This blog was published as part of Data Science Blogathon 7
import pandas as pd
Every data analysis project requires a data set. These data sets are available in various file formats, as .xlsx, .json, .csv, .html. Conventionally, data sets are mainly found in .csv format. CSV (O Comma Separated Values), as the name suggests, have data elements separated by commas. CSV files are plain text files that have a lighter file size. What's more, CSV files can be viewed and saved in table form in popular tools like Microsoft Excel and Google Sheets.
Commas used in CSV files are known as delimiters. Think of delimiters as a separation boundary that distinguishes between two subsequent data items.

Reading CSV files using Pandas
To read these CSV files, we use a function from the Pandas library called read_csv ().
df = pd.read_csv()
The read_csv function () it has dozens of parameters of which one is mandatory and others are optional for ad hoc use. This mandatory parameter specifies the CSV file that we want to read. For instance,
df = pd.read_csv("C:UsersRahulDesktopabc.csv")
Note: Remember to use double backslashes when specifying the file path.

(Source: personal computer)
The sep parameter
One of the parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project.... optional in read_csv () it is sep, a short name for separator. This operator is the delimiter we talked about before. This sep parameter tells the interpreter, which delimiter is used in our dataset or in Layman's term, how data elements are separated in our CSV file.
The default value of the sep parameter is the coma (,) which means that if we don't specify the sep parameter in our read_csv function (), our file is understood to be using a comma as a delimiter. Therefore, in our code snippet above, we don't specify the sep parameter, our file was understood to have commas as delimiters.
Use other delimiters
It can often happen, the dataset in .csv file format has data elements separated by a delimiter that is not a comma. This includes semicolons, two points, tab space, vertical bars, etc. In such cases, we need to use the sep parameter inside the read.csv function (). For instance, a file called Example.csv it is a CSV file separated by semicolons.
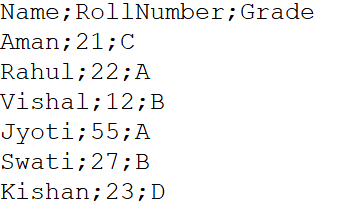
(Source: personal computer)
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = ';')
When running this code, we get a data frame called df:
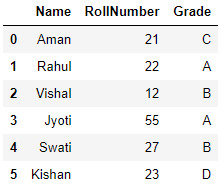
(Source: personal computer)
Vertical bar separator
Therefore, a file delimited by vertical bars can be read by:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = '|')
Colon separator
And a colon delimited file can be read by:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = ':')
Tabs separator
We can often find data sets in file format .tsv. These .tsv files have tab separated values or we can say it has a tab space as delimiter. Said files can be read using the same function .read_csv () from pandas and we need to specify the delimiter. For instance:
df = pd.read_csv("C:UsersRahulDesktopExample.tsv", sep = 't')
Similarly, other separators may be used based on the identified delimiter of our data.
Conclution
It is always useful to check how our data is stored in our dataset. You need to understand the data before you start working with it. A delimiter can be identified effortlessly by checking the data. According to our inspection, we can use the relevant delimiter in the sep parameter.
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





