
With increasing computational power, now we can select algorithms that perform very intensive calculations. One of those algorithms is the “Random forest”, which we will talk about in this post. Although the algorithm is very popular in various competitions (as an example, the ones that run in Kaggle), the end result of the model is like a black box and, therefore, should be used wisely.
before continuing, here is an example on the relevance of selecting the best algorithm.
Relevance of selecting the correct algorithm
Yesterday I saw a movie called ” The era of El Mañana“. I loved the concept and thought process that was behind the plot of this movie. Let me summarize the plot (without commenting on the climax, Sure). Unlike other sci-fi movies, this movie revolves around a single power that is bestowed on both sides (hero and villain). Power is the ability to restart the day.
The human race is at war with an exotic species called “Mimics”. Mimic is described as a much more evolved civilization than an exotic species. The entire Mimic civilization is like a single complete organism. It has a central brain called “Omega” which controls all other organisms of civilization. Stay in touch with all other species of civilization every second. "Alpha" is the main warrior species (like the nervous system) of this civilization and takes command of "Omega". “Omega” has the power to restart the day at any time.
Now, let's wear a predictive analyst's hat to analyze this plot. If a system has the ability to restart the day at any time, he will use this power whenever one of his warrior species dies. Y, therefore, there will be no single war, when any of the warrior species (alfa) will truly die, and the brain “Omega” will repeatedly test the best scenario to maximize the death of the human race and limit the number of alpha kills (warrior species) to zero every day. You can imagine this as “THE BEST” predictive algorithm ever created. It is literally impossible to defeat such an algorithm.
Let's now go back to “Random forests” using a case study.
Case study
Below is a distribution of annual income Gini Coefficients in different countries:
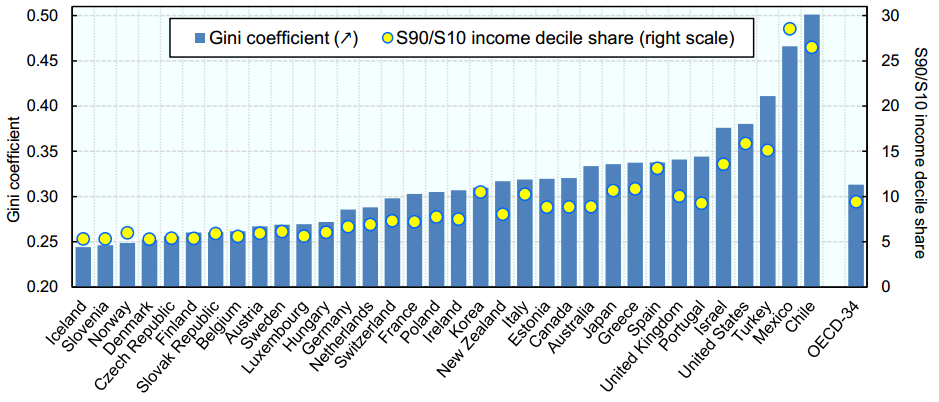
Mexico has the second highest Gini coefficient and, therefore, has a very high segregation in the annual income of rich and poor. Our task is to create an accurate predictive algorithm to estimate the annual income level of each individual in Mexico. The income brackets are as follows:
1. Less than $ 40,000
2. $ 40 000 – 150 000
3. More of $ 150 000
Below is the information available for each individual:
1. Age, 2. Gender, 3. Highest educational qualification, 4. Work in industry, 5. Residence in Metro / No meter
We need to devise an algorithm to give an accurate prediction for an individual who has the following traits:
1. Age: 35 years, 2, Gender: Masculine, 3. Highest educational qualification: diplomat, 4. Industry: Manufacture, 5. Home: Metro
We will only talk about random forest to make this prediction in this post.
The Random Forest algorithm
The random forest is like a bootstrap algorithm with the decision tree model (CART). Let's say we have 1000 observations in the entire population with 10 variables. The random forest tries to build multiple CART models with different samples and different initial variables. As an example, a random sample of 100 observations and 5 Randomly chosen initial variables to build a CART model. Will repeat the procedure (Let's say) 10 times and then make a final prediction on each observation. The final forecast is a function of each prediction. This final prediction can simply be the mean of each prediction.
Back to case study
Disclaimer: the numbers in this post are illustrative
Mexico has a population of 118 MM. Let's say the Random Forest algorithm collects 10k observations with just one variable (to simplify) to build each CART model. Total, we are looking at the model of 5 CART being built with different variables. In a real life obstacle, you will have more population samples and different combinations of input variables.
Salary bands:
Band 1: Less than $ 40,000
Band 2: $ 40 000 – 150 000
Band 3: more of $ 150,000
Below are the results of the 5 different CART models.
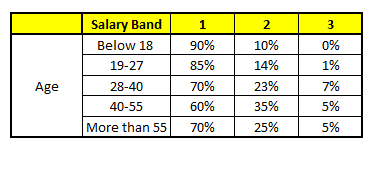
TROLLEY 1: Variable age
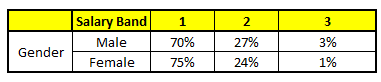
TROLLEY 2: Variable gender
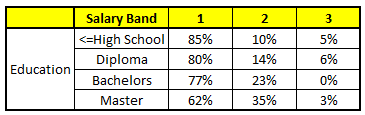
TROLLEY 3: Variable education
TROLLEY 4: Variable residence

TROLLEY 5: Variable industry
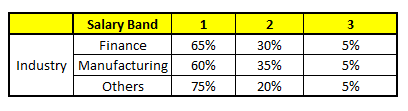
Using these 5 modelos CART, we need to arrive at a unique probability set to belong to each of the wage classes. To simplify, we will only take a mean of probabilities in this case study. Apart from the simple mean, we also consider the voting method to arrive at the final forecast. To reach the final forecast, let's locate the following profile in each CART model:
1. Age: 35 years, 2, Gender: Masculine, 3. Highest educational qualification: diplomat, 4. Industry: Manufacture, 5. Home: Metro
For each of these CART models, The distribution between the salary bands is shown below.:
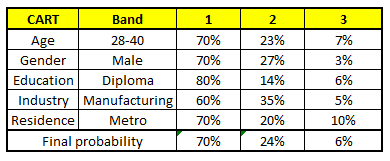
The final probability is simply the average of the probability in the same salary bands in different CART models. As you can see in this analysis, there's a 70% chances of this individual falling into class 1 (less than $ 40,000) and around the 24% chances of individual falling into class 2.
Final notes
Random forest provides much more accurate predictions compared to simple CART models / CHAID or regression in many scenarios. These cases generally have a large number of predictive variables and a huge sample size. This is because it captures the variance of several input variables at the same time and enables a large number of observations to participate in the forecast.. In some of the next posts, we will talk more about the algorithm in more detail and talk about how to build a simple random forest in R.





