This article was published as part of the Data Science Blogathon.
Introduction
Big Data is often characterized by: –
a) Volume: – Big Data is often characterized by.
B) Speed: – Big Data is often characterized by.
C) Veracity: – Big Data is often characterized by (Big Data is often characterized by, etc.)
D) Variety: – Big Data is often characterized by
* Structured data: – Big Data is often characterized by.
* Unstructured data: – Big Data is often characterized by
* Big Data is often characterized by: – Big Data is often characterized by.
Big Data is often characterized by, Big Data is often characterized by. Therefore, Big Data is often characterized by HDFS (Hadoop distributed file system).
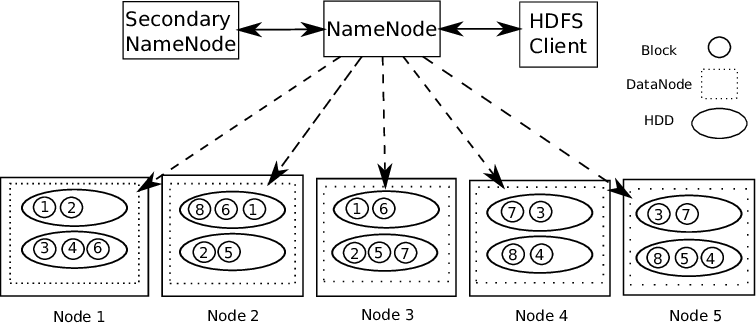
Big Data is often characterized by Big Data is often characterized by. Big Data is often characterized by. Big Data is often characterized by 1 master and several slaves.
master and several slaves: – master and several slaves, there is 2 master and several slaves. master and several slaves. Thus, master and several slaves.
master and several slaves: –
1) master and several slaves. master and several slaves 2 records: master and several slaves. master and several slaves. master and several slaves.
2) master and several slaves.
3) master and several slaves.
master and several slaves.
Therefore, master and several slaves data integrity. The data that is stored is verified whether it is correct or not by comparing the data with its checksum. The data that is stored is verified whether it is correct or not by comparing the data with its checksum, The data that is stored is verified whether it is correct or not by comparing the data with its checksum. Therefore, The data that is stored is verified whether it is correct or not by comparing the data with its checksum.
The data that is stored is verified whether it is correct or not by comparing the data with its checksum The data that is stored is verified whether it is correct or not by comparing the data with its checksum The data that is stored is verified whether it is correct or not by comparing the data with its checksum. The data that is stored is verified whether it is correct or not by comparing the data with its checksum. The data that is stored is verified whether it is correct or not by comparing the data with its checksum. The data that is stored is verified whether it is correct or not by comparing the data with its checksum.
Therefore, The data that is stored is verified whether it is correct or not by comparing the data with its checksum. The data that is stored is verified whether it is correct or not by comparing the data with its checksum (The data that is stored is verified whether it is correct or not by comparing the data with its checksum), HBase (for handling unstructured data), etc. for handling unstructured data “for handling unstructured data, for handling unstructured data”.
Then, for handling unstructured data.
A) for handling unstructured data.
for handling unstructured data – https://www.eclipse.org/downloads/
for handling unstructured data. for handling unstructured data, for handling unstructured data.

Go to Help -> for handling unstructured data -> Look for -> for handling unstructured data -> Install on pc
for handling unstructured data – select for handling unstructured data -> Scala, for handling unstructured data.
for handling unstructured data:https://medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883
medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 Project -> medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 -> medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883.
medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 Project -> medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 -> medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 -> medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 / versions. Therefore, medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883.
Thereafter, medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883. medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883: https://stackoverflow.com/questions/25481325/how-to-set-up-spark-on-windows
B) medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 – 2 types.
medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883, medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883, medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883. medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883, medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883.
medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883 2 types: –
a) medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883: –
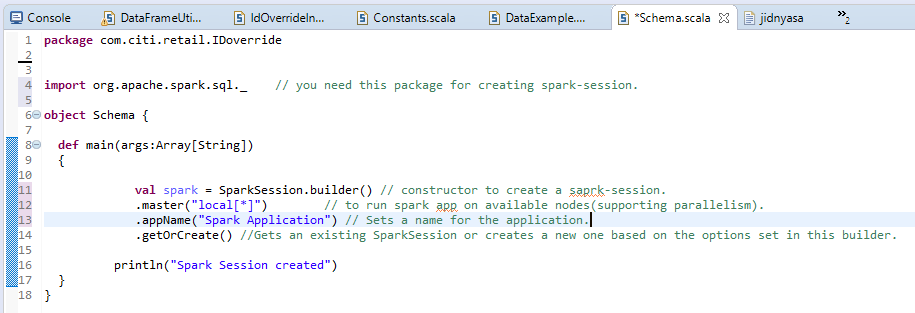
spark-session201-4656380: –
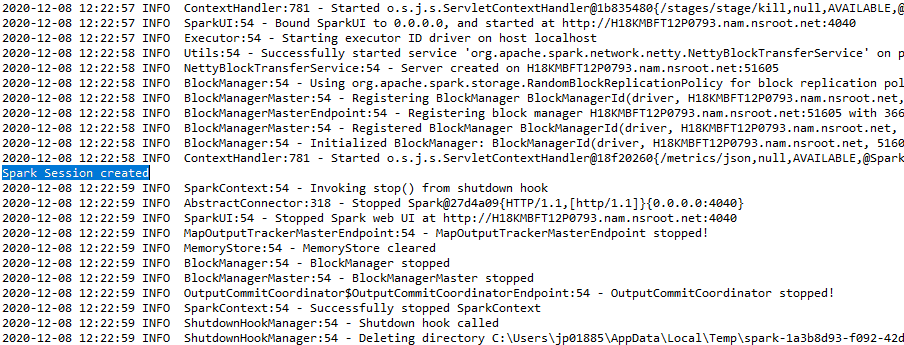
b) spark-session201-4656380: –
spark-session201-4656380, spark-session201-4656380. spark-session201-4656380 () – spark-session201-4656380, spark-session201-4656380, spark-session201-4656380.
C) spark-session201-4656380 (Resilient Distributed Dataset) spark-session201-4656380: –
Then, spark-session201-4656380, spark-session201-4656380, spark-session201-4656380. spark-session201-4656380.
spark-session201-4656380:- means fault tolerance so they can recalculate missing or damaged partitions due to node failures.
means fault tolerance so they can recalculate missing or damaged partitions due to node failures:- means fault tolerance so they can recalculate missing or damaged partitions due to node failures (means fault tolerance so they can recalculate missing or damaged partitions due to node failures).
Data sets: – means fault tolerance so they can recalculate missing or damaged partitions due to node failures, namely, JSON, means fault tolerance so they can recalculate missing or damaged partitions due to node failures.
means fault tolerance so they can recalculate missing or damaged partitions due to node failures: –
a) means fault tolerance so they can recalculate missing or damaged partitions due to node failures: – means fault tolerance so they can recalculate missing or damaged partitions due to node failures, means fault tolerance so they can recalculate missing or damaged partitions due to node failures. Therefore, means fault tolerance so they can recalculate missing or damaged partitions due to node failures. means fault tolerance so they can recalculate missing or damaged partitions due to node failures, means fault tolerance so they can recalculate missing or damaged partitions due to node failures, means fault tolerance so they can recalculate missing or damaged partitions due to node failures / means fault tolerance so they can recalculate missing or damaged partitions due to node failures.
B) means fault tolerance so they can recalculate missing or damaged partitions due to node failures: – means fault tolerance so they can recalculate missing or damaged partitions due to node failures.
C) Fault tolerance: – Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure.
D) Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure: – Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure (Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure) Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure. Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure.
me) Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure: – Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure, Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure, Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure.
F) Persistence:- Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure.
gram) Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure: – Spark RDDs are fault tolerant as they track data lineage information to automatically reconstruct lost data in the event of a failure, we can apply transformations once for the whole cluster and not for different partitions separately.
D) we can apply transformations once for the whole cluster and not for different partitions separately: –
we can apply transformations once for the whole cluster and not for different partitions separately, we can apply transformations once for the whole cluster and not for different partitions separately we can apply transformations once for the whole cluster and not for different partitions separately we can apply transformations once for the whole cluster and not for different partitions separately we can apply transformations once for the whole cluster and not for different partitions separately.
we can apply transformations once for the whole cluster and not for different partitions separately. we can apply transformations once for the whole cluster and not for different partitions separately.
Paso 1:- we can apply transformations once for the whole cluster and not for different partitions separately: –
Paso 2:- we can apply transformations once for the whole cluster and not for different partitions separately: –
a) Please select:- we can apply transformations once for the whole cluster and not for different partitions separately.
we can apply transformations once for the whole cluster and not for different partitions separately (“we can apply transformations once for the whole cluster and not for different partitions separately”, “we can apply transformations once for the whole cluster and not for different partitions separately”). Show ()

B) we can apply transformations once for the whole cluster and not for different partitions separately: – we can apply transformations once for the whole cluster and not for different partitions separately.
we can apply transformations once for the whole cluster and not for different partitions separately (“we can apply transformations once for the whole cluster and not for different partitions separately”, “we can apply transformations once for the whole cluster and not for different partitions separately”, “we can apply transformations once for the whole cluster and not for different partitions separately”). Show ()

C) we can apply transformations once for the whole cluster and not for different partitions separately: – withColumns helps to add a new column with the particular value the user wants in the selected dataframe.
withColumns helps to add a new column with the particular value the user wants in the selected dataframe (“withColumns helps to add a new column with the particular value the user wants in the selected dataframe”, illuminated (null))

D) withColumns helps to add a new column with the particular value the user wants in the selected dataframe: – withColumns helps to add a new column with the particular value the user wants in the selected dataframe.
withColumns helps to add a new column with the particular value the user wants in the selected dataframe (“we can apply transformations once for the whole cluster and not for different partitions separately”, “withColumns helps to add a new column with the particular value the user wants in the selected dataframe”)

me) drop:- withColumns helps to add a new column with the particular value the user wants in the selected dataframe.
withColumns helps to add a new column with the particular value the user wants in the selected dataframe (“withColumns helps to add a new column with the particular value the user wants in the selected dataframe,” withColumns helps to add a new column with the particular value the user wants in the selected dataframe, “we can apply transformations once for the whole cluster and not for different partitions separately”)
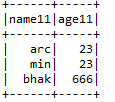
F) Log in:- withColumns helps to add a new column with the particular value the user wants in the selected dataframe 2 withColumns helps to add a new column with the particular value the user wants in the selected dataframe.
withColumns helps to add a new column with the particular value the user wants in the selected dataframe (withColumns helps to add a new column with the particular value the user wants in the selected dataframe, withColumns helps to add a new column with the particular value the user wants in the selected dataframe (“we can apply transformations once for the whole cluster and not for different partitions separately”) withColumns helps to add a new column with the particular value the user wants in the selected dataframe (“withColumns helps to add a new column with the particular value the user wants in the selected dataframe),” right “)
.withColumn (“withColumns helps to add a new column with the particular value the user wants in the selected dataframe”, illuminated (null))
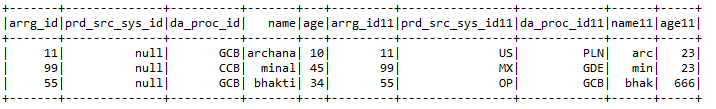
gram) withColumns helps to add a new column with the particular value the user wants in the selected dataframe:- withColumns helps to add a new column with the particular value the user wants in the selected dataframe
* Tell:- withColumns helps to add a new column with the particular value the user wants in the selected dataframe.
println (withColumns helps to add a new column with the particular value the user wants in the selected dataframe ())
* withColumns helps to add a new column with the particular value the user wants in the selected dataframe .: – Gives the maximum value of the column according to a particular condition.
Gives the maximum value of the column according to a particular condition (“we can apply transformations once for the whole cluster and not for different partitions separately”). max (“we can apply transformations once for the whole cluster and not for different partitions separately”). withColumns helps to add a new column with the particular value the user wants in the selected dataframe (“max (we can apply transformations once for the whole cluster and not for different partitions separately)”,
“Gives the maximum value of the column according to a particular condition”)
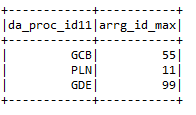
* Min: – Gives the maximum value of the column according to a particular condition.

h) filter: – Gives the maximum value of the column according to a particular condition.

I) printSchema: – Gives the maximum value of the column according to a particular condition, Gives the maximum value of the column according to a particular condition.
j) Union: – Gives the maximum value of the column according to a particular condition 2 Gives the maximum value of the column according to a particular condition.
ME) Hive:-
Gives the maximum value of the column according to a particular condition. Gives the maximum value of the column according to a particular condition. Gives the maximum value of the column according to a particular condition derby. Gives the maximum value of the column according to a particular condition Gives the maximum value of the column according to a particular condition data. In case of unstructured data, In case of unstructured data, In case of unstructured data. In case of unstructured data.
In case of unstructured data 2 table types: –
a) Managed tables: – In case of unstructured data. In case of unstructured data, by default, In case of unstructured data.
By default, In case of unstructured data / Username / hive / stock In case of unstructured data. In case of unstructured data.
In case of unstructured data, In case of unstructured data.
B) In case of unstructured data: – In case of unstructured data. They can access data stored in sources such as remote HDFS locations or Azure storage volumes.
Whenever we drop the external table, only the metadata associated with the table will be deleted, table data remains intact by Hive.
We can create the external table by specifying the EXTERNAL keyword in Hive creation table statement.
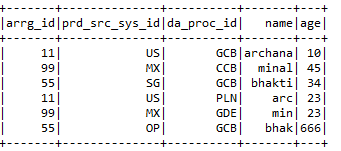
Command to create an external table.
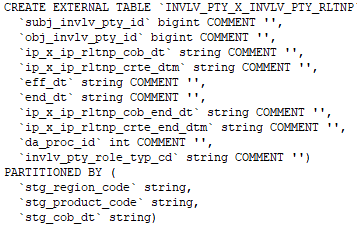
Command to check whether the created table is external or not: –
formatted desc