Data is generated in large quantities everywhere. Twitter generates more than 12 TB of data every day, Facebook generates more than 25 TB of data every day and Google generates much more than these amounts every day. Since this data is produced every day, we need to create tools to handle data with a high
1. Volume : Nowadays, large volumes of data are stored for any industry. Conventional models with such large data are not feasible.
2. Speed : Data arrives at high speed and requires faster learning algorithms.
3. Variety : Different data sources have different structures. All these data contribute to the prognosis. A good algorithm can absorb such a variety of data.
A simple predictive algorithm like Random Forest in about 50 thousand data points and 100 dimensions takes 10 minutes to run on a machine 12 GB of RAM. Problems with hundreds of millions of observations are simply impossible to solve with these types of machines.. Therefore, we only have two options: use a stronger machine or change the way a predictive algorithm works. The first option is not always viable. In this post, we will learn about online learning algorithms that are meant to handle data with such high volume and speed with limited throughput machines.
How is online learning different from batch learning algorithms?
Si es un principiante en la industria de la analyticsAnalytics refers to the process of collecting, Measure and analyze data to gain valuable insights that facilitate decision-making. In various fields, like business, Health and sport, Analytics Can Identify Patterns and Trends, Optimize processes and improve results. The use of advanced tools and statistical techniques is essential to transform data into applicable and strategic knowledge...., everything you've probably heard of will fall under the category of batch learning. Let's try to visualize how the operation of the two differs..
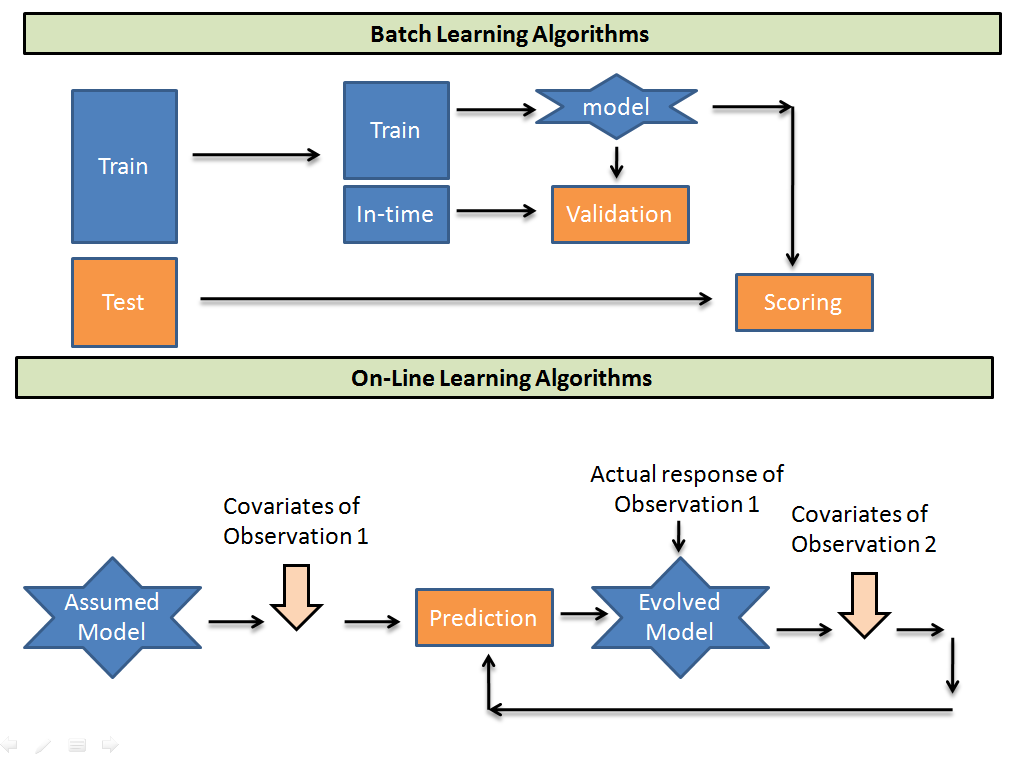
Los algoritmos de aprendizaje por lotes toman lotes de datos de trainingTraining is a systematic process designed to improve skills, physical knowledge or abilities. It is applied in various areas, like sport, Education and professional development. An effective training program includes goal planning, regular practice and evaluation of progress. Adaptation to individual needs and motivation are key factors in achieving successful and sustainable results in any discipline.... para entrenar un modelo. Then predict the test sample using the binding found. Considering that, online learning algorithms take an initial guess model and then take the one-to-one observation of the training population and recalibrate the weights on each input parameter. Here are some tradeoffs when using the two algorithms.
- Computationally much faster and more space efficient. in the online model, you are enabled to perform exactly one pass of your data, so these algorithms are generally much faster than their batch learning equivalents, since most batch learning algorithms are multi-pass. At the same time, since you can't reconsider your previous examples, regularly does not store them to enter later in the learning procedure, meaning it tends to use a smaller memory footprint.
- It is usually easier to implement. Since the online model makes one go over the data, we end up processing an example at the same time, sequentially, a measureThe "measure" it is a fundamental concept in various disciplines, which refers to the process of quantifying characteristics or magnitudes of objects, phenomena or situations. In mathematics, Used to determine lengths, Areas and volumes, while in social sciences it can refer to the evaluation of qualitative and quantitative variables. Measurement accuracy is crucial to obtain reliable and valid results in any research or practical application.... que ingresan desde el flujo. This generally simplifies the algorithm., if you do it from scratch.
- Harder to keep in production. Deploying algorithms online in production generally requires you to have something that constantly passes data points to your algorithm. If your data changes and your function selectors no longer produce useful results, or if there is significant network latency between the servers of your feature selectors, or one of those servers stops working, or actually, any number of other things, your apprentice accumulates and your output is garbage. Making sure all of this is working properly can be a test.
- Harder to examine online. in online learning, we can not offer a set of “tests” for evaluation because we do not make distribution assumptions; if we choose a set to examine, we would be assuming that the set of tests is representative of the data that we are operating, and that is a distributive assumption. Given the, in the most general case, there is no way to obtain a representative set that characterizes your data, your only option (again, in the most general case) it is simply looking at how well the algorithm has been performing recently.
- As usual, it's harder to do “good”. As we saw in the last point, online student assessment is difficult. For similar reasons, it can be very difficult to get the algorithm to behave “correctly” automatically. It can be difficult to diagnose if your algorithm or infrastructure is misbehaving.
In cases where we work with large amounts of data, we have no choice but to use online learning algorithms. The only other alternative is to perform batch learning on a smaller sample.
Example case to know the concept
We want to predict the probability of rain today. Contamos con un panelA panel is a group of experts that meets to discuss and analyze a specific topic. These forums are common at conferences, seminars and public debates, where participants share their knowledge and perspectives. Panels can address a variety of areas, from science to politics, and its objective is to encourage the exchange of ideas and critical reflection among the attendees.... of 11 people who predict class: Lluvia y no lluvia en diferentes parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project..... We need to design an algorithm to predict the probability. Let's first initialize some denotations.
I am individual predictors
w (i) is the weight given to the ith predictor
Inicial w (i) for i in [1,11] they are all 1
We will predict that it will rain today if,
Sum (w (i) for all rain predictions)> Suma (w (i) for all predictions without rain)
Una vez que tenemos la solución real de la variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... objective, now we send a feedback on the weights of all the parameters. In this circumstance we will take a very simple feedback mechanism. For each correct prediction, we will keep the same weight of the predictor. While for each incorrect prediction, we divide the weight of the predictor by 1,2 (learning rate). Over time, we expect the model to converge with a correct set of parameters. We create a simulation with 1000 predictions made by each of the 11 predictors. This is how our precision curve came out,
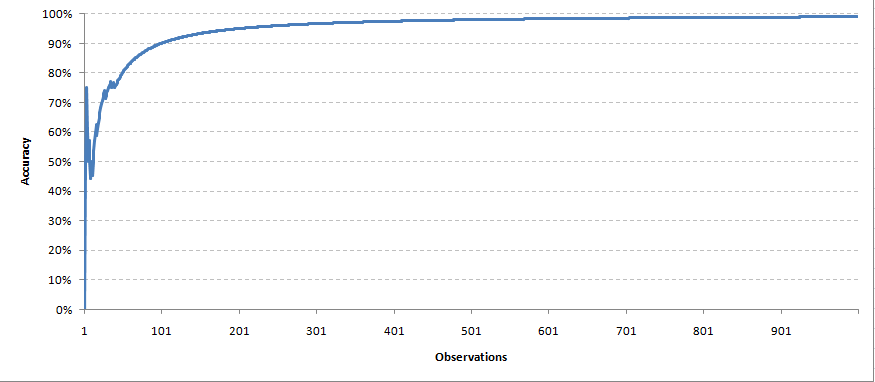
Each observation was taken at the same time to readjust the weights. In the same way, we will make predictions for future data points.
Final notes
Online learning algorithms are widely used by the e-commerce industry and social media. not only fast, but also has the ability to capture any visible new trends over time. A range of feedback systems and convergent algorithms are currently available and should be selected according to requirements.. In some of the following posts, In addition, we will take some practical examples of applications of online learning algorithms..
Was the post helpful? Have you used online learning algorithms before?? Share with us those experiences. Let us know your thoughts on this post in the box below..





