This article was published as part of the Data Science Blogathon
Introduction
Data science is an emerging field with numerous career opportunities. We all must have heard of the best skills in data science. to get started, The easiest and most essential skill every aspiring data science should acquire is SQL.
Today, most companies are data oriented. Estos datos se almacenan en una databaseA database is an organized set of information that allows you to store, Manage and retrieve data efficiently. Used in various applications, from enterprise systems to online platforms, Databases can be relational or non-relational. Proper design is critical to optimizing performance and ensuring information integrity, thus facilitating informed decision-making in different contexts.... y se gestionan y procesan a través de un sistema de gestión de bases de datos. DBMS makes our work so easy and organized. Therefore, it is essential to integrate the most popular programming language with the amazing DBMS tool.
SQL is the most widely used programming language when working with databases and is compatible with various relational database systems, like MySQL, SQL Server y Oracle. But nevertheless, the SQL standard has some features that are implemented differently in different database systems. Therefore, SQL becomes one of the most important concepts to learn in this field of data science.
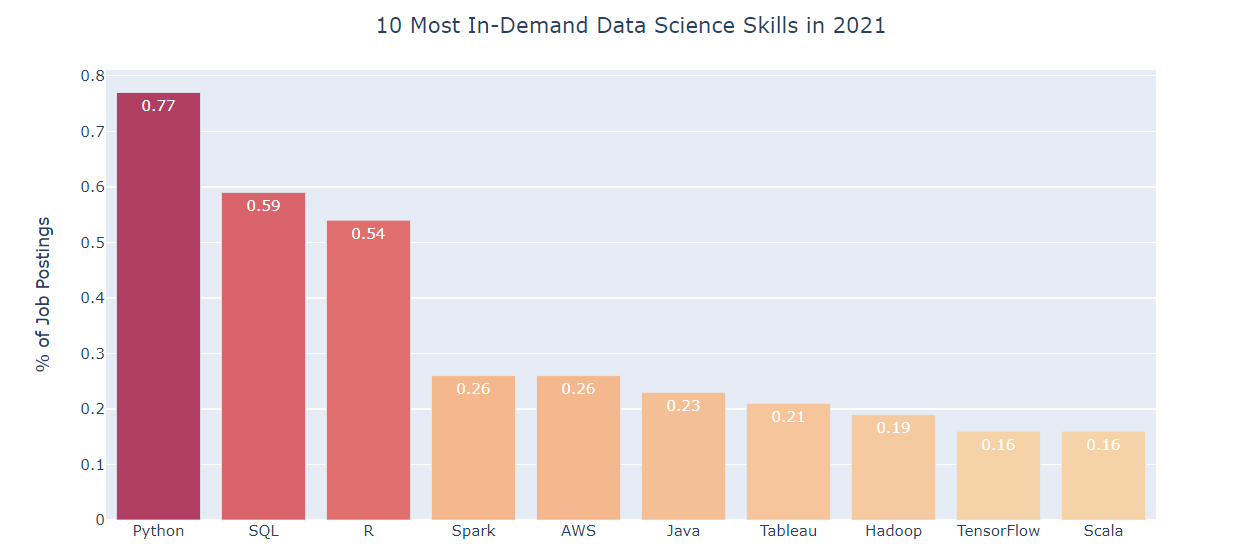
Image source: KDnuggets
The need for SQL in data science
SQL (Structured Query Language) used to perform various operations on data stored in databases, how to update records, delete records, create and modify tables, views, etc. SQL is also the standard for today's big data platforms that use SQL as their key API for their relational databases..
Data science is the comprehensive study of data. To work with data, we need to extract them from the database. This is where SQL comes into the picture. Relational database management is a crucial part of data science. A data scientist can control, define, manipulate, create and query the database using SQL commands.
Many modern industries have equipped the data management of their products with NoSQL technology, but SQL is still the ideal choice for many business intelligence and office operations tools.
Many of the database platforms are based on SQL. That is why it has become a standard for many database systems.. Modern big data systems like Hadoop, Spark also use SQL only to maintain relational database systems and process structured data.
We can say that:
1. A data scientist needs SQL to handle structured data. How structured data is stored in relational databases. Therefore, to consult these databases, a data scientist must have a good understanding of SQL commands.
Big Data platforms such as Hadoop and Spark provide an extension for querying using SQL commands to manipulate.
3.SQL is the standard tool for experimenting with data by creating test environments.
4. To perform analytical operations on data that is stored in relational databases such as Oracle, Microsoft SQL, MySQL, we need SQL.
5. SQL is also an essential tool for data preparation and processing. Therefore, when dealing with various Big Data tools, we use SQL.
SQL Key Elements for Data Science
Below are the key aspects of SQL that are most useful for data science. All Aspiring Data Scientists Should Know These Necessary SQL Skills and Features.
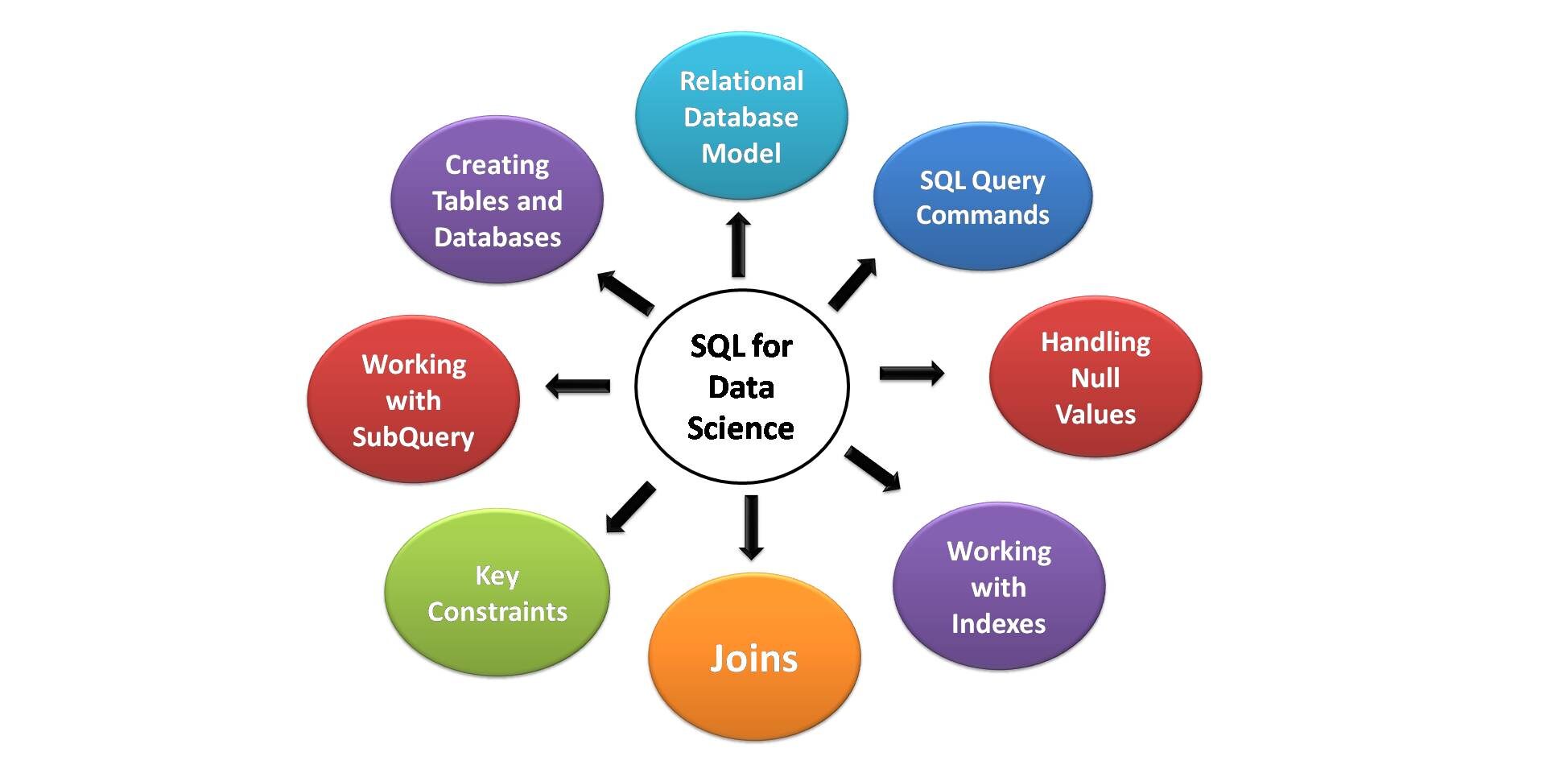
Image source: For me
Introduction to SQL with Python
As we all know, SQL is the most widely used database administration tool and Python is the most popular data science language for its flexibility and wide range of libraries. There are several ways to use SQL with Python. Python provides several libraries that are developed and can be used for this purpose. SQLite, PostgreSQL, and MySQL are examples of these libraries.
Why use SQL with Python
There are many use cases where data scientists want to connect Python to SQL. Data scientists need to connect an SQL database to be able to store the data coming from the web application. It also helps to communicate between different data sources.
No need to switch between different programming languages for data management. Makes the work of data scientists more convenient. They will be able to use their Python skills to manipulate data stored in an SQL database. They don't need a CSV file.
MySQL with Python
MySQL is a server-based database management system. A MySQL server can have several databases. A MySQL database consists of a two-step process to create a database:
1. Establish a connection to a MySQL server.
2. Run separate queries to build the database and process the data.
Let's start with MySQL with Python
First, we will create a connection between the MySQL server and MySQL DB. For it, we will define a function that will establish a connection to the mysql database server and return the connection object:
!pip install mysql-connector-python
import mysql.connector
from mysql.connector import Error
def create_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("Connection to MySQL DB successful")
except Error as e:
print(f"The error '{e}' occurred")
return connection
connection = create_connection("localhost", "root", "")
In the above code, we have defined a create_connection function () que acepta los siguientes tres parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project....:
1. nombre_host
2. Username
3. user password
mysql.connector is a python sql module that contains a .connect method () that is used to connect to a MySQL database server. When the connection is established, el objeto de conexión creado se devolverá a la función de llamada.
Up to now, la conexión se estableció correctamente, ahora creemos una base de datos.
#we have created a function to create database that contions two parameters #connection and query defcreate_database(connection,query): #now we are creating an object cursor to execute SQL queries cursor=connection.cursor() try: #query to be executed will be passed in cursor.execute() in string form cursor.execute(query) print("Database created successfully") exceptErrorase: print(f"The error '{e}' occurred")
#now we are creating a database named example_app create_database_query="CREATE DATABASE example_app" create_database(connection,create_database_query)
#now will create database example_app on database server #and also cretae connection between database and server defcreate_connection(host_name,user_name,user_password,db_name): connection=None try: connection=mysql.connector.connect( host=host_name, user=user_name, passwd=user_password, database=db_name ) print("Connection to MySQL DB successful") exceptErrorase: print(f"The error '{e}' occurred") returnconnection
#calling thecreate_connection()and connects to theexample_appdatabase. connection=create_connection("localhost","root","","example_app")
SQLite
SQLite is probably the simplest database that we can connect to a Python application, since it is an integrated module, we don't need to install any external Python SQL module. By default, the Python installation contains a Python SQL library called sqlite3 that can be used to interact with a SQLite database.
SQLite is a serverless database. Read and write data to a file. That means we don't even need to install and run a SQLite server to perform database operations like MySQL and PostgreSQL!!
Usemos sqlite3 to connect to a SQLite database in Python:
importsqlite3 fromsqlite3importError
defcreate_connection(path): connection=None try: connection=sqlite3.connect(path) print("Connection to SQLite DB successful")
exceptErrorase: print(f"The error '{e}' occurred") returnconnection
In the above code, we have imported sqlite3 and the Error class from the module. Then define a function called .create_connection () that will accept the path to the SQLite database. Then .connect () of the sqlite3 module will take the path of the SQLite database as a parameter. Whether the database exists in the path specified in .connect, a connection to the database will be established. On the contrary, a new database is created at the specified path and then a connection is established.
sqlite3.connect (route) will return a connection object, which was also returned by create_connection (). this connection object will be used to execute sql queries against a sqlite database. the following line of code will create a connection to the sqlite database:
connection=create_connection("E:example_app.sqlite")
Once the connection is established we can see that the database file is created in the root directory and if we want, we can also change the file location.
In this article, we discuss how SQL is essential for data science and also how we can work with SQL using Python. Thank you for reading. Let me know your comments and suggestions in the comment section.
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





