In one of my previous articles, we talk about synthetic keys (synthetic keys in Qlikview – Simplified). We discuss why synthetic keys are generated and we conclude that if we have multiple synthetic keys in our data model, it could be the result of an incorrect data model and generate unexpected results. We also saw some ways to remove synthetic keys and improve our data model.
This article begins where we left off our last article. We will discuss two more techniques for removing synthetic keys and optimizing our data model in our QlikView application.. These two techniques are: –
- Concatenation
- Links table / keys
Let's understand these two techniques in detail using examples:
Analyze the sales trend over the years with year-over-year transaction data sets
A sales-oriented company has year-over-year transaction data sets (one data set for each year) with one or two different fields (due to base system changes or defects) but the rest of the fields are similar. The company wants to show year-over-year sales trends using these data sets.
In this stage, let's load all interannual datasets into QlikView. As expected, QlikView creates synthetic keys to join these tables, since these tables have multiple common fields. You can see the data model with synthetic key below. Now, to remove the synthetic key, we can't rename / remove all these fields because they are important and related to each other. Here, we need all the fields in a table to show year-over-year trends, monthly seasonality during the year and much more. As you know, Qlikview concatena / automatically join tables if they have the same granularity and columns. But nevertheless, on our stage, some of the columns are different. Here we need to force concatenation using CONCATENAR and combine the data into a single table (See Snpashot on the right).
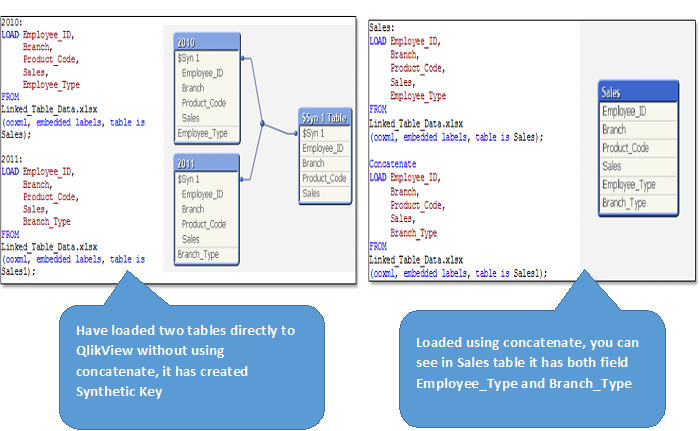
Then, you can also see that in the SALES table, both Employee_Type and Branch_Type appear with their available values and the total number of records is N1 (number of records in 2010) + N2 (number of records in 2011).
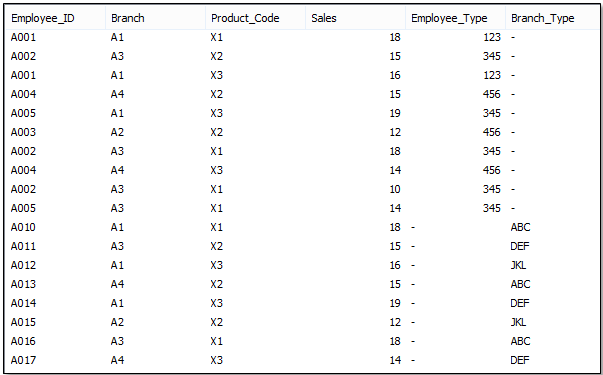
Similarly, if granularity and columns in tables are the same, then we can use Concatenate which will merge the tables into one and the resulting table will have the sum of the rows from the two tables.
Analyze the employee's sales performance against your goals (and analyze performance across multiple dimensions as a product, year of incorporation, region):
To do this we have five tables, in which two are a table of facts and others are of dimension"Dimension" It is a term that is used in various disciplines, such as physics, Mathematics and philosophy. It refers to the extent to which an object or phenomenon can be analyzed or described. In physics, for instance, there is talk of spatial and temporal dimensions, while in mathematics it can refer to the number of coordinates necessary to represent a space. Understanding it is fundamental to the study and... (the table structure is shown below).
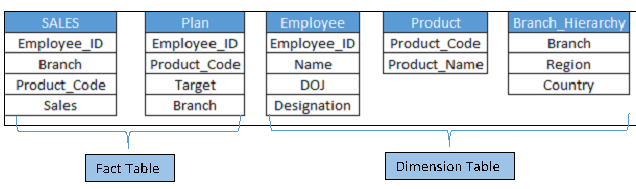
Above you can see that the tables, “Sales” Y “Plan” they have three common fields and the Dimension tables are also associated with both fact tables.
Now, if we load all these tables directly into QlikView, will result in a data model with synthetic keys (screenshot below).
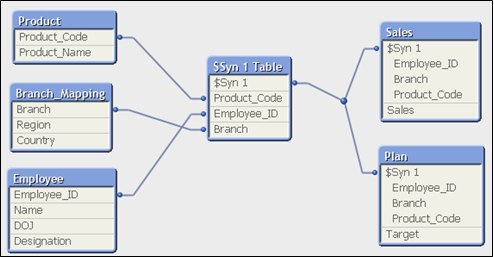
Since fact tables do not have similar columns, we cannot opt for concatenation. At the same time, we also need them for our analysis. Now, to remove the synthetic key in this data model, we should use LINK mesa. Links two or more fact tables by removing all common fields from the original tables and placing them in a new table (called link table). The new link table contains all possible combinations of values for the set of fields through a unique key and is associated with the original tables.
In simple words, we can say that the link table replaces the synthetic key table and has all the combinations of the key fields that are common for fact tables. We should also create a new one Composite KeyThe "Composite Key" is a rhythmic pattern used in Afro-Caribbean music, especially in styles such as son, Salsa and meringue. It is characterized by a combination of binary and ternary tenses, which generates a sense of rhythmic complexity. Its use in percussion, especially on instruments such as the cajón and timpani, adds dynamism and sonic richness to compositions, making it a fundamental element of these.. to connect the three boards (two-fact tables and link table) and remove common fields from fact tables.
Rules for defining the link table: –
- Create a key based on fact table common fields and break all other associations through comments or renaming.
- Make sure all joins that exist in both fact tables are available in the created link table; on the contrary, may cause loss of some records.
- The link table must have different records.
Now let's see the methods to develop the data model using Link Table: –
Paso 1 Load the fact table, form key for all common fields and comment all common fields.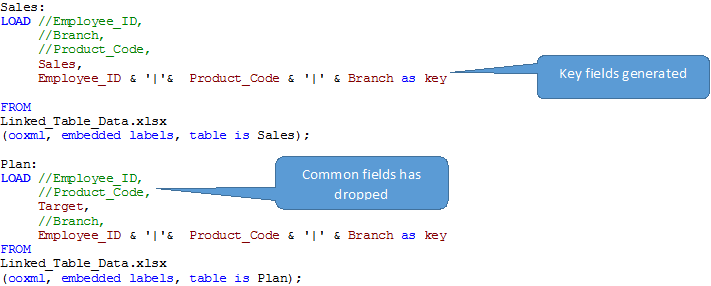
Paso 2 Create the link table by loading the distinct values from the fact tables
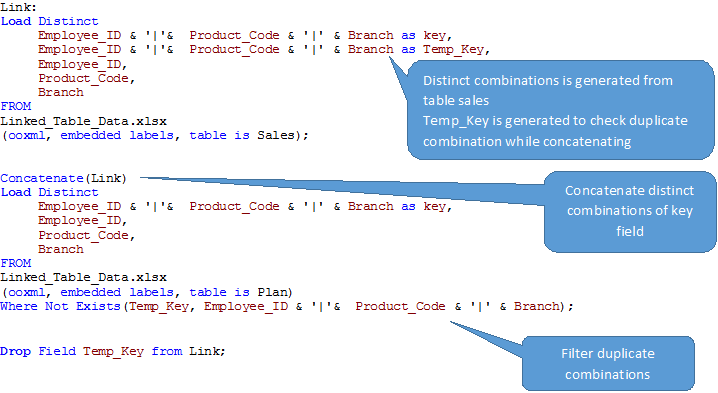
Paso 3 Upload other dimension tables.

Paso 4 Reload it and we would have the following data model without a synthetic key.
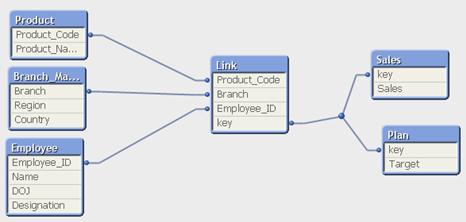
Above, you can see a data model with link table and it has all the common fields of fact tables.
Table of links Vs concatenate
In the examples above, we observe both scenarios, where we should go with the CONCATENATION or LINK table. Both methods have their own advantages. Let's see some of these:
- If the granularity and fields in the fact tables are the same, we should choose to concatenate, which will merge the tables into one. When these are different and are attached to different dimensions, we will use the LINK table.
- With Link Tables you can maintain a more understandable data model. Secondly, Concatenate is a simplistic approach with excellent performance to handle a large volume of data.
- The choice also depends on what type of analysis we want to perform and which model will be sufficient for our purpose..
Final note: –
As mentioned earlier, multiple synthetic keys usually reflect wrong data model. We had looked at some methods to remove synthetic keys in the past. In this article, we particularly analyze two methods: LINK table and concatenation. Both methods have their own advantages and applications.. The choice of method should depend on business requirements and the type of data analysis required.
Has this series been useful to you? We have simplified a complex topic: synthetic keys and we have tried to present it in a simple and understandable way. If you need more help on the data model and synthetic keys, feel free to ask your questions through the comments below.





