Introduction
When creating a machine learning model in real life, it is almost rare that all the variables in the dataset are useful for creating a model. Adding redundant variables reduces the generalizability of the model and can also reduce the overall precision of a classifier. What's more, adding more and more variables to a model increases the overall complexity of the model.
According to him Law of parsimony of ‘Occam's Razor’, the best explanation of a problem is the one that involves the fewest possible assumptions. Therefore, feature selection becomes an indispensable part of building machine learning models.
Target
The goal of feature selection in machine learning is to find the best feature set that allows you to build useful models of the studied phenomena..
Techniques for function selection in machine learning can be broadly classified into the following categories:
Supervised techniques: These techniques can be used for labeled data and are used to identify relevant characteristics to increase the efficiency of supervised models such as classification and regression..
Unsupervised techniques: These techniques can be used for unlabeled data.
From a taxonomic point of view, These techniques are classified into:
A. Filtering methods
B. Wrapping methods
C. Integrated methods
D. Hybrid methods
In this article, we will discuss some popular feature selection techniques in machine learning.
A. Filtering methods
Filter methods collect intrinsic properties of measured characteristics through univariate statistics rather than cross-validation performance. These methods are faster and less computationally expensive than wrapper methods. Cuando se trata de datos de alta dimension"Dimension" It is a term that is used in various disciplines, such as physics, Mathematics and philosophy. It refers to the extent to which an object or phenomenon can be analyzed or described. In physics, for instance, there is talk of spatial and temporal dimensions, while in mathematics it can refer to the number of coordinates necessary to represent a space. Understanding it is fundamental to the study and..., it is computationally cheaper to use filtering methods.
Let's analyze some of these techniques:
Information gain
The information gain calculates the entropy reduction from the transformation of a data set. Se puede utilizar para la selección de características evaluando la ganancia de información de cada variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... en el contexto de la variable de destino.
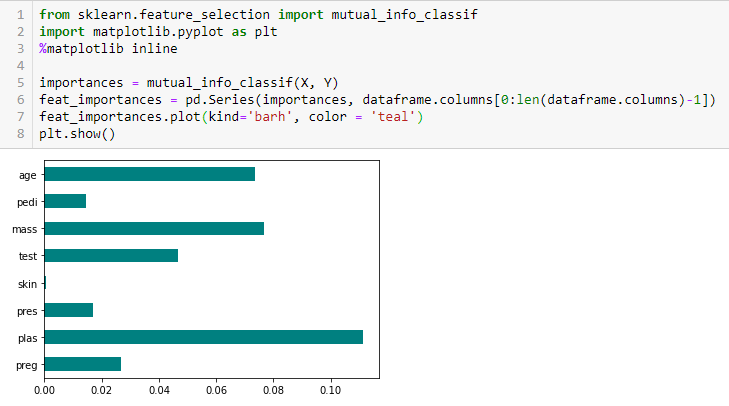
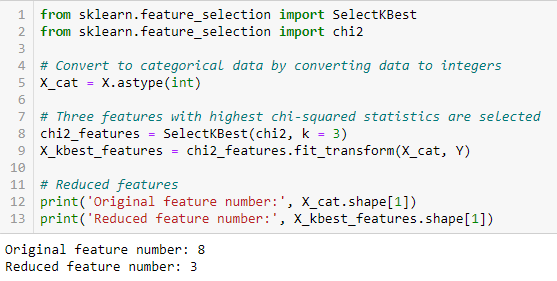
Chi-square test
The chi-square test is used for categorical characteristics in a data set. We calculate Chi-square between each characteristic and the target and select the desired number of characteristics with the best Chi-square scores.. To correctly apply chi-square to test the relationship between various characteristics in the data set and the target variable, the following conditions must be met: variables must be categorical, sampled regardless and the values must have a expected frequency greater than 5.
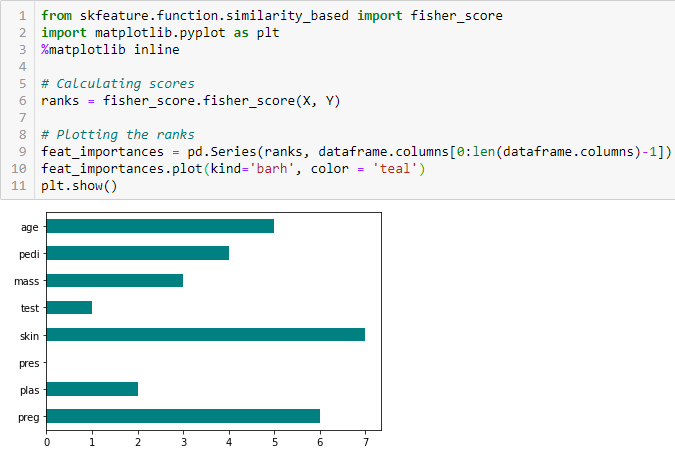
Fisher score
The Fisher score is one of the most widely used selection methods for supervised characteristics. The algorithm that we will use returns the ranges of the variables based on the fisherman's score in descending order. Then we can select the variables according to the case.
Correlation coefficient
La correlación es una measureThe "measure" it is a fundamental concept in various disciplines, which refers to the process of quantifying characteristics or magnitudes of objects, phenomena or situations. In mathematics, Used to determine lengths, Areas and volumes, while in social sciences it can refer to the evaluation of qualitative and quantitative variables. Measurement accuracy is crucial to obtain reliable and valid results in any research or practical application.... de la relación lineal de 2 or more variables. By correlation, we can predict one variable from the other. The logic behind using correlation for feature selection is that good variables are highly correlated with target. What's more, the variables must be correlated with the objective, but they must not be correlated with each other.
If two variables are correlated, we can predict one from the other. Therefore, if two characteristics are correlated, the model really only needs one of them, since the second does not add additional information. We will use Pearson's correlation here.
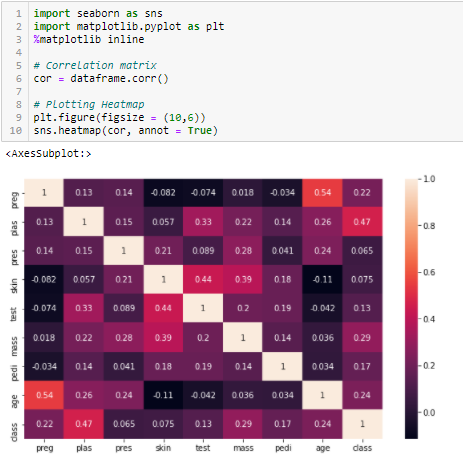
We need to set an absolute value, Let's say 0.5 as the threshold for selecting variables. If we find that the predictor variables are correlated with each other, we can discard the variable that has a lower correlation coefficient value with the target variable. We can also calculate multiple correlation coefficients to check if more than two variables are correlated with each other. This phenomenon is known as multicollinearity..
Variance threshold
The variance threshold is a simple baseline approach to feature selection. Eliminate all characteristics whose variation does not reach a threshold. By default, removes all zero variance characteristics, namely, characteristics that have the same value in all samples. We assume that the characteristics with a higher variance may contain more useful information., but note that we are not taking into account the relationship between the characteristic variables or the characteristic and target variables, which is one of the drawbacks of filter methods.

Get_support returns a Boolean vector where True means that the variable does not have zero variance.
Mean absolute difference (MAD)
‘The mean absolute difference (MAD) calculates the absolute difference from the mean value. The main difference between the variance measures and MAD is the absence of the square in the latter.. The MAD, like the variance, it is also a variant of scale ». [1] This means that the higher the DMA, greater discriminatory power.
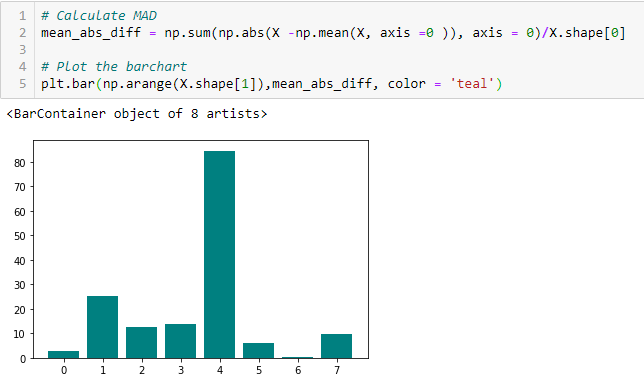
Dispersion ratio
‘Another measure of dispersion applies the arithmetic mean (AM) and the geometric mean (GM). For a given characteristic (positive) XI in n patterns, AM and GM are given by
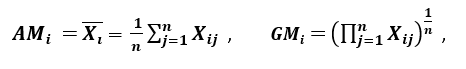
respectively; as SOYI ≥ GMI, with equality if and only if Xi1 = Xi2 =…. = Xin, then the proportion
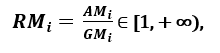
can be used as a measure of dispersion. A greater dispersion implies a greater value of Ri, so a more relevant feature. Conversely, when all feature samples have (about) the same value, Ri is close to 1, which indicates a characteristic of low relevance '. [1]

 ‘
‘
B. Wrapping methods:
Wrappers require some method to search space for all possible subsets of features, evaluating its quality by learning and evaluating a classifier with that subset of characteristics. The feature selection process is based on a specific machine learning algorithm that we try to fit into a given data set. Follows a greedy search approach by evaluating all possible combinations of characteristics against the evaluation criteria. Wrapper methods generally result in better predictive accuracy than filter methods.
Let's analyze some of these techniques:
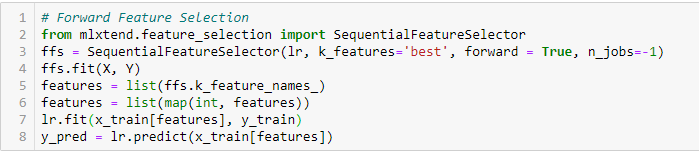
Selection of advanced functions
This is an iterative method where we start with the best performing variable against the target. Then, we select another variable that offers the best performance in combination with the first variable selected. This process continues until the preset criteria is reached..
Backward feature removal
This method works the exact opposite of the forward feature selection method. Here, we start with all the available functions and build a model. Then, we take the model variable that gives the best evaluation measure value. This process continues until the preset criteria is reached..
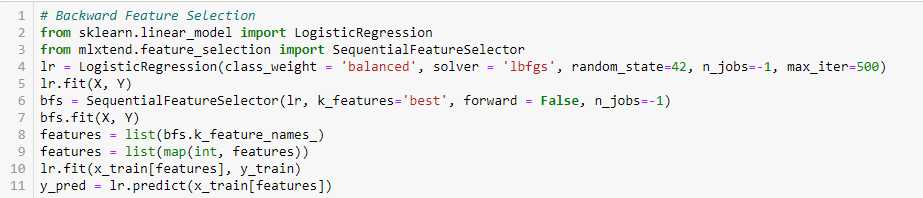
This method, along with the one discussed above, also known as the sequential feature selection method.
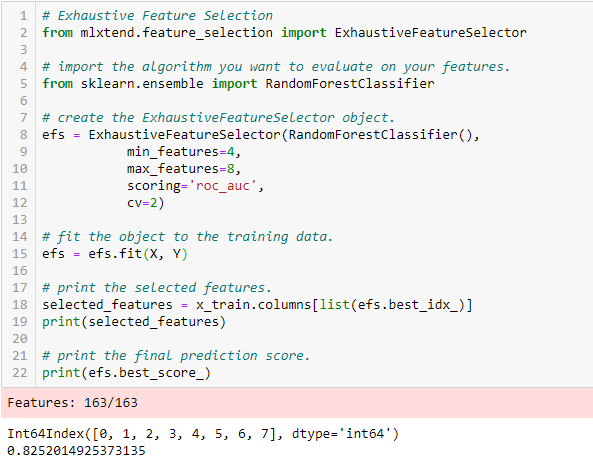
Comprehensive feature selection
This is the most robust feature selection method covered so far. This is a brute force evaluation of each feature subset. This means that it tries all possible combinations of the variables and returns the best performing subset.
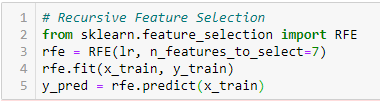
Elimination of recursive features
‘Dado un estimatorThe "Estimator" is a statistical tool used to infer characteristics of a population from a sample. It relies on mathematical methods to provide accurate and reliable estimates. There are different types of estimators, such as the unbiased and the consistent, that are chosen according to the context and objective of the study. Its correct use is essential in scientific research, surveys and data analysis.... externo que asigna pesos a las características (for instance, the coefficients of a linear model), the goal of eliminating recursive features (RFE) is to select features recursively considering increasingly smaller feature sets. First, the estimator is trained on the initial set of features and the importance of each feature is obtained through a coef_ attribute or through a feature_importances_ attribute.
Later, less important features are removed from the current feature set. This procedure is recursively repeated on the pruned set until the desired number of features to select is finally reached.. ‘[2]
C. Integrated methods:
These methods encompass the benefits of both wrap and filter methods., by including feature interactions but also maintaining a reasonable computational cost. Los métodos integrados son iterativos en el sentido de que se encargan de cada iteración del proceso de trainingTraining is a systematic process designed to improve skills, physical knowledge or abilities. It is applied in various areas, like sport, Education and professional development. An effective training program includes goal planning, regular practice and evaluation of progress. Adaptation to individual needs and motivation are key factors in achieving successful and sustainable results in any discipline.... del modelo y extraen cuidadosamente las características que más contribuyen al entrenamiento para una iteración en particular.
Let's analyze some of these techniques, Click here:
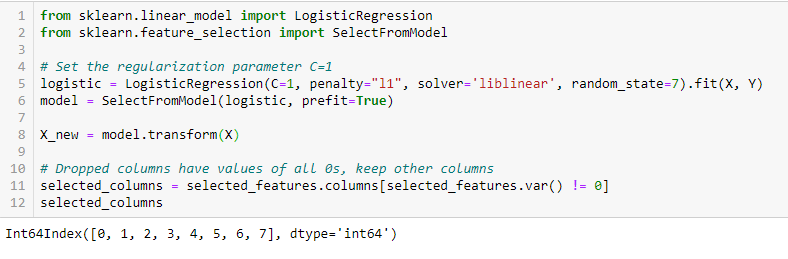
RegularizationRegularization is an administrative process that seeks to formalize the situation of people or entities that operate outside the legal framework. This procedure is essential to guarantee rights and duties, as well as to promote social and economic inclusion. In many countries, Regularization is applied in migratory contexts, labor and tax, allowing those who are in irregular situations to access benefits and protect themselves from possible sanctions.... LASSO (L1)
La regularización consiste en agregar una penalización a los diferentes parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project.... del modelo de aprendizaje automático para reducir la libertad del modelo, namely, to avoid over adjustment. In the regularization of linear models, the penalty is applied on the coefficients that multiply each of the predictors. Of the different types of regularization, Lasso or L1 has the property of reducing some of the coefficients to zero. Therefore, that feature can be removed from the model.
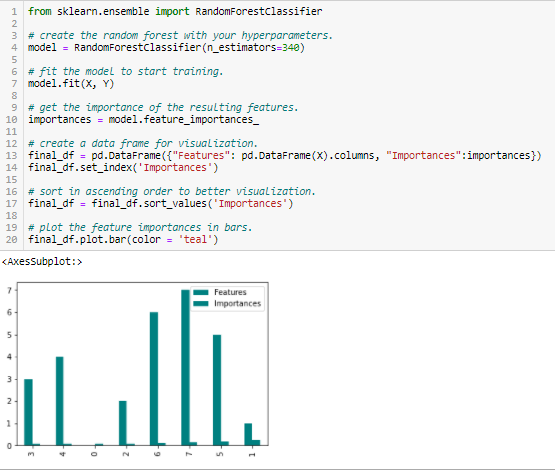
Importance of the random forest
Random Forests is a kind of bagging algorithm that adds a specific number of decision trees. Las estrategias basadas en árboles utilizadas por los bosques aleatorios se clasifican naturalmente según lo bien que mejoran la pureza del nodeNodo is a digital platform that facilitates the connection between professionals and companies in search of talent. Through an intuitive system, allows users to create profiles, share experiences and access job opportunities. Its focus on collaboration and networking makes Nodo a valuable tool for those who want to expand their professional network and find projects that align with their skills and goals...., or in other words, a decrease in impurity (Gini impurity) over all the trees. The nodes with the greatest decrease in impurities occur at the beginning of the trees, while the notes with the least decrease in impurities occur at the end of the trees. Therefore, when pruning trees under a particular node, we can create a subset of the most important characteristics.
Conclution
We have discussed some techniques for function selection. We have purposely left feature extraction techniques like Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis, etc. These methods help reduce the dimensionality of the data or reduce the number of variables while preserving the variance of the data..
Apart from the methods discussed above, there are many other feature selection methods. There are also hybrid methods that use filtering and wrapping techniques.. If you want to explore more about feature selection techniques, in my opinion, an excellent comprehensive reading material would be ‘Selection of functions for pattern and data recognition«See Urszula Stańczyk y Lakhmi C.. Jain.
References
Document called 'Efficient Feature Selection Filters for High-Dimensional Data’ by Artur J. Ferreira, Mario AT Figueiredo [1]
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html%20%5b2%5d [2]





