Store models in Google Cloud Storage buckets and then write Google Cloud Functions. Using Python to retrieve models from the repository and using HTTP requests JSONJSON, o JavaScript Object Notation, It is a lightweight data exchange format that is easy for humans to read and write, and easy for machines to analyze and generate. It is commonly used in web applications to send and receive information between a server and a client. Its structure is based on key-value pairs, making it versatile and widely adopted in software development.., we can get predicted values for the given inputs with the help of Google Cloud Function.
1. Regarding the data, code and models
Taking the movie reviews data sets for sentiment analysis, see the answer here in my GitHub repository and data, Models also available in the same repository.
2. Create a storage bucket
When running the “ServerlessDeployment.ipynb"File will get 3 ML models: Decision classifier, LinearSVC and Logistic Regression.
Click on the Storage Browser option to create a new bucket as shown in the image:
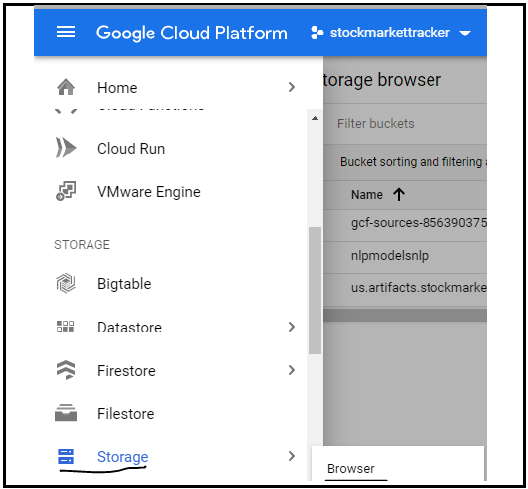
FIG: click the GCP Store option
3. Create a new role
Create a new bucket, then create a folder and load the 3 models in that folder creating 3 subfolders as shown.
Here Models are my main folder name and my subfolders are:
- decision_tree_model
- linear_svc_model
- logistic_region_model
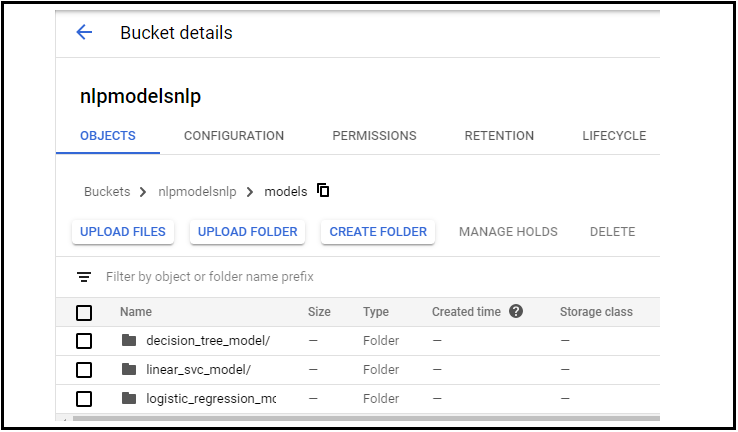
FIG: Folders in storage
4. Create a function
Subsequently, go to Google Cloud Functions and create a function, then select the trigger type as HTTP and select the language as Python (you can select any language):
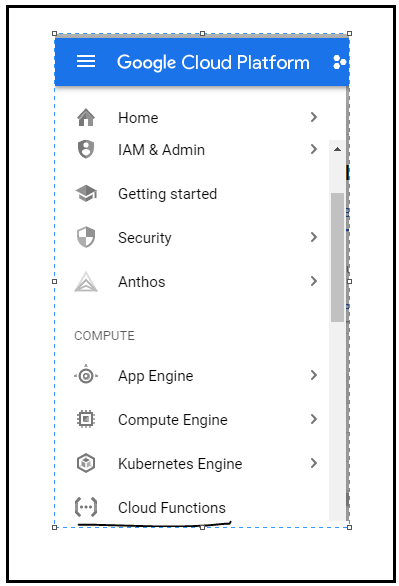
FIG: Select the GCP Cloud Function option
5. Write the cloud function in the editor.
Check the cloud function in my repository, here i have imported the required libraries to call models from google cloud warehouse and other libraries for HTTP request GET method used to test url solution and POST method delete default template and paste our code later gherkin is used to deserialize our google.cloud model: access our cloud storage feature.
If the incoming request is GET we simply return “welcome to the classifier”.
If the incoming request is MAIL enter the JSON data in the request body get JSON gives us to instantiate the storage client object and enter the models from the warehouse, here we have 3 – classification models in the warehouse.
If the user specifies "Decision Classifier" we access the model from the respective folder respectively with other models.
If the user does not specify any model, the default model is the logistic regression model.
The variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... blob contiene una referencia al archivo model.pkl para el modelo correcto.
We download the .pkl file on the local machine where this function is executed in the cloud. Now, each invocation could be running in a different VM and we only access the folder / temp on the VM, that is why we save our model.pkl file.
We de-sterilize the model by invoking pkl.load to enter the prediction instances from the incoming request and we call model.predict on the prediction data.
The solution that will be sent from the serverless function is the original text which is the revision we want to categorize and our pred class.
After main.py, write requirement.txt with required libraries and versions
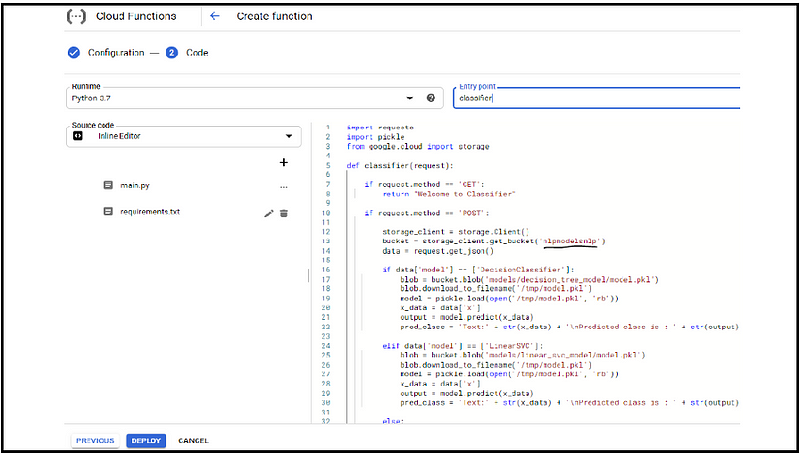
5. Put the model into practice
6. Try the model
Become a full stack data scientist by learning various ML model implementations and the reason behind this great explanation in the early days I have a hard time learning ML model implementation, so i decided my blog should be useful for data science beginners from start to finish.





