Introduction
GraphLab was an unexpected step forward in my learning plan. After all, ‘Good things happen when less is expected to happen’. It all started with the end of Black Friday data hack. Of 1200 participants, we got our winners and their interesting solutions.
I read and analyzed them. I realized that I had missed an amazing machine learning tool. A quick scan told me that this tool has immense potential to reduce our machine learning modeling pains.. Then, I decided to explore it further. I have now spent a few days understanding its science and its logical methods of use.. For my surprise, it wasn't hard to understand.
Were you trying to improve your machine learning model? But failed mostly? Try this advanced machine learning tool. One month of trial is free and the subscription of 1 year is available FREE for academic use. Later, you can buy a subscription for the following years.
To get started quickly, here is a beginners guide on GraphLab in Python. To facilitate understanding, I have tried to explain these concepts as simply as possible..
Topics covered
- How it all started ?
- What is GraphLab?
- Benefits and limitations of GraphLab
- How to install GraphLab?
- Getting started with GraphLab
How it all started ?
GraphLab has an interesting history from its beginnings. let me tell you briefly.
GraphLab, known as Dato is founded by Carlos Guestrin. Carlos has a Ph.D. in Computer Science from Stanford University.. it happened a few years ago 7 years. Carlos was a professor at Carnegie Mellon University. Two of his students were working on large-scale distributed machine learning algorithms.. They ran their model on top of Hadoop and found that it took a long time to compute. Situations didn't even get better after using MPI (high performance computing library).
Then, they decided to build a system to write more articles quickly. With this, GraphLab was born.
PD – GraphLab Create is commercial software from GraphLab. GraphLab Create is accessed in Python using the library “graphlab”. Therefore, in this article, ‘GraphLab’ connota GraphLab Create. don't get confused.
What is GraphLab?
GraphLab is a new parallel framework for machine learning written in C ++. It is an open source project and has been designed considering the scale, variety and complexity of real-world data. It incorporates various high level algorithms like Stochastic Gradient Descent (SGD), Gradient Descent & Locking to deliver a high-performance experience. Help data scientists and developers easily build and install large-scale applications.
But, what makes it amazing? It is the presence of ordered libraries for transformation, manipulation and visualization of data models. What's more, is made up of scalable machine learning toolkits that have everything (almost) needed to improve machine learning models. Toolkit includes implementation for deep learning, factor machines, theme modeling, clustering, nearest neighbors and more.
Here is the full architecture of GraphLab Create.
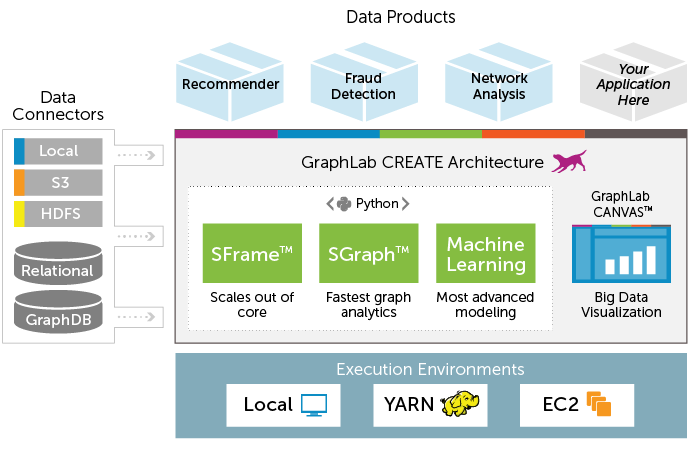
What are the benefits of using GraphLab?
There are multiple benefits of using GraphLab as described below:
- handle big data: GraphLab's data structure can handle large data sets resulting in scalable machine learning. Let's look at the Graph Lab data structure:
-
- SFrame: It is an efficient disk-based tabular data structure that is not limited by RAM. Helps scale data analysis and processing to handle large data sets (Tera byte), even on your laptop. It has syntax similar to pandas or R dataframes. Each column is one SArray, which is an array of items stored on disk. This makes SFrames disk-based. I have discussed the methods for working with “SFrames” in the following sections.
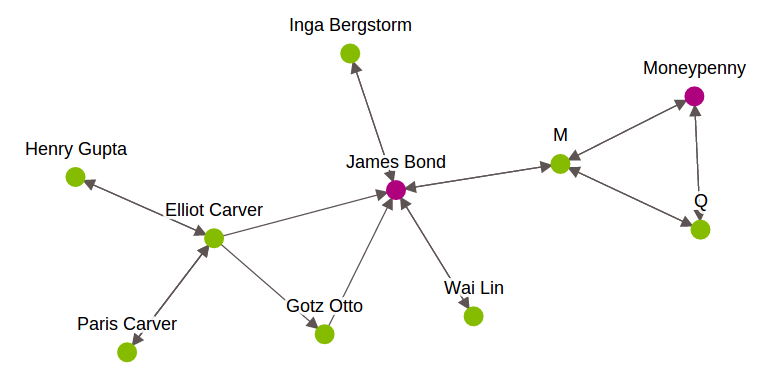
- SGraph: Graph helps us understand networks by analyzing the relationships between pairs of elements.. Each item is represented by a vertex in the graphic. The relationship between elements is represented by borders. In GraphLab, to perform graph-oriented data analysis, uses SGraph object. It is a scalable graph data structure that stores vertices and edges in SFrames. To know more about this, see this Link. Below is a graphic representation of the James Bond characters.

-
- Integration with various data sources: GraphLab supports various data sources like S3, ODBC, JSON, CSV, HDFS and many more.
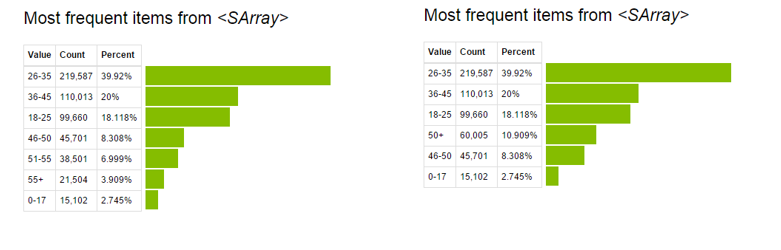
- Exploring and visualizing data with GraphLab Canvas. GraphLab Canvas is an interactive browser-based GUI that allows you to explore tabular data, summary statistics and bivariate graphs. with this function, spend less time coding data exploration. This will help you focus more on understanding the relationship and distribution of the variables.. I have talked about this part in the following sections.
- Function engineering: GraphLab has a built-in option to create new useful functions to improve model performance. It consists of various options such as transformation, grouping, imputation, a hot coding, tf-idf, etc.
- Modeling: GraphLab has several toolsets to offer a quick and easy solution to ML problems.. Allows you to perform various modeling exercises (regression, classification, grouping) in fewer lines of code. Can work on issues like recommendation system, churn prediction, sentiment analysis, image analysis and many more.
- Production automation: Data pipelines allow you to assemble reusable code tasks into jobs. Later, automatically run them in common execution environments (for instance, Amazon Web Services, Hadoop).
- GraphLab Create SDK: Advanced users can extend the capabilities of GraphLab Create using the GraphLab Create SDK. You can define new models / machine learning programs and integrate them with the rest of the suite. View the GitHub repository here.
- License: Has limitation of use. You can opt for a free trial period of 30 days or a one-year license for the academic edition. To extend your subscription, You will be charged (view subscription structure here).
How to install GraphLab?
You can also use GraphLab once you have used your license. But nevertheless, you can also start with the free trial or the academic edition with subscription of 1 year. Therefore, before installation, your machine must meet the system requirements to run GraphLab.
System Requirements for GraphLab:

If your system does not meet the above requirements, You can use GraphLab Create in the AWS Free Tier what's more.
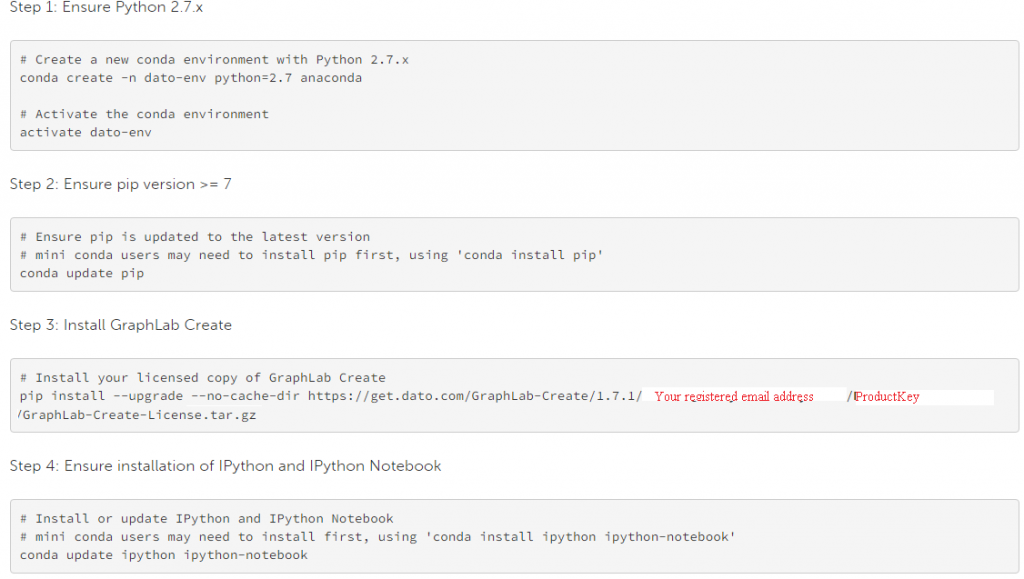
Installation steps:
- sign up for free trail. after registration, you will receive a product key.
- Select your operating system (automatic selection is turned on) and follow the instructions given
- the following are the command-line installation instructions (to “Anaconda Python Environment”).
Getting Started with Graphlab
Once you have successfully installed GraphLab, you can access it using “import ".
import graphlab
or
import graphlab as gl
Here, I will demonstrate the use of GraphLab by solving a data science challenge. I have the dataset taken from Black Friday data hack.
-
-
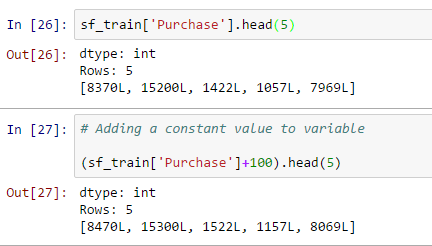
- Data manipulation: you can also perform a data manipulation operation with sframe, how to add a constant value to all values, concatenate two or more variables, create a new output variable based on a variable as shown below:
- Add a constant value to the variable:

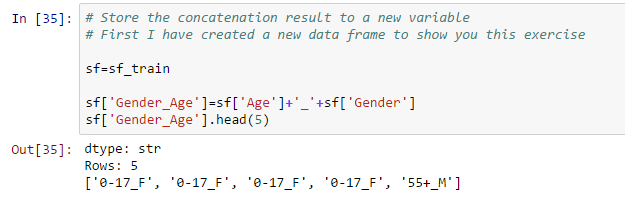
- Concatenate two strings and store them in a new variable:

- Update values of existing variables: this can be done using the application function. In this data set, I have combined age groups greater than 50 using the following code:
# Make a change to existing variable # Combine all bins of age greater than 50
def combine_age(age): if age=='51-55': return '50+' elif age=='55+': return '50+' else: return age
Sf['Age']=sf['Age'].apply(combine_age)
Now, observe the pre- and post-display of the variable “Age”.
 For more details on manipulating data with GraphLab, see this Link.
For more details on manipulating data with GraphLab, see this Link.
- Add a constant value to the variable:
- Function engineering: Feature engineering is an effective method to improve model performance. with this technique, we can create new variables after transformation or manipulation of existing variables. In fact, GraphLab has automated this process. They have various transformation options for numerical features, categorical, text and image. What's more, you will find direct options for function grouping, imputation, a hot coding, counting threshold, TF-IDF, Hasher, Tokenzing and others. Let's look at the imputation of categorical characteristic “Product_Category_2” based on “Age” Y “Gender”From the “Black Friday” dataset.
# Create the data # Variables based on which we want to perform imputation and variable to impute # You can look at the algorithms behind the imputation here. sf_impute = sf_train['Age','Gender','Product_Category_2']
imputer = graphlab.feature_engineering. CategoricalImputer(feature="Product_Category_2") # Fit and transform on the same data transformed_sf = imputer.fit_transform(sf_impute)#Retrieve the imputed values transformed_sf

Finally, you can bring this input variable to the original dataset.
sf_train['Predicted_Product_Category_2']=transformed_sf['predicted_feature_Product_Category_2']
Similarly, you can apply other feature engineering operations to the dataset based on your requirements. You can refer to this Link for more details.
- Modeling: In this stage, we make predictions from past data. GraphLab easily creates models for common tasks, What:
A) Prediction of numerical quantities
B) Building Recommendation Systems
C) Group data and documents
D) Chart analysis
- Data manipulation: you can also perform a data manipulation operation with sframe, how to add a constant value to all values, concatenate two or more variables, create a new output variable based on a variable as shown below:
-
 For more details on manipulating data with GraphLab, see this
For more details on manipulating data with GraphLab, see this 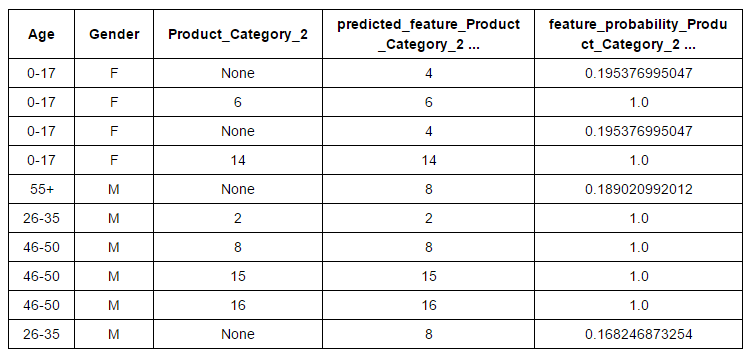
In the Black Friday Challenge, we are obliged to predict numerical quantities “Purchase”, namely, we need a regression model to predict the “Purchase”.
In GraphLab, tenemos tres tipos de modelos de regresión:
A) Linear regression
B) Random forest regression
C) Regresión impulsada por gradientes
Si tiene alguna confusión en la selección del algoritmo, GraphLab se encarga de eso. Do not worry. Selecciona el modelo de regresión correcto automáticamente.
# Make a train-test split
train_data, validate_data = sf_train.random_split(0.8)
# Automatically picks the right model based on your data. model = graphlab.regression.create(train_data, target="Purchase", features = ['Gender','Age','Occupation','City_Category','Stay_In_Current_City_Years', 'Marital_Status','Product_Category_1'])
# Save predictions to an SArray
predictions = model.predict(validate_data)
# Evaluate the model and save the results into a dictionary
results = model.evaluate(validate_data)
results
Production:
{'max_error': 13377.561969523947, 'rmse': 3007.1225949345117}
#Do prediction on test data set
final_predictions = model.predict(sf_test)
To learn more about other modeling techniques such as clustering, classification, recommendation system, text analysis, chart analysis, recommendation systems, you can check this Link. Alternatively, here is the complete User's guide by Data.
Final notes
In this article, we learned about “GraphLab Create”, which helps to handle a large data set while building machine learning models. We also look at Graphlab's data structure that allows it to handle large datasets like “SFrame” and “SGraph”. I recommend you to use GraphLab. You'll love its automated features like data exploration (Canvas, interactive web data exploration tool), function engineering, the selection of suitable models and the implementation.
For a better understanding, I also demonstrated a modeling exercise using GraphLab. In my next article about GraphLab, I will focus on chart analysis and recommendation system.
Do you find helpful this article ? Share with us your experience with GraphLab.





