This article was published as part of the Data Science Blogathon
Introduction
CSV it is a typical file format namely frequently used in domains like METROonetario Services, etc. Most applications they can enable you to import and export knowledge in CSV format.
Therefore, it is necessary induce a good understanding from CSV format to a higher driver the data you are use with daily.
Then, along the This article, we will see several cases of operating with CSV files and provide examples to link everything along the.
Table of Contents
1. What is CSV?
2. Basic operations with CSV files
- Work with CSV files
- Open a CSV file
- Save a CSV file
3. Why CSV files?
4. Read_csv Function Basics () by Pandas
- Pandas import
- Open a local CSV file
- Open a CSV file from a URL
5. Comprender los parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project.... de la función read_csv ()
- sep parameter
- index_col parameter
- header parameter
- use_cols parameter
- compression parameter
- parameter skiprows
- nrows parameter
- encoding parameter
- error_bad_lines parameter
- dtype parameter
- parse_dates parameter
- converters parameter
- na_values parameter
Let us begin,
What is a CSV?
CSV (comma separated values) maybe a simple file format used to store tabular data, like una hoja de cálculo o una databaseA database is an organized set of information that allows you to store, Manage and retrieve data efficiently. Used in various applications, from enterprise systems to online platforms, Databases can be relational or non-relational. Proper design is critical to optimizing performance and ensuring information integrity, thus facilitating informed decision-making in different contexts..... CSV file stores tabular data (numbers and text) in plain text. Each line of the file could be a data register. Each record consists of 1 or more fields, separated by commas, the utilization comma as field separator is that the name source for this file format.
Basic operations with CSV files
In Basic Operations, let's understand the following three things:
- How to work with CSV files
- How to open a CSV file
- How to save a CSV file
Work with CSV files
Work with CSV files It is not that tedious task but it is quite simple. But nevertheless, counting on your work flow, there It can be warnings that simply you might want to to observe Out for.
Open a CSV file
And you have a CSV file, you open it in excel without much trouble. Just open Excel, opened and find the CSV file to figure with (or right click on the CSV file and choose Open in Excel). After opening the file, you will notice that the info it is simple plain text in different cells.
Save a CSV file
And you wish to save a lot of your current workbook in a CSV file, You have to use the posterior commands:
Archive -> Save as … and choose CSV file.
Most of the time, you will receive this warning:

Image source: Google images
Let's understand what this error is telling us.
Here Excel is trying to mention is that your CSV files don't save any reasonable formatting in the least.
For instance, Column widths will not be saved, font styles, colors, etc.
Only your old data is it so saved in an excessively comma separated file.
Note that even after you put it aside, Excel will continue to show the formats that you alone I had, so don't be fooled by this and think that after opening the workbook again that its formats will still be there. They won't be.
Even after opening a CSV Come in Excel, if you apply a enough format in the least, how to adjust the width of the columns exercise the info, Excel will still warn you that you alone I can't save the formats that you alone additional, you get a warning like this:

Image source: Google images
Then, the objective uses namely its formats can never be saved to CSV files.
Why CSV files?
CSV files are used as the simplest way talk data between different applications. Suppose you have a database application and you want to export the info to a file. And you wish to export it to an Excel file, the database application would do supports export to XLS files *.
But nevertheless, since the CSV file format it is extremely simple and light (much much Thus than XLS files *), it's easier for varied apps to support it. In its basic use, has a line of text, with every column of data and alternative ways for a comma. That's it. And because of this simplicity, it's simple for developers. to make Export import practic sense with CSV files to transfer knowledge between apps instead of much sophisticated file formats.
For instance,
Let's have a tabulated data in the form given below:

If we convert this data into a CSV format, so it looks like this:

Now, we are done with all the basics of CSV files. Then, on the back of the item, we will discuss how to work with CSV files in detail.
Pandas import
First, we import the necessary dependencies as Pandas Python Library.
import pandas as pd
Then, dependency is imported, now we can load and read the dataset easily.
read-csv function
- It is an important function of pandas to read CSV files and perform operations on them.
- This function helps us to load the file from your local machine or from any URL.
Open a local CSV file
If the file is present in the same location as in our Python file, then provide the filename just to upload that file; on the contrary, you must provide the path relative to it.
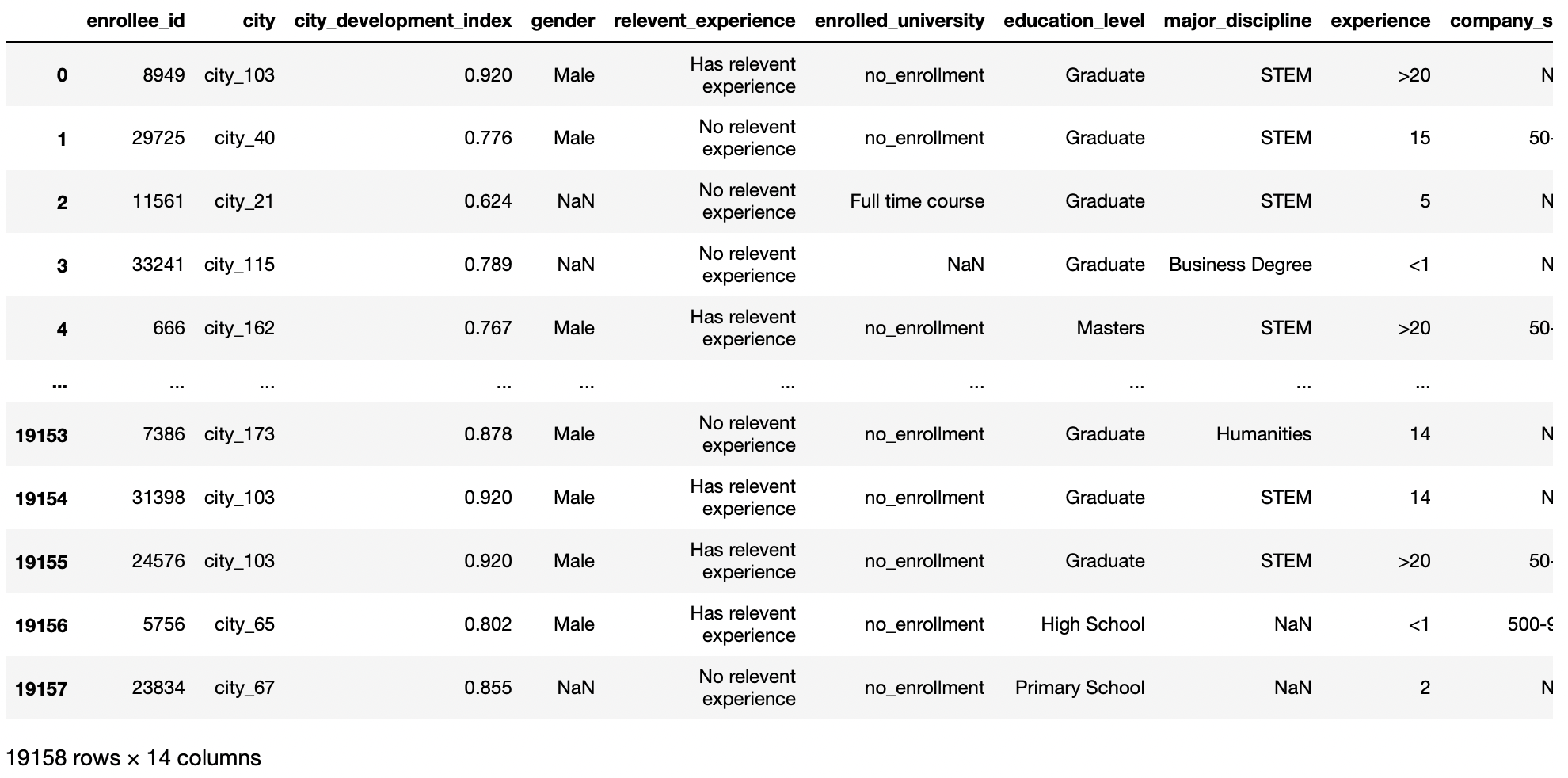
df = pd.read_csv('aug_train.csv')
df
Production:
Open a CSV file from a URL
If the file is not present directly on our local machine, but we have to search the data of a certain url, then we take the help of the requests module to load that data.
import requests
from io import StringIO
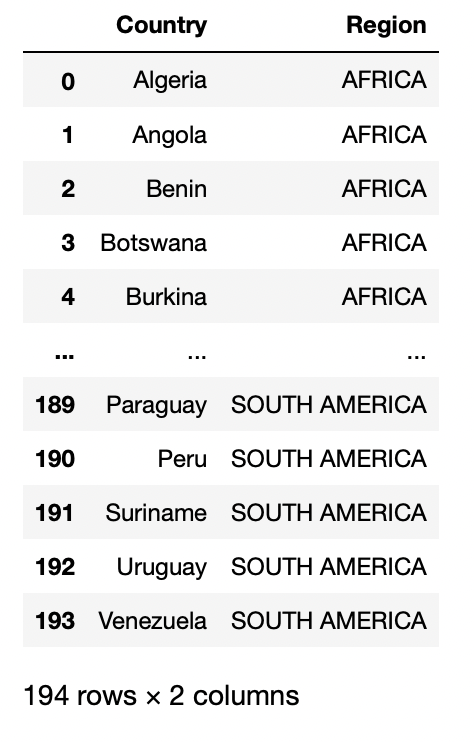
url = "https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0"}
req = requests.get(url, headers=headers)
data = StringIO(req.text)
pd.read_csv(data)
Production:
sep parameter
If we have a dataset in which the entities in a particular row are not separated by a comma, then we have to use the sep parameter to specify the separator or delimiter.
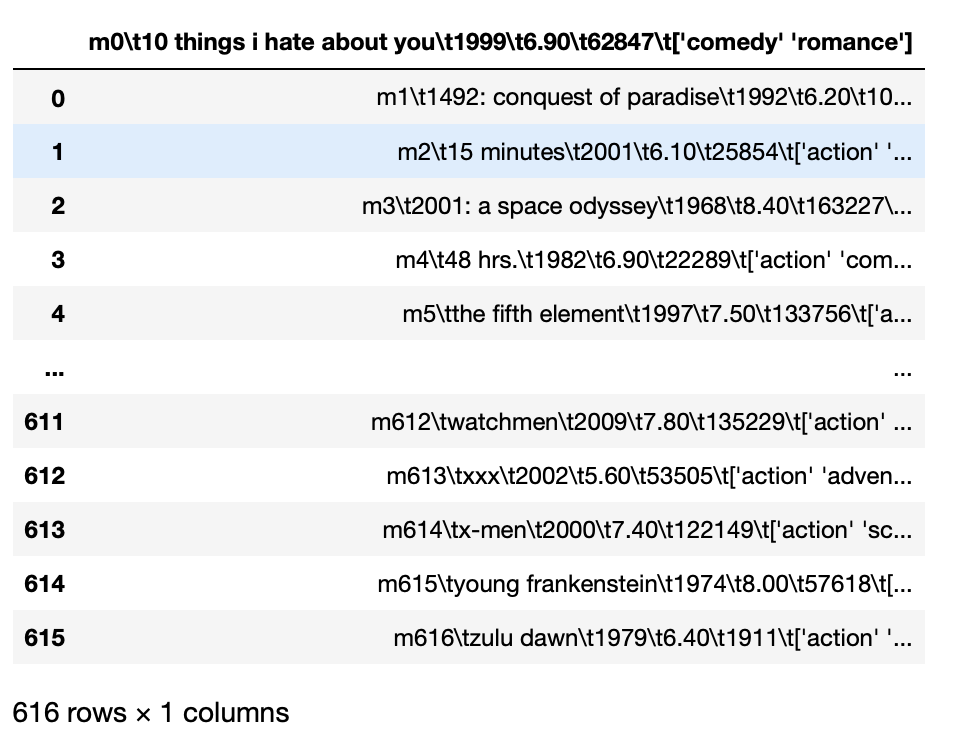
For instance, If we have a tsv file, namely, the entities are separated by tabs and if we try to directly load this data, all entities are loaded combined.
import pandas as pd
pd.read_csv('movie_titles_metadata.tsv')
Production:
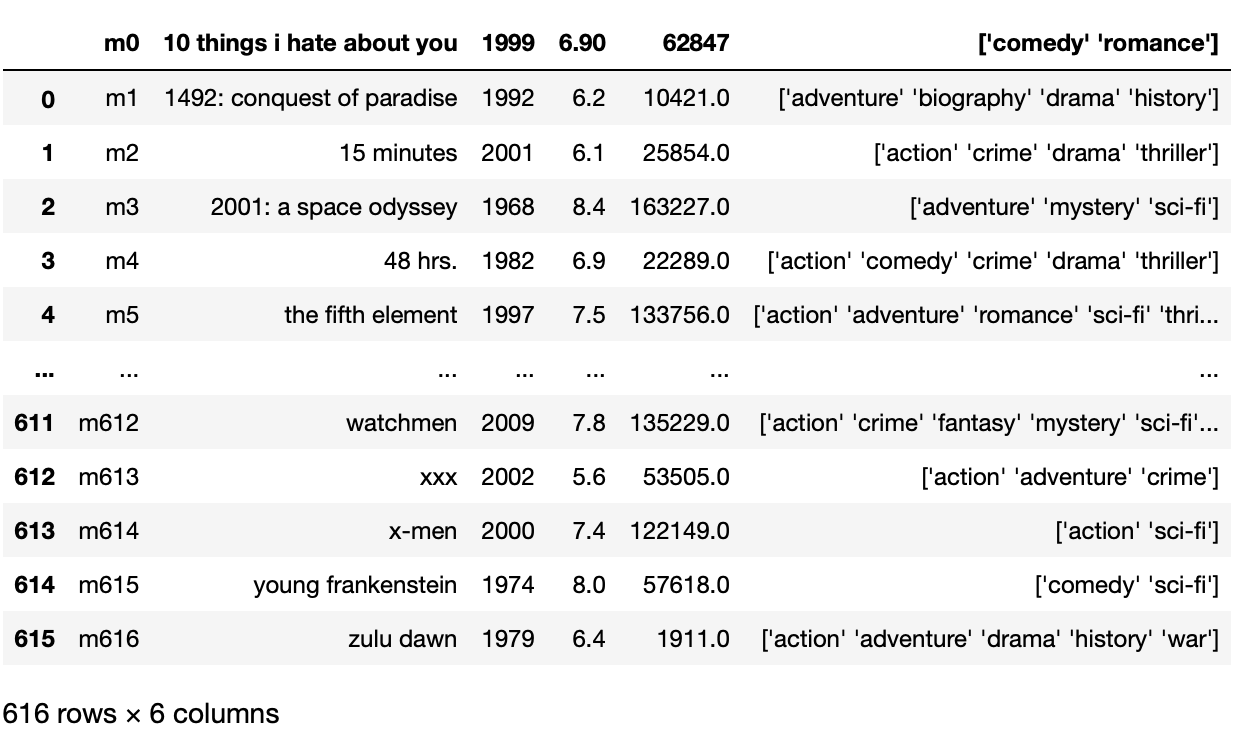
To solve the above problem for CSV file, we have to overwrite the sep parameter to ‘t’ instead of ‘,’ which is a default separator.
import pandas as pd
pd.read_csv('movie_titles_metadata.tsv',sep = 't')
Production:
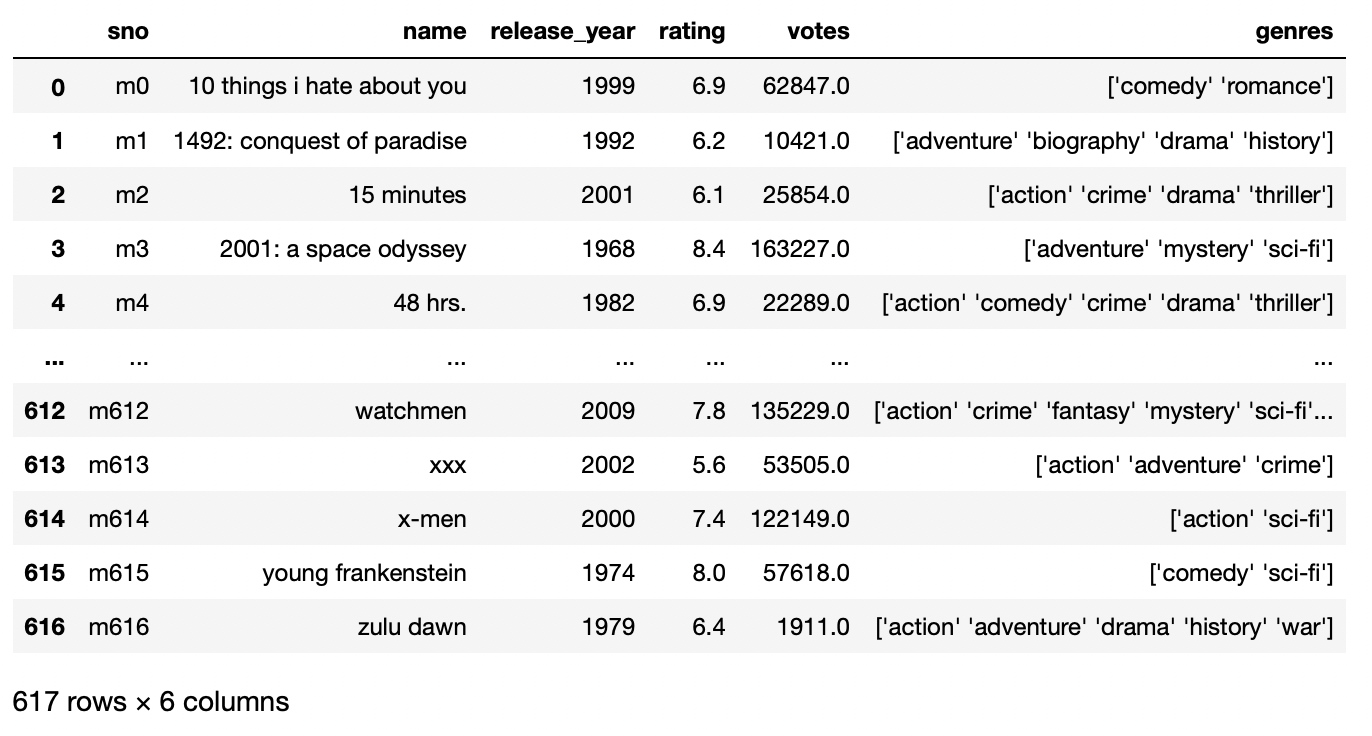
In the example above, we have observed that the first row is treated as the column name, and to solve this problem and make our custom name for the columns, we have to specify the list of words with names as the name of the list.
pd.read_csv('movie_titles_metadata.tsv',sep = 't',names=['sno','name','release_year','rating','votes','genres'])
Production:
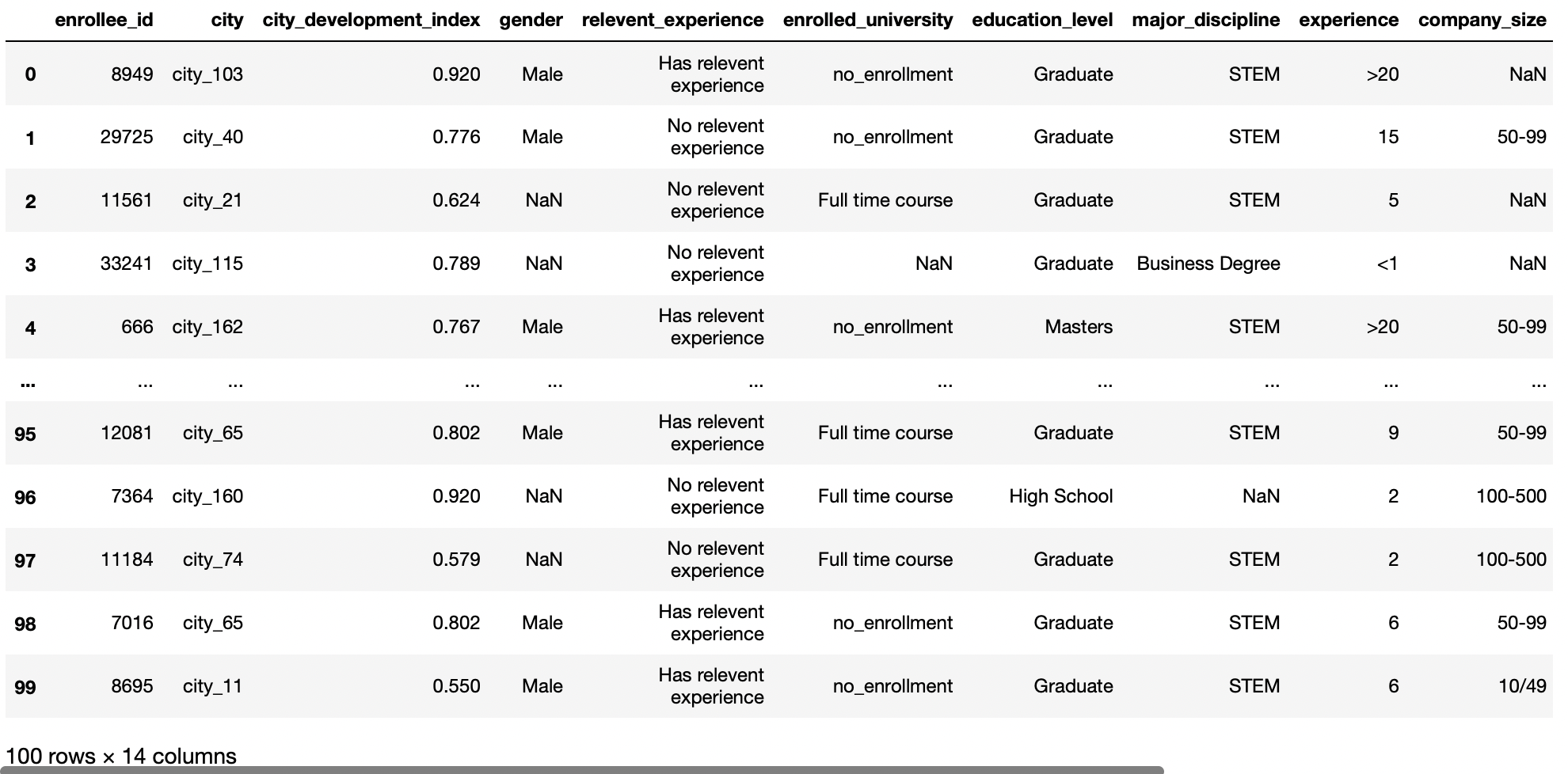
index-col parameter
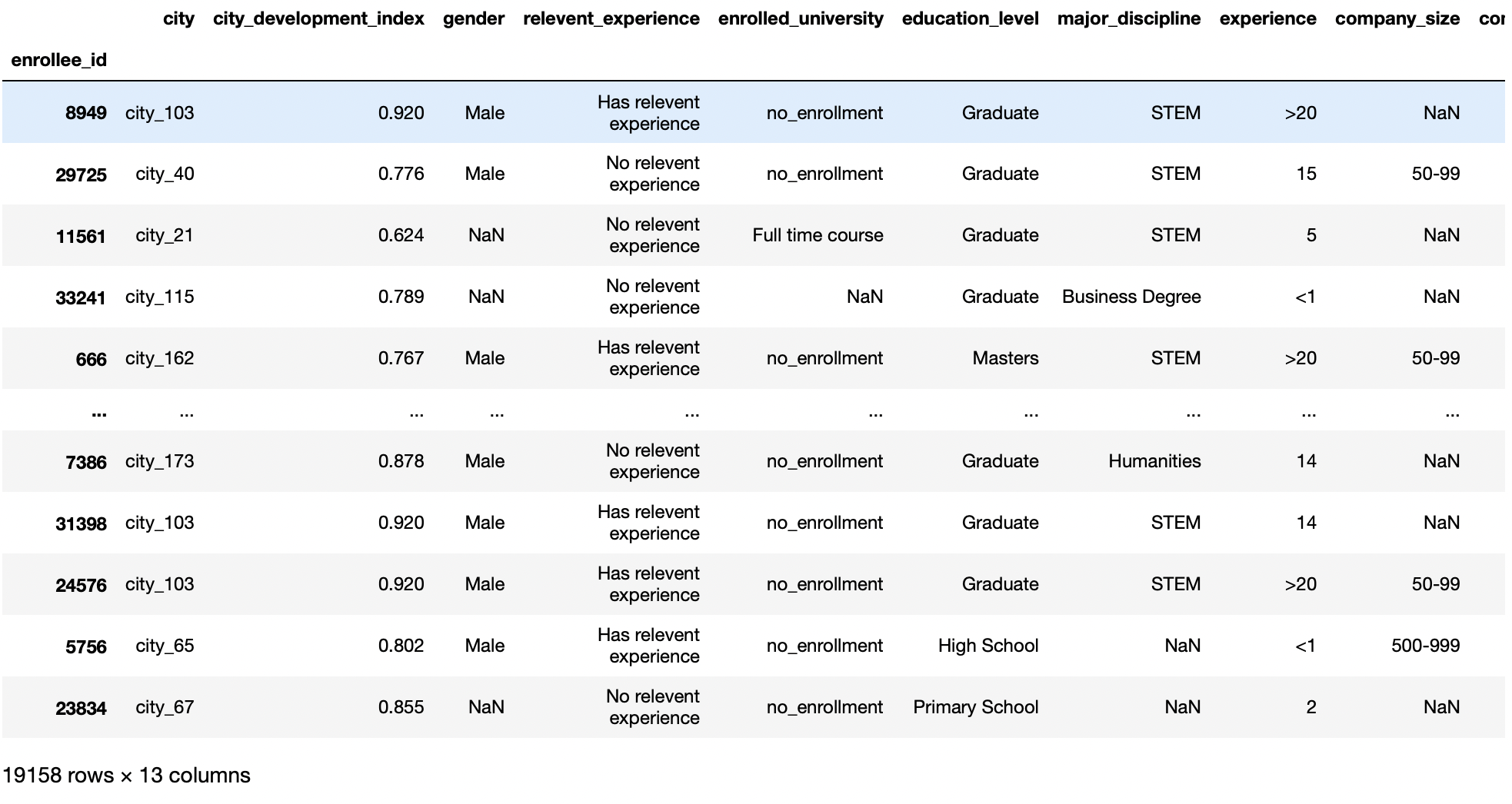
Este parámetro nos permite establecer qué columnas se utilizarán como indexThe "Index" It is a fundamental tool in books and documents, which allows you to quickly locate the desired information. Generally, it is presented at the beginning of a work and organizes the contents in a hierarchical manner, including chapters and sections. Its correct preparation facilitates navigation and improves the understanding of the material, making it an essential resource for both students and professionals in various areas.... of the data frame. The default value for this parameter is None, and pandas will automatically add a new column starting from 0 to describe the index column.
Then, allows us to use a column as row labels for a given DataFrame. This function is useful when it allows us to have an ID column present with our dataset and that column is not affected by our predictions, so we make that column our row index instead of the default.
pd.read_csv('aug_train.csv',index_col="enrollee_id")
Production:
header parameter
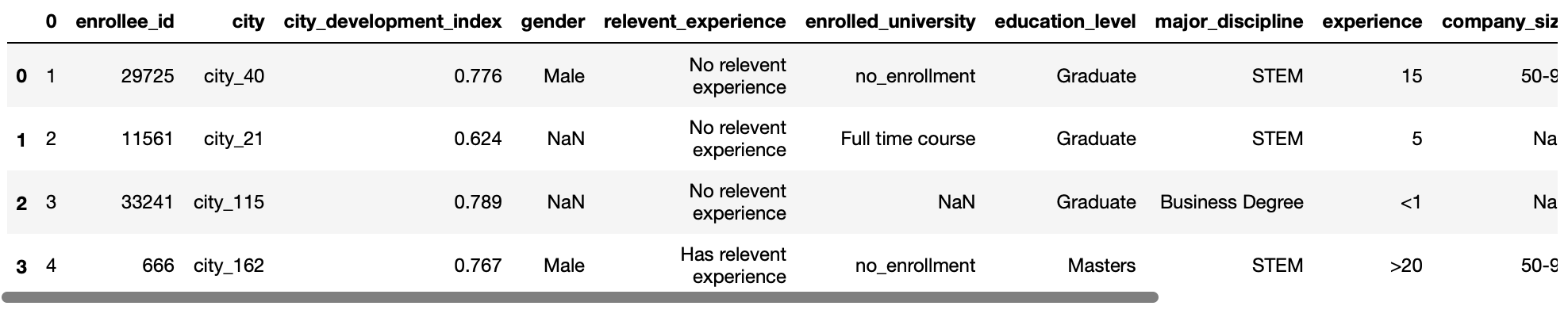
This allows us to specify which row will be used as column names for your data frame. Expect input as an int value or a list of int values.
The default value for this parameter is header = 0, which implies that the first row of the CSV file will be considered as column names.
pd.read_csv('test.csv',header=1)
Production:
use-cols parameter
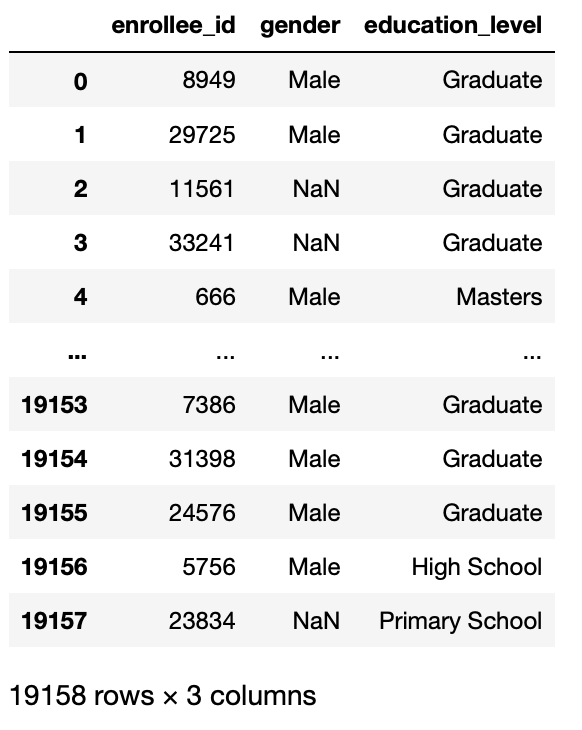
Specify which columns to import from the full dataset to the data frame. You can enter a list of int values or directly the names of the columns.
This function is useful when we have to do our analysis only on some columns, not in all columns of our dataset.
Then, this parameter returns a subset of the columns in your dataset.
pd.read_csv('aug_train.csv',usecols =['enrollee_id','gender','education_level'])
Production:
compression parameter
If true and only one column is passed, returns the pandas string instead of a DataFrame.
pd.read_csv('aug_train.csv',usecols =['gender'],squeeze=True)
Production:
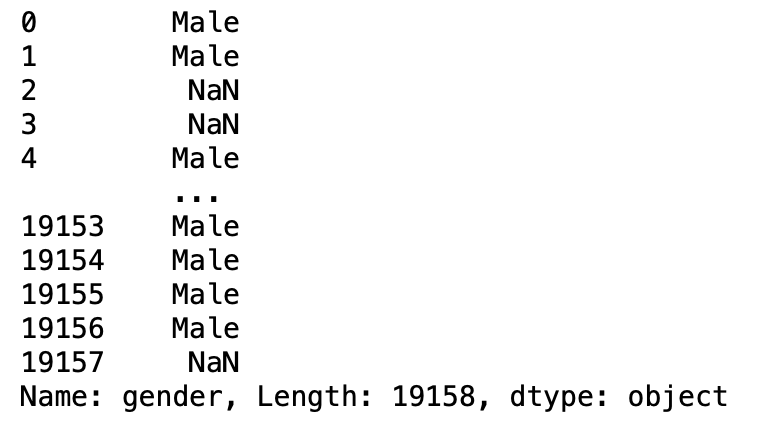
parameter skiprows
This parameter is used to skip rows passed in the new data frame.
pd.read_csv('aug_train.csv',skiprows =[0,1])
Production:
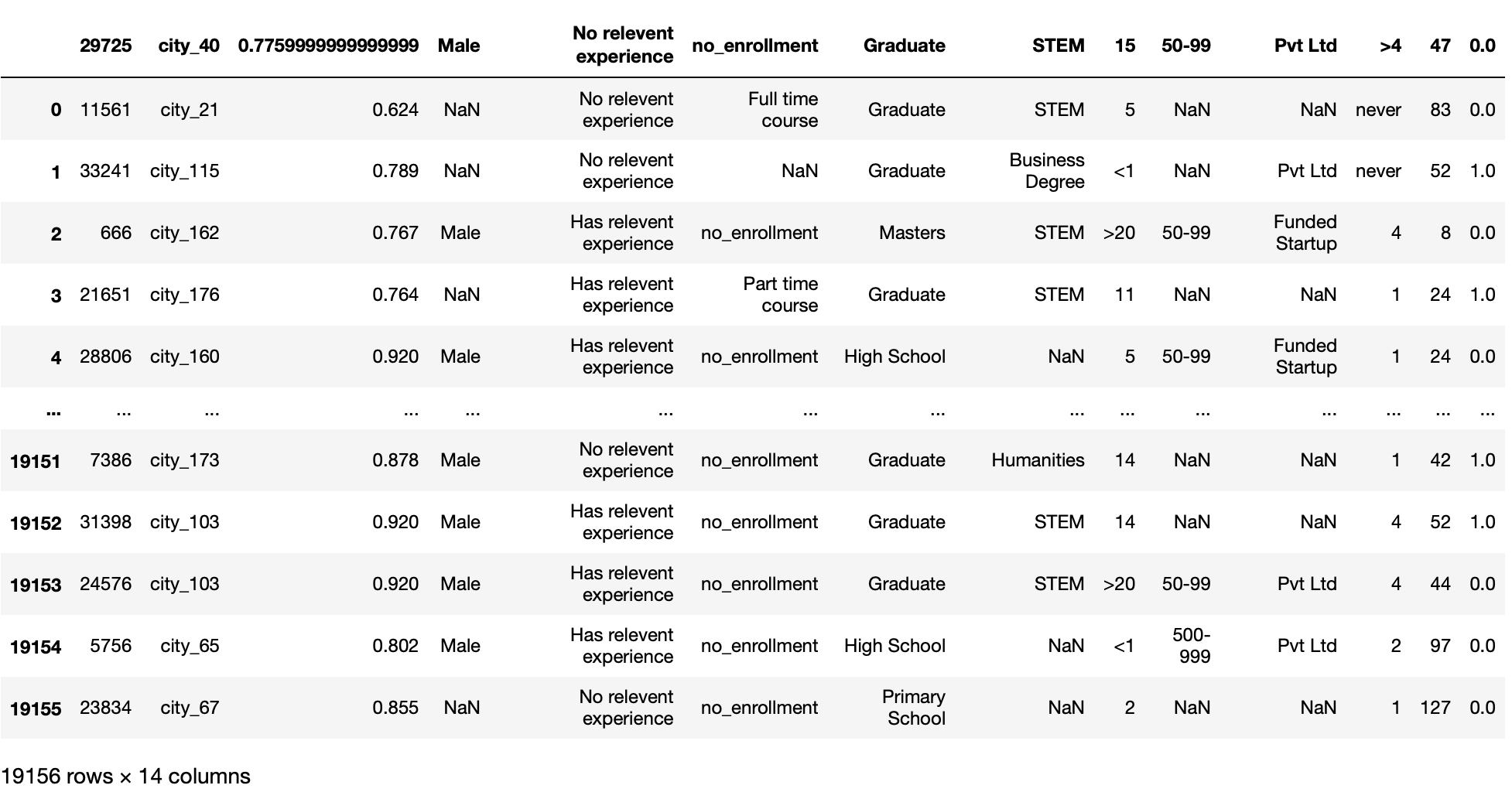
nrows parameter
This function only reads the fixed number (decided by user) of the first rows of the file. You need an int value.
This parameter is useful when we have a huge dataset and we want to load our dataset in chunks instead of directly loading the entire dataset.
pd.read_csv('aug_train.csv',nrows = 100)
Production:
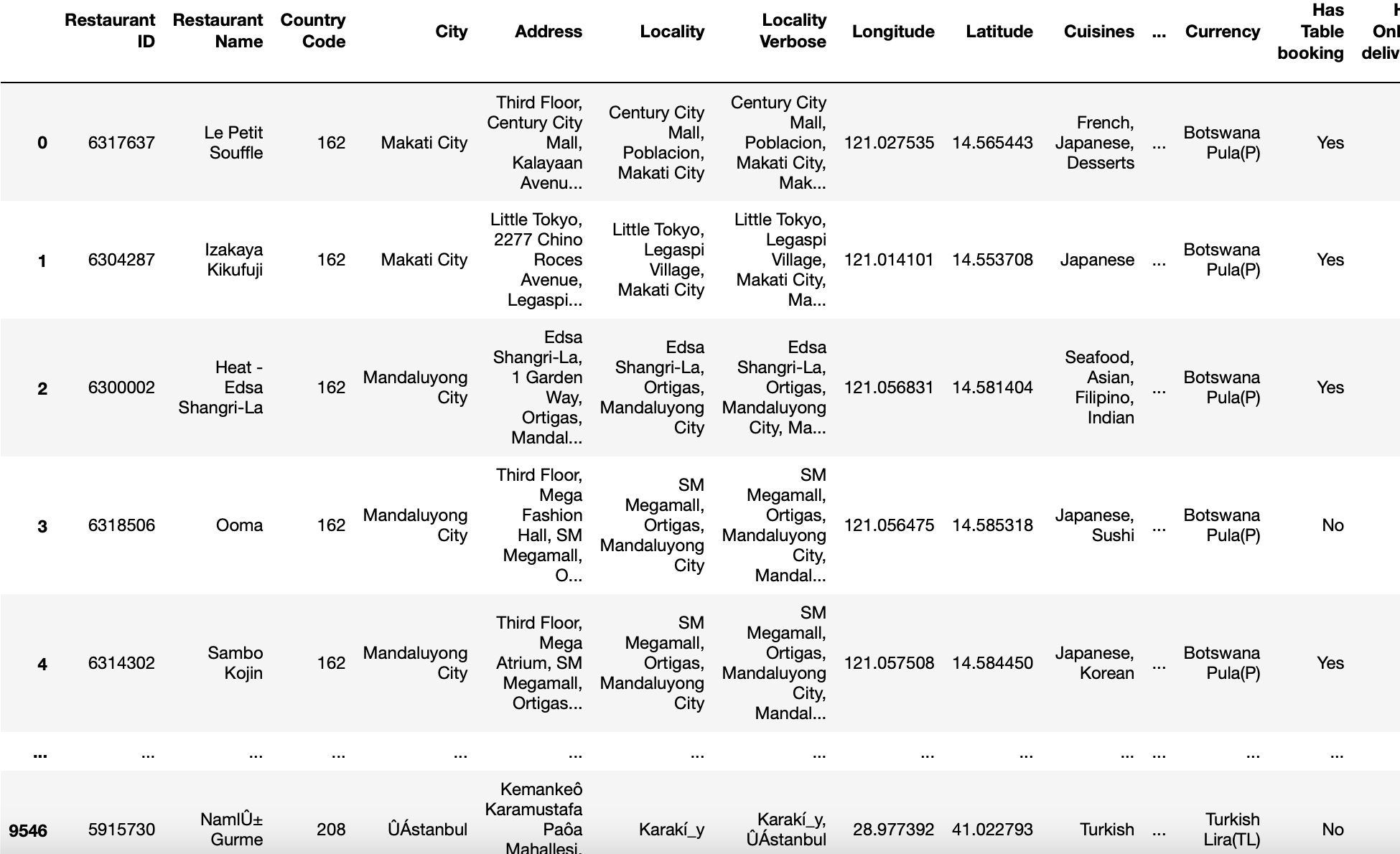
encoding parameter
This parameter helps determine what encoding to use for UTF when reading or writing files.
Sometimes, what happens is that our files are not encoded in the default way, namely, UTF-8. Then, save that with a text editor or add the parameter “Encoding = ‘utf-8 ′ it does not work. In both cases, returns the error.
Then, to solve this problem, we call our read_csv function with encoding = ‘latin1 ′, encoding =’ iso-8859-1 ′ encoding = ‘cp1252 ′ (these are some of the various encodings found in Windows).
pd.read_csv('zomato.csv',encoding='latin-1')
Production:
error-bad-lines parameter
If we have a data set in which some lines have too many fields (For instance, a CSV line with too many commas), soon, by default, an exception is thrown and causes, and no DataFrame will be returned.
Then, to solve this kind of problem, we have to make this parameter False, then you are “faulty lines” will be removed from the DataFrame that is returned. (Only valid with C analyzer)
pd.read_csv('BX-Books.csv', sep=';', encoding="latin-1",error_bad_lines=False)
Production:
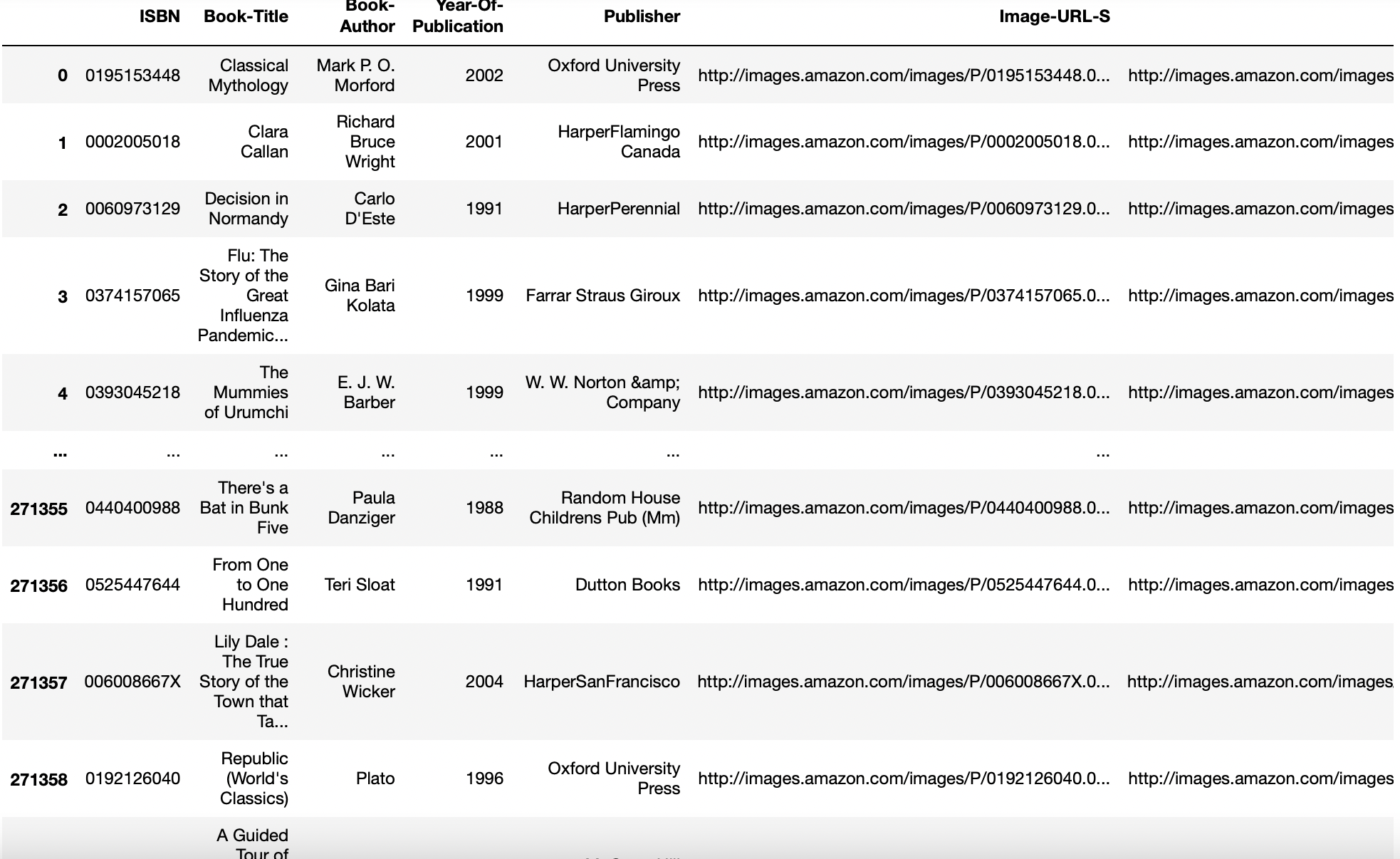
dtype parameter
Data type for data or columns. For instance, {‘a’: e.g. float64, ‘b’: e.g. int32}
Sometimes, to convert our columns from float data type to int data type, this function is useful.
pd.read_csv('aug_train.csv',dtype={'target':int}).info()
Production:
parse-dates parameter
If we make this parameter True, then try parsing the index.
For instance, And [1, 2, 3] -> try parsing the columns 1, 2, 3 each as a separate date column and if we have to combine the columns 1 Y 3 and parse as a single date column, use [[1,3]].
pd.read_csv('IPL Matches 2008-2020.csv',parse_dates=['date']).info()
Production:
converters parameter
This parameter helps us to convert values in the columns based on a custom function given by the user.
def rename(name):
if name == "Royal Challengers Bangalore":
return "RCB"
else:
return name
rename("Royal Challengers Bangalore")
Production:
‘RCB’
pd.read_csv('IPL Matches 2008-2020.csv',converters={'team1':rename})
Production:
parameter values in
As we know, the default missing values will be NaN. If we want other strings to be considered as NaN, then we have to use this parameter. Expect a list of strings as input.
Sometimes, in our dataset, another type of symbol is used to convert them to missing values, so at that time to understand those values as lost, we use this parameter.
pd.read_csv('aug_train.csv',na_values=['Male',])
Production:
This completes our discussion!!
NOTE: In this article, We will only discuss those parameters that are very useful when working with CSV files on a daily basis.. But if you are interested in knowing more parameters, check out the official Pandas website here.
Or you can refer to this Link what's more.
Final notes
Thank you for reading!
If you liked it and want to know more, go to my other articles on data science and machine learning by clicking on the Link
Feel free to contact me at Linkedin, Email.
Anything not mentioned or do you want to share your thoughts? Feel free to comment below and I'll get back to you.
About the Author
Chirag Goyal
Nowadays, I am pursuing my Bachelor of Technology (B.Tech) in Computer Science and Engineering from Indian Institute of Technology Jodhpur (IITJ). I am very excited about machine learning, the deep learningDeep learning, A subdiscipline of artificial intelligence, relies on artificial neural networks to analyze and process large volumes of data. This technique allows machines to learn patterns and perform complex tasks, such as speech recognition and computer vision. Its ability to continuously improve as more data is provided to it makes it a key tool in various industries, from health... and artificial intelligence.
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





