Introduction
Long time, I was doing the predictive model using Linear Regression and I found a variable whose non-standardized regression coefficient (beta or estimation) close to zero, but after some analysis, I find that it is statistically significant (means p value <0.05 ). Sabemos que si una variable es significativa para un modelo en particular, significa que el valor de su coeficiente es significativo y distinto de cero. Entonces, la pregunta que ocurre es "¿Por qué el valor del coeficiente es cercano a cero pero esa variable es significativa para nuestro modelo predictivo?".
The solution to this question lies in the difference between the standardized and non-standardized regression coefficients.. Then, in this post, we will see the basic concepts behind these coefficients and how they differ from each other with their advantages and disadvantages.
The concept of standardization or standard coefficients comes into play when the independent variables or the predictor of a particular model are expressed in different units.. As an example, let's say we have three independent characteristics, namely, height, age and weight. Your height is in inches, your weight in kilograms and your age in years. If we want to categorize these predictors based on the non-standardized coefficient (that comes directly when we train a regression model), it would not be a fair comparison since the units for all predictors are different.
Non-standardized regression coefficients
1. What are non-standardized regression coefficients?
The non-standardized coefficients are those that are produced by the linear regression model after its training using the independent variables that are measured on their original scales., In other words, in the same units in which the dataset is taken from the source to train the model.
– The non-standardized coefficient should not be used to rule out or categorize predictors (also known as independent variables), since it does not eliminate the unit of measure.
As an example, Let's take a hypothetical example where we want to predict revenue (in rupees) of a person based on their age (in years), height (and cm) and weight (in kg). Then, here the inputs for our regression model are age, height and weight, and production is income. Subsequently,
Income (rupees) = A0 + a1 * age (years) + a2 * height (cm) + a3 * weight (kg) + e (eqn-1)
2. How to interpret non-standardized regression coefficients?
They are used to interpret the effect of each independent variable on the result. (answer / Exit). Its interpretation is simple and intuitive.
– All other variables are held constant, a change of 1 unit in Xi (predictors) implies that there is an average change of units ai in Y (Outcome).
In the example above, and a1 = 0.3, a2 = 0.2 y a3 = 0.4 (and we assume that they are all statistically significant), then we interpret these coefficients as:
To have 1 year is associated with an increase in 0,3 in income, assuming other variables are constant (means there is no change in height and weight).
Equivalently, we can also interpret the coefficient for other independent variables.
Represents the amount by which the dependent variable changes if we change the independent variable by one, keeping the other independent variables constant..
3. Limitations of non-standardized regression coefficients
– Non-standardized coefficients are excellent for interpreting the link between an independent variable X and a result Y. Despite this, are not useful for comparing the effect of one independent variable with another in the model.
– As an example, Which variable has the greatest impact on income, age, height or weight?
We can try to answer this question by looking at equation-1 and again assume that a1 = 0.3, a2 = 0.2 y a3 = 0.4, we conclude that:
“An increase of 20 cm in height has the same effect on weight gain 10 times”
Even so, This does not answer the question of which variable affects the Income the most.
Specifically, the claim that “the effect of weight gain on 10 times = the effect of the increase in the height of 20 cm ”makes no sense without specifying how difficult it is to increase the height by 20 cm, specifically for someone unfamiliar with this scale.
Then, finally, we conclude that a direct comparison of the regression coefficients for either of the two independent variables makes no sense or is not useful since these independent variables are on the different scales (age in years, weight in kg and height in cm).
It turns out that the effects of these variables can be compared using the standardized version of their coefficients. And that is what we are going to discuss next.
Standardized regression coefficients
1. What are standardized regression coefficients?
The standardized regression coefficients are obtained by training (or running) a linear regression model in the standardized form of the variables.
Standardized variables are calculated by subtracting the mean and dividing by the standard deviation of each observation., In other words, calculating the Z score. I would mean 0 and standard deviation 1. Then, they do not represent their original scales since they do not have a unit.
For each observation “j” of the variable X, we calculate the z-score using the formula:
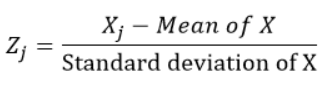
2. What variables do we have to standardize to find the standardized regression coefficients, In other words, both the predictor and the solution or any of them?
Yes, we standardize both the dependent variables (answer) like the independents (predictoras) before running the linear regression model (since this is the widely accepted practice when we want to find the standardized form of the variables).
3. How to interpret standardized regression coefficients?
The interpretation of the standardized regression coefficients is not intuitive compared to their non-standardized versions:
A change of 1 standard deviation in X is associated with a change in standard deviations β of Y.
Note:
– If there is a categorical variable instead of a numeric variable in our analysis, then its standardized coefficient cannot be interpreted since it makes no sense to change X into 1 standard deviation. In general, this is not an obstacle for our model, since these coefficients are not intended to be interpreted individually, but to be compared with each other to get an idea of the relevance of each variable in the linear regression model.
The standardized coefficient is measured in units of standard deviation. A beta value of 2.25 indicates that a change of one standard deviation in the independent variable results in an increase of 2.25 standard deviations in the dependent variable.
4. What is the actual use of standardized coefficients?
They are mainly used to categorize predictors (o independent or explanatory variables) since they eliminate the units of measurement of the independent and dependent variables). We can categorize the independent variables with an absolute value of standardized coefficients. The most important variable will have the maximum absolute value of the standardized coefficient.
As an example:
Y = β0 + b1 X1 + b2 X2 + e
If the standardized coefficients β1 = 0.5 y β2 = 1, we can conclude that:
X2 is twice as important as X1 in the forecast of Y, assuming both X1 and X2 follow roughly the same distribution and their standard deviations are not that different.
5. Limitations of standardized regression coefficients
Standardized coefficients are misleading if the variables in the model have different standard deviations, it means that all variables have different distributions.
Take a look at the next linear regression equation:
Income ($) = β0 + b1 Age (years) + b2 Experience (years) + e
Because our independent variables Age and Experience are on the same scale (years) and if it is reasonable to assume that their standard deviations differ greatly, then for this case:
– Its non-standardized coefficients should be used to compare its relevance / influence on the model.
– Standardizing these variables would do, in reality, that were on a different scale (different standard deviations or follows a different distribution)
Calculation of standardized coefficients
1. For linear regression (another approach, since we see a focus in the previous part of the post)
The standardized coefficient is obtained by multiplying the non-standardized coefficient by the ratio of the standard deviations of the independent variable and the dependent variable..

2. For logistic regression

Final notes
This post covered some basic but necessary concepts when working on a real life project in machine learning and artificial intelligence.. I hope you have understood very well the concepts explained in this post. In this post in the last part, We only see the formulation related to the concepts but we do not delve much into the Mathematics behind them, We will discuss that part in some other post.
If you have any questions, Let me know in the comment section!
The media shown in this post is not the property of DataPeaker and is used at the author's discretion.





