitar la pérdida del proceso en caso de falla individual. Estos pasos hacen que el procesamiento de Hadoop sea más preciso y exacto.
4. Dificultad para generar consultas sobre el programa : Las consultas en Hadoop son tan simples como codificar en cualquier idioma. Solo necesita cambiar la forma de pensar en la creación de una consulta para permitir el procesamiento en paralelo.
Antecedentes de Hadoop
Con un aumento en la penetración de Internet y el uso de Internet, los datos capturados por Google aumentaron exponencialmente año tras año. Solo para darle una estimación de este número, en 2007 Google recopiló un promedio de 270 PB de datos cada mes. El mismo número aumentó a 20000 PB todos los días en 2009. Obviamente, Google necesitaba una mejor plataforma para procesar datos tan enormes. Google implementó un modelo de programación llamado MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data...., que podría procesar estos 20000 PB por día. Google ejecutó estas operaciones de MapReduce en un sistema de archivos especial llamado Google File System (GFS). Lamentablemente, GFS no es un código abierto.
Doug Cutting y Yahoo! realizó ingeniería inversa del modelo GFS y construyó un sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Además, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... Hadoop (HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información...) paralelo. El software o marco que admite HDFS y MapReduce se conoce como Hadoop. Hadoop es un código abierto y distribuido por Apache.
Quizás te interese: Introducción a MapReduce
Marco de procesamiento de Hadoop
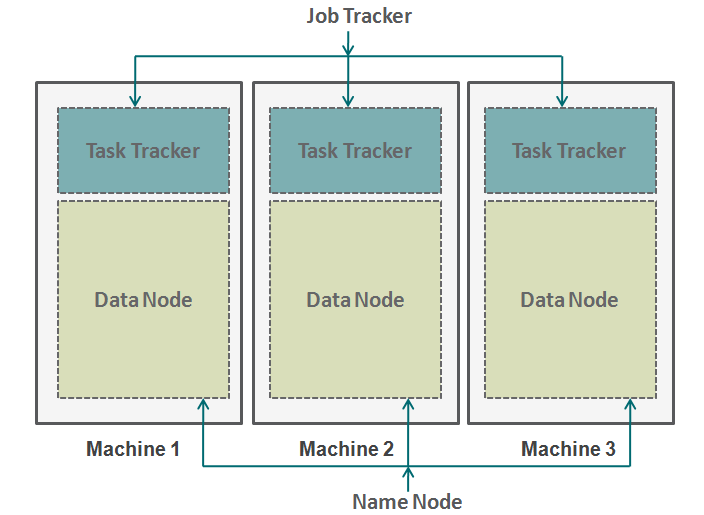
Dibujemos una analogía de nuestra vida diaria para comprender el funcionamiento de Hadoop. La base de la pirámide de cualquier empresa son las personas que son contribuyentes individuales. Pueden ser analistas, programadores, labores manuales, cocineros, etc. La gestión de su trabajo es el director del proyecto. El director del proyecto es responsable de la finalización satisfactoria de la tarea. Necesita distribuir la mano de obra, suavizar la coordinación entre ellos, etc. Además, la mayoría de estas empresas tienen un gerente de personal, que está más preocupado por retener la plantilla.

Hadoop funciona en un formato similar. En la parte inferior tenemos las máquinas dispuestas en paralelo. Estas máquinas son análogas al contribuyente individual en nuestra analogía. Cada máquina tiene un nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... de datos y un rastreador de tareas. El nodo de datos también se conoce como HDFS (Hadoop Distributed File SystemEl Sistema de Archivos Distribuido de Hadoop (HDFS) es una parte fundamental del ecosistema Hadoop, diseñado para almacenar grandes volúmenes de datos de manera distribuida. HDFS permite el almacenamiento escalable y la gestión eficiente de datos, dividiendo archivos en bloques que se replican en diferentes nodos. Esto asegura la disponibilidad y la resistencia ante fallos, facilitando el procesamiento de datos masivos en entornos de big data....) y el rastreador de tareas también se conoce como reductores de mapas.
El nodo de datos contiene todo el conjunto de datos y el rastreador de tareas realiza todas las operaciones. Puede imaginarse el rastreador de tareas como sus brazos y piernas, lo que le permite realizar una tarea y un nodo de datos como su cerebro, que contiene toda la información que desea procesar. Estas máquinas están trabajando en silos y es muy importante coordinarlas. Los rastreadores de tareas (administrador de proyectos en nuestra analogía) en diferentes máquinas están coordinados por un rastreador de trabajos. Job Tracker**Job Tracker: Una Herramienta Esencial para la Búsqueda de Empleo** Job Tracker es una plataforma diseñada para facilitar la búsqueda de empleo, permitiendo a los usuarios organizar y seguir sus solicitudes de trabajo. Con características como la gestión de currículums, alertas de nuevas ofertas y análisis de tendencias laborales, Job Tracker ayuda a los solicitantes a optimizar su proceso de búsqueda y aumentar sus posibilidades de éxito en el competitivo... se asegura de que cada operación se complete y si hay una falla en el proceso en cualquier nodo, debe asignar una tarea duplicada a algún rastreador de tareas. El rastreador de trabajos también distribuye toda la tarea a todas las máquinas.
Por otro lado, un nodo de nombre coordina todos los nodos de datos. Gobierna la distribución de datos que van a cada máquina. También verifica cualquier tipo de purga que haya ocurrido en alguna máquina. Si ocurre tal depuración, encuentra los datos duplicados que se enviaron a otro nodo de datos y los vuelve a duplicar. Puede pensar en este nodo de nombre como el administrador de personas en nuestra analogía, que se preocupa más por la retención de todo el conjunto de datos.
¿Cuándo no usar Hadoop?
Hasta ahora, hemos visto cómo Hadoop ha hecho posible el manejo de big data. Pero en algunos escenarios no se recomienda la implementación de Hadoop. A continuación se muestran algunos de esos escenarios:
- Acceso a datos de baja latencia: acceso rápido a pequeñas partes de datos
- Modificación de múltiples datos: Hadoop se adapta mejor solo si nos preocupa principalmente la lectura de datos y no la escritura de datos.
- Muchos archivos pequeños: Hadoop encaja mejor en escenarios, donde tenemos pocos archivos pero grandes.
Notas finales
Este artículo le ofrece una visión de cómo Hadoop llega al rescate cuando tratamos con datos enormes. Comprender el funcionamiento de Hadoop es muy esencial antes de comenzar a codificarlo. Esto se debe a que necesita cambiar la forma de pensar de un código. Ahora debe comenzar a pensar en habilitar el procesamiento paralelo. Puede realizar muchos tipos diferentes de procesos en Hadoop, pero necesita convertir todos estos códigos en una función de reducción de mapas. En los próximos artículos, explicaremos cómo puede convertir su lógica simple a la lógica Map-Reduce basada en Hadoop. También tomaremos estudios de casos específicos de lenguaje R para construir una comprensión sólida de la aplicación de Hadoop.
¿Le resultó útil el artículo? Comparta con nosotros cualquier aplicación práctica de Hadoop que haya encontrado en su trabajo. Háganos saber su opinión sobre este artículo en el cuadro a continuación.





