Note: This article was originally published in October 6 of, 2015 and updated the 13 September 2017
Overview
- Support vector machine explained (SVM), a popular machine learning algorithm or classification
- Implementing SVM in R and Python
- Learn about the pros and cons of Support Vector Machines (SVM) and its different applications
Introduction
Mastering machine learning algorithms not a myth at all. Most beginners start out by learning regression. It is simple to learn and use, but does that solve our purpose? Of course, no! Because you can do much more than a simple regression!!
Think of machine learning algorithms as an arsenal full of axes, swords, leaves, arcos, daggers, etc. Has various tools, but you must learn to use them at the right time. As an analogy, think of 'Regression’ like a sword capable of slicing and slicing data efficiently, but unable to handle very complex data. Conversely, ‘Support Vector Machines’ it's like a sharp knife: works on smaller data sets, but in complex sets, can be much stronger and more powerful in building machine learning models.
At this stage, I hope you have mastered Random Forest, the Naive Bayes algorithm and Ensemble modeling. But, I suggest you take a few minutes and read about them too. In this article, I'll walk you through the basics for advanced knowledge of a crucial machine learning algorithm, support vector machines.
You can get information about Support Vector Machines in course format here (It's free!):
If you are a beginner looking to start your data science journey, You have come to the right place! Check out the full courses below, selected by industry experts, that we have created just for you:

Understand the Support Vector Machine algorithm from examples (along with the code)
Table of Contents
- What is Support Vector Machine?
- How does it work?
- How to implement SVM in Python and R?
- ¿Cómo ajustar los parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project.... de SVM?
- Pros and cons associated with SVM
What is the support vector machine?
“Support Vector Machine” (SVM) is a supervised system machine learning algorithm which can be used for classification or regression challenges. But nevertheless, mainly used in classification problems. In the SVM algorithm, we plot each data item as a point in n-dimensional space (where n is a number of characteristics that has) with the value of each characteristic being the value of a particular coordinate. Later, We perform the classification by finding the hyperplane that differentiates the two classes very well (look at the snapshot below).
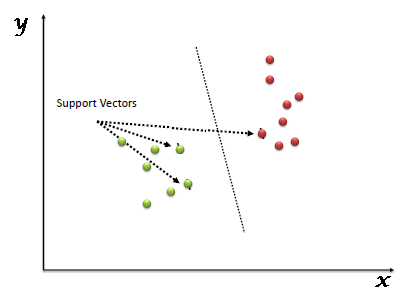
The support vectors are simply the coordinates of the individual observation. The SVM classifier is a boundary that best segregates the two classes (hyperplane / line).
You can see support vector machines and some examples of how they work here.
How does it work?
Above, we get used to the process of segregating the two classes with a hyperplane. Now the burning question is “How can we identify the correct hyperplane?”. Do not worry, it's not as difficult as you think!
We understand:
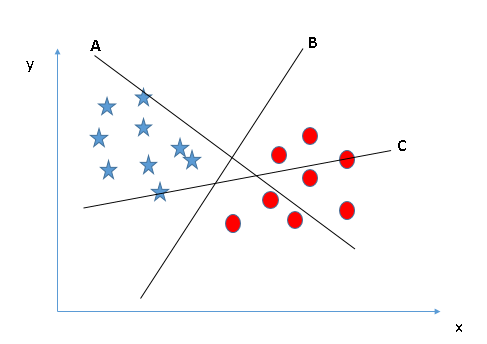
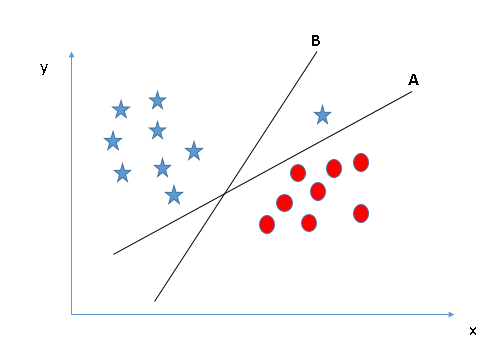
- Identify the correct hyperplane (Scenario 1): Here, we have three hyperplanes (A, B y C). Now, identify the correct hyperplane to classify stars and circles.
 You must remember a rule of thumb to identify the correct hyperplane: “Select the hyperplane that best segregates the two classes”. In this stage, the hyperplane “B” has done this job excellently.
You must remember a rule of thumb to identify the correct hyperplane: “Select the hyperplane that best segregates the two classes”. In this stage, the hyperplane “B” has done this job excellently. - Identify the correct hyperplane (Scenario-2): Here, we have three hyperplanes (A, B y C) and everyone is segregating classes well. Now, How can we identify the correct hyperplane?
 Here, maximize distances between the closest data point (any class) and the hyperplane will help us decide the correct hyperplane. This distance is called MarginMargin is a term used in a variety of contexts, such as accounting, Economics and printing. In accounting, refers to the difference between revenue and costs, which allows the profitability of a business to be evaluated. In the publishing field, The margin is the white space around the text on a page, that makes it easy to read and provides an aesthetic presentation. Its correct management is essential... Let's see the next snapshot:
Here, maximize distances between the closest data point (any class) and the hyperplane will help us decide the correct hyperplane. This distance is called MarginMargin is a term used in a variety of contexts, such as accounting, Economics and printing. In accounting, refers to the difference between revenue and costs, which allows the profitability of a business to be evaluated. In the publishing field, The margin is the white space around the text on a page, that makes it easy to read and provides an aesthetic presentation. Its correct management is essential... Let's see the next snapshot:
Above, you can see the margin for hyperplane C is high compared to A and B. Therefore, we name the right hyperplane C. Another blunt reason for selecting the hyperplane with a higher margin is robustness. If we select a hyperplane that has a low margin, there is a great chance of misclassification. - Identify the correct hyperplane (Scenario-3):Innuendo: Use the rulers as discussed in the previous section to identify the correct hyperplane
 You must remember a rule of thumb to identify the correct hyperplane: “Select the hyperplane that best segregates the two classes”. In this stage, the hyperplane “B” has done this job excellently.
You must remember a rule of thumb to identify the correct hyperplane: “Select the hyperplane that best segregates the two classes”. In this stage, the hyperplane “B” has done this job excellently.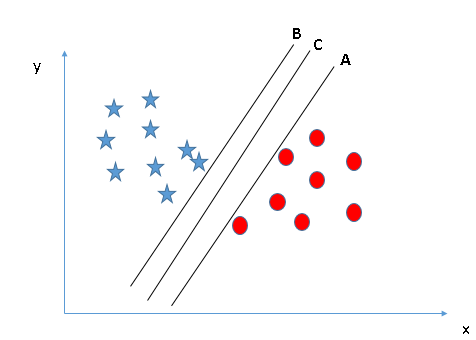 Here, maximize distances between the closest data point (any class) and the hyperplane will help us decide the correct hyperplane. This distance is called
Here, maximize distances between the closest data point (any class) and the hyperplane will help us decide the correct hyperplane. This distance is called 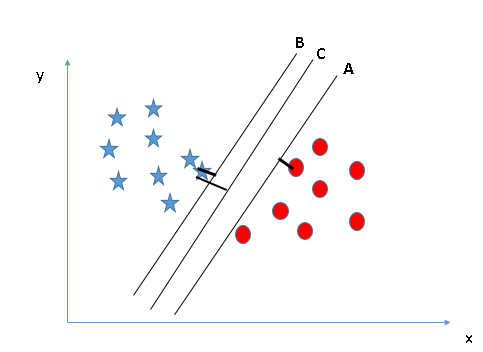
 Some of you may have selected the hyperplane B as it has a higher margin compared to A. But, here's the catch, SVM selects the hyperplane that accurately classifies classes before maximizing margin. Here, hyperplane B has a classification error and A has classified everything correctly. Therefore, the right hyperplane is A.
Some of you may have selected the hyperplane B as it has a higher margin compared to A. But, here's the catch, SVM selects the hyperplane that accurately classifies classes before maximizing margin. Here, hyperplane B has a classification error and A has classified everything correctly. Therefore, the right hyperplane is A.
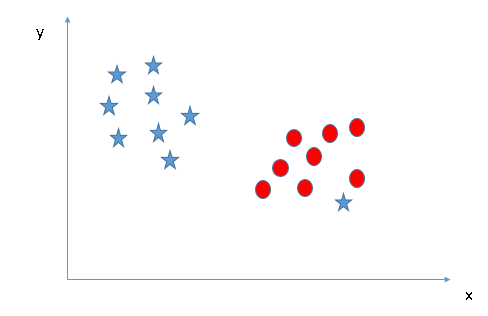
- Can we classify two classes (Scenario-4) ?: Then, I cannot segregate the two classes using a straight line, since one of the stars is in the territory of the other class (circle) as an outlier.
 As i already mentioned, a star at the other end is like an outlier for the class of stars. The SVM algorithm has a function to ignore outliers and find the hyperplane that has the maximum margin. Therefore, we can say that the SVM classification is robust to outliers.
As i already mentioned, a star at the other end is like an outlier for the class of stars. The SVM algorithm has a function to ignore outliers and find the hyperplane that has the maximum margin. Therefore, we can say that the SVM classification is robust to outliers.
- Find the hyperplane to segregate the classes (Scenario-5): In the following scenario, we cannot have a linear hyperplane between the two classes, then, How does SVM classify these two classes? Up to now, we have only looked at the linear hyperplane.
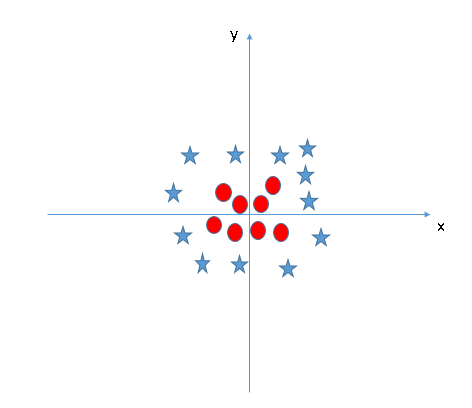
 SVM can solve this problem. Easily! Solve this problem by introducing an additional feature. Here, we will add a new feature z = x ^ 2 + and ^ 2. Now, let's plot the data points on the x and z axis:
SVM can solve this problem. Easily! Solve this problem by introducing an additional feature. Here, we will add a new feature z = x ^ 2 + and ^ 2. Now, let's plot the data points on the x and z axis:
In the graph above, the points to consider are:- All values of z would always be positive because z is the sum squared of x and y
- In the original graphic, red circles appear near the origin of the x and y axes, leading to a lower value of z and a star relatively far from the origin result to a higher value of z.
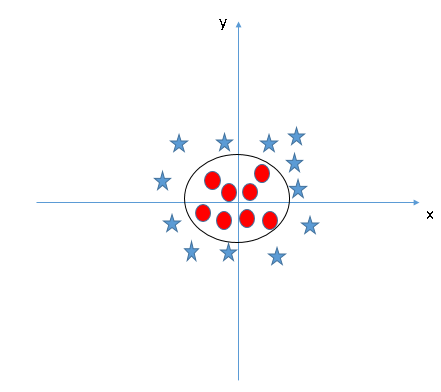
In the SVM classifier, it is easy to have a linear hyperplane between these two classes. But, another burning question that comes up is whether we need to add this function manually to have a hyperplane. No, the SVM algorithm has a technique called core trick. El kernel SVM es una función que toma un espacio de entrada de baja dimension"Dimension" It is a term that is used in various disciplines, such as physics, Mathematics and philosophy. It refers to the extent to which an object or phenomenon can be analyzed or described. In physics, for instance, there is talk of spatial and temporal dimensions, while in mathematics it can refer to the number of coordinates necessary to represent a space. Understanding it is fundamental to the study and... y lo transforma en un espacio de mayor dimensión, namely, converts a non-separable problem into a separable problem. It is especially useful in nonlinear separation problems. In a nutshell, performs some extremely complex data transformations, then discover the process to separate the data based on the labels or outputs you have defined.
When we look at the hyperplane in the original input space, looks like a circle:

 As i already mentioned, a star at the other end is like an outlier for the class of stars. The SVM algorithm has a function to ignore outliers and find the hyperplane that has the maximum margin. Therefore, we can say that the SVM classification is robust to outliers.
As i already mentioned, a star at the other end is like an outlier for the class of stars. The SVM algorithm has a function to ignore outliers and find the hyperplane that has the maximum margin. Therefore, we can say that the SVM classification is robust to outliers.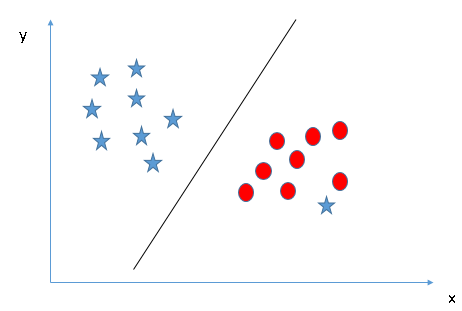
 SVM can solve this problem. Easily! Solve this problem by introducing an additional feature. Here, we will add a new feature z = x ^ 2 + and ^ 2. Now, let's plot the data points on the x and z axis:
SVM can solve this problem. Easily! Solve this problem by introducing an additional feature. Here, we will add a new feature z = x ^ 2 + and ^ 2. Now, let's plot the data points on the x and z axis: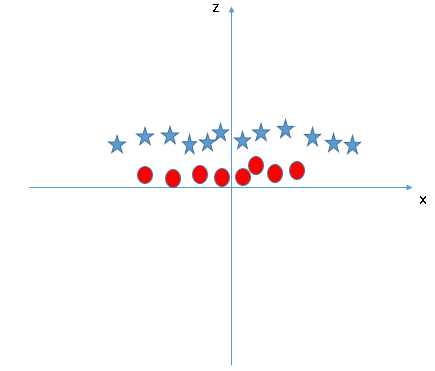
Now, Let's see the methods to apply the SVM classifier algorithm in a data science challenge.
You can also learn about the operation of Support Vector Machine in video format from this Machine learning certification.
How to implement SVM in Python and R?
In Python, scikit-learn is a widely used library for implementing machine learning algorithms. SVM is also available in the scikit-learn library and we follow the same structure to use it (import library, object creation, fit and prediction model).
Now, Let's take a look at a real life problem statement and dataset to understand how to apply SVM for classification.
Problem Statement
The Dream Housing Finance company takes care of all mortgage loans. They have a presence in all urban areas, semi-urban and rural. A customer first applies for a home loan, after the company validates the client's eligibility for a loan.
The business wants to automate the loan eligibility process (in real time) based on customer details provided when completing an online application form. These details are gender, marital status, education, number of dependents, income, loan amount, credit history and others. To automate this process, have given a problem to identify customer segments, who are eligible for the loan amount so that they can specifically target these clients. Here they have provided a partial data set.
Use the coding window below to predict loan eligibility in the test set. Try changing the hyperparameters of Linear SVM to improve accuracy.
Vector machine code support (SVM) an R
The e1071 package in R is used to create support vector machines with ease. Has auxiliary functions, as well as code for the Naive Bayes Classifier. Creating a support vector machine in R and Python follows similar approaches, let's now take a look at the following code:
#Import Library require(e1071) #Contains the SVM Train <- read.csv(file.choose()) Test <- read.csv(file.choose()) # there are various options associated with SVM training; like changing kernel, gamma and C value. # create model model <- svm(Target~Predictor1+Predictor2+Predictor3,data=Train,kernel="linear",gamma=0.2,cost=100) #Predict Output preds <- predict(model,Test) table(preds)
How to adjust SVM parameters?
Tuning parameter values for machine learning algorithms effectively improves model performance. Let's see the list of parameters available with SVM.
sklearn.svm.SVC(C=1.0, kernel="rbf", degree=3, gamma=0.0, coef0=0.0, shrinking=True, probability=False,toll=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, random_state=None)
I am going to discuss about some important parameters that have a major impact on the performance of the model., “kernel”, “gamma” Y “C”.
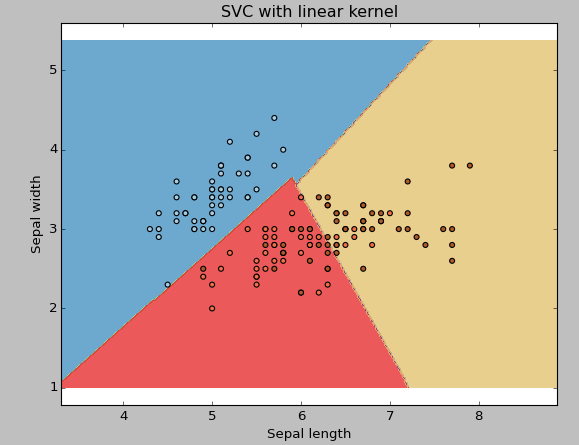
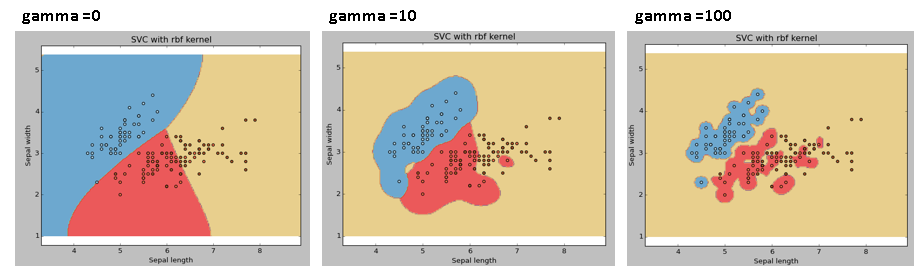
core: We have already discussed it. Here, we have several options available with kernel like, “linear”, “rbf”, “poly” and others (the default is “rbf”). Here “rbf” Y “poly” are useful for nonlinear hyperplanes. Let's see the example, where we have used linear kernel on two features of the iris dataset to classify their class.
Supports vector machine code (SVM) and Python
Example: Have a linear SVM kernel
import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets
# import some data to play with iris = datasets.load_iris() X = iris.data[:, :2] # we only take the first two features. We could # avoid this ugly slicing by using a two-dim dataset y = iris.target
# we create an instance of SVM and fit out data. We do not scale our # data since we want to plot the support vectors C = 1.0 # SVM regularization parameter svc = svm.SVC(kernel="linear", C=1,gamma=0).fit(X, Y)
# create a mesh to plot in x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 h = (x_max / x_min)/100 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1) Z = svc.predict(NPC_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.contourf(xx, yy, WITH, cmap=plt.cm.Paired, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
plt.show()
Example: Use the SVM rbf kernel
Change the kernel type to rbf in the line below and watch the impact.
svc = svm.SVC(kernel="rbf", C=1,gamma=0).fit(X, Y)
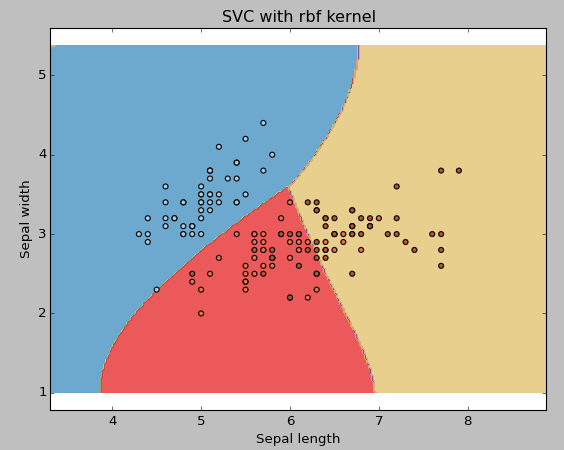
I suggest you go for the linear SVM kernel if you have a lot of features (> 1000) because the data is more likely to be linearly separable in a high-dimensional space. What's more, you can use RBF, but don't forget to cross-validate your parameters to avoid over-tuning.
range: Kernel coefficient for ‘rbf’, ‘Poli’ and 'sigmoid'. The higher the gamma value, se intentará ajustar con exactitud el conjunto de datos de trainingTraining is a systematic process designed to improve skills, physical knowledge or abilities. It is applied in various areas, like sport, Education and professional development. An effective training program includes goal planning, regular practice and evaluation of progress. Adaptation to individual needs and motivation are key factors in achieving successful and sustainable results in any discipline...., namely, the generalization error and will cause an overfitting problem.
Example: We are going to differentiate if we have different gamma values like 0, 10 O 100.
svc = svm.SVC(kernel="rbf", C=1,gamma=0).fit(X, Y)
C: Penalty parameter C of the error term. It also controls the trade-off between soft decision limits and correct classification of training points..
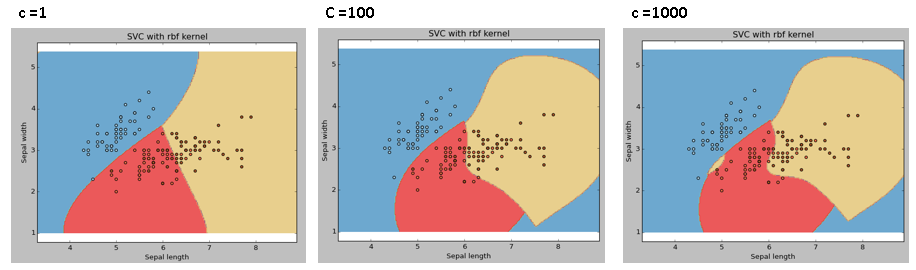
We should always look at the cross-validation score to have an effective combination of these parameters and avoid overfitting.
An R, SVMs can be adjusted similar to how they are in Python. Below mentioned are the respective parameters for the e1071 package:
- The kernel parameter can be adjusted to take “Linear”, “Poly”, “rbf”, etc.
- The gamma value can be adjusted by setting the parameter “Gamma”.
- The C value in Python is set by the parameter “Cost” an R.
Pros and cons associated with SVM
- Pros:
- Works great with a clear gap.
- It is effective in large spaces.
- It is effective in cases where the number of dimensions is greater than the number of samples.
- Use a subset of training points in the decision function (called support vectors), so it is also memory efficient.
- Cons:
- It does not work well when we have a large data set because the training time required is longer
- It also doesn't work very well when the dataset has more noise, namely, target classes overlap
- SVM does not directly provide probability estimates, these are calculated using a costly five-time cross-validation. It is included in the related SVC method of Python's scikit-learn library.
Practice problem
Find the suitable additional feature to have a hyperplane to segregate the classes in the following snapshot:
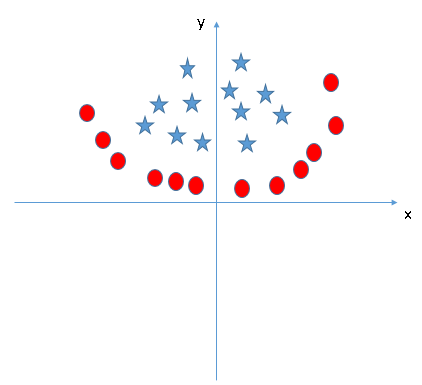
Responda el nombre de la variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... en la sección de comentarios a continuación. Then I will reveal the answer.
Final notes
In this article, we analyze in detail the machine learning algorithm, Support Vector Machine. I spoke about his concept of work, the implementation process in python, the tricks to make the model efficient by adjusting its parameters, Pros and cons, and finally a problem to solve. I suggest you use SVM and analyze the power of this model by adjusting the parameters. I also want to hear about your experience with SVM, How have you adjusted the parameters to avoid over-adjustment and reduce training time?
Do you find helpful this article? Share your opinions / thoughts in the comment section below.





