[*]
This article was published as part of the Data Science Blogathon
Introduction
One of the main problems everyone faces when trying structured streaming for the first time is setting up the necessary environment to stream their data.. We have some online tutorials on how we can set this up. Most of them focus on asking you to install a virtual machine and ubuntu operating system and then configure all the required files by changing the bash file. This works fine, but not for everyone. Once we use a virtual machine, sometimes we may have to wait a long time if we have machines with less memory. The process could get stuck due to memory lag issues. Then, for a better way to do it and easy operation, I will show you how we can configure structured streaming in our Windows OS.
Used tools
For the configuration we use the following tools:
1. Kafka (for data transmission, acts as producer)
2. Zookeeper
3. Pyspark (to generate the transmitted data, acts as a consumer)
4. Jupyter Notebook (code editor)
Environment Variables
It is important to note that here, I have added all files in C drive. What's more, the name must be the same as that of the files you install online.
We have to set the environment variables as we install these files. Please refer to these images during installation for a hassle-free experience.
The last image is the path of the system variables.
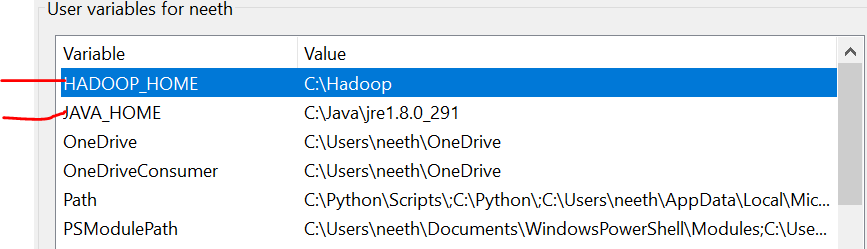
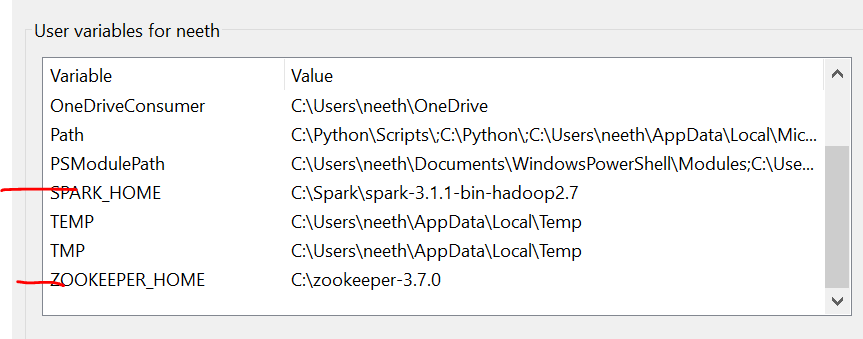
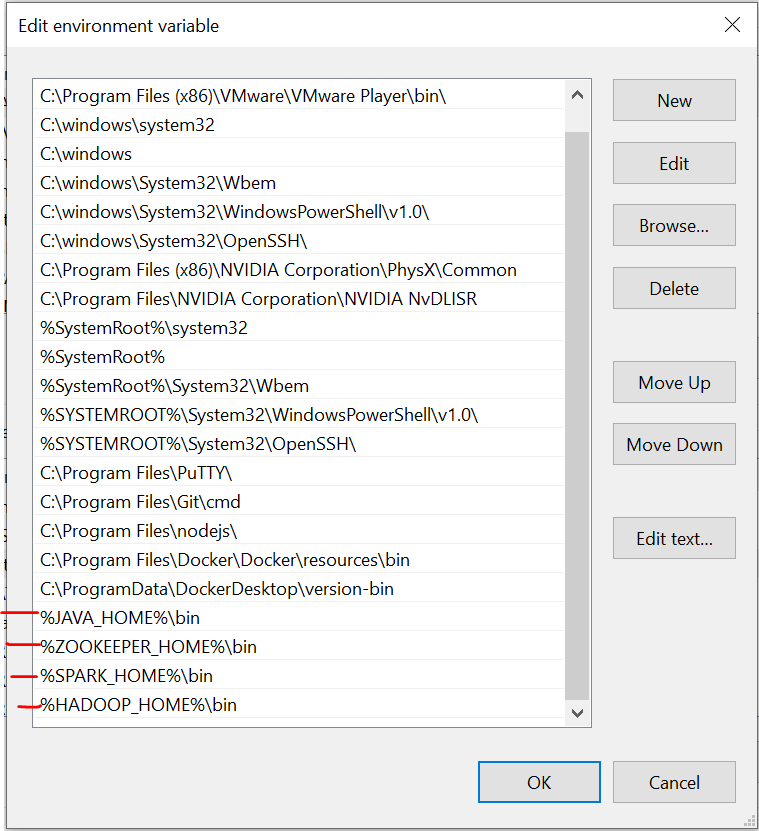
Required files
https://drive.google.com/drive/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw?usp=sharing
Kafka installation
The first step is to install Kafka on our system. For this we have to go to this link:
https://dzone.com/articles/running-apache-kafka-on-windows-os
We need to install Java 8 initially and set environment variables. You can get all the instructions from the link.
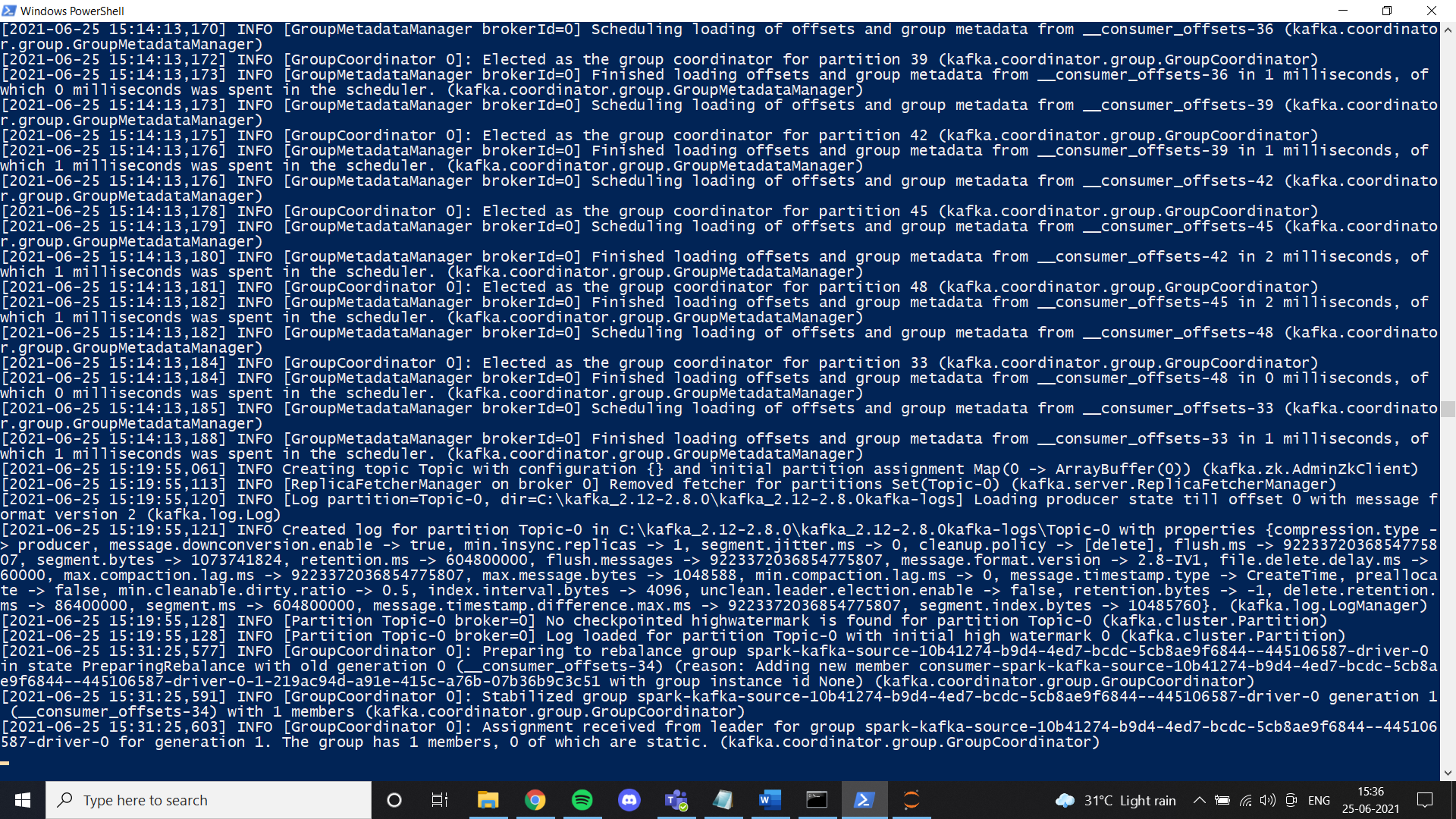
Once we are done with Java, we must install a zoo keeper. I've added zoo guardian files in Google Drive. Feel free to use it or just follow all the instructions given in the link. If you installed zookeeper correctly and configured the environment variable, you can see this result when you run zkserver as an administrator at the command prompt.
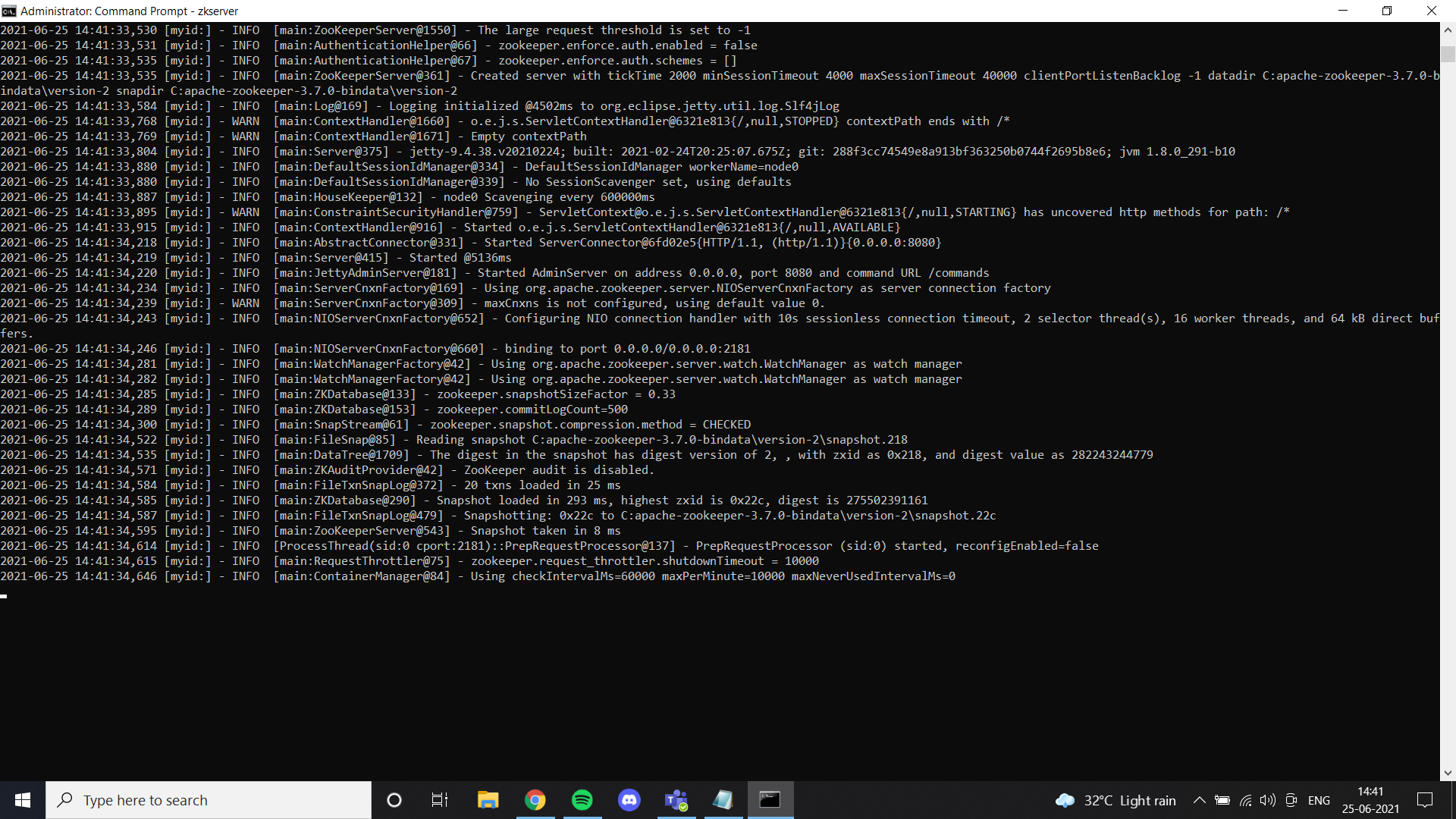
Then, install Kafka according to the link instructions and run it with the specified command.
.binwindowskafka-server-start.bat .configserver.properties
Once everything is set up, try to create a theme and check if it works properly. If so, you will have completed the Kafka installation.
Spark Installation
In this step, instalamos Spark. Basically, you can follow this link to configure Spark on your windows machine.
https://phoenixnap.com/kb/install-spark-on-windows-10
During one of the steps, it will ask for the winutils file to be configured. For your comfort, i added the file in the drive link i shared. In a folder called Hadoop. Just put that folder on your C drive and set the environment variable as shown in the images. I highly recommend that you use the Spark file that I have added to Google Drive. One of the main reasons is the data transmission we need to manually set up a structured transmission environment. In our case, I configured all the necessary things and modified the files after trying a lot. In case you want to make a new configuration, feel free to do it. If the configuration does not work correctly, we end up with an error like this when transmitting data in pyspark:
Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;Once we are one with Spark, now we can stream the required data from a CSV file in a producer and get it in a consumer using the Kafka theme. I mainly work with the Jupiter notebook and, Thus, I have used a notebook for this tutorial.
In your notebook first, you must install some libraries:
1. pip installs pyspark
2. pip installer Kafka
3. pip install py4j
How does structured streaming work with Pyspark?
We have a CSV file that has data that we want to transmit. Let's proceed with the classic Iris dataset. Now, if we want to transmit the iris data, we must use Kafka as a producer. Kafka, we create a topic to which we transmit the iris data and the consumer can retrieve the data frame of this topic.
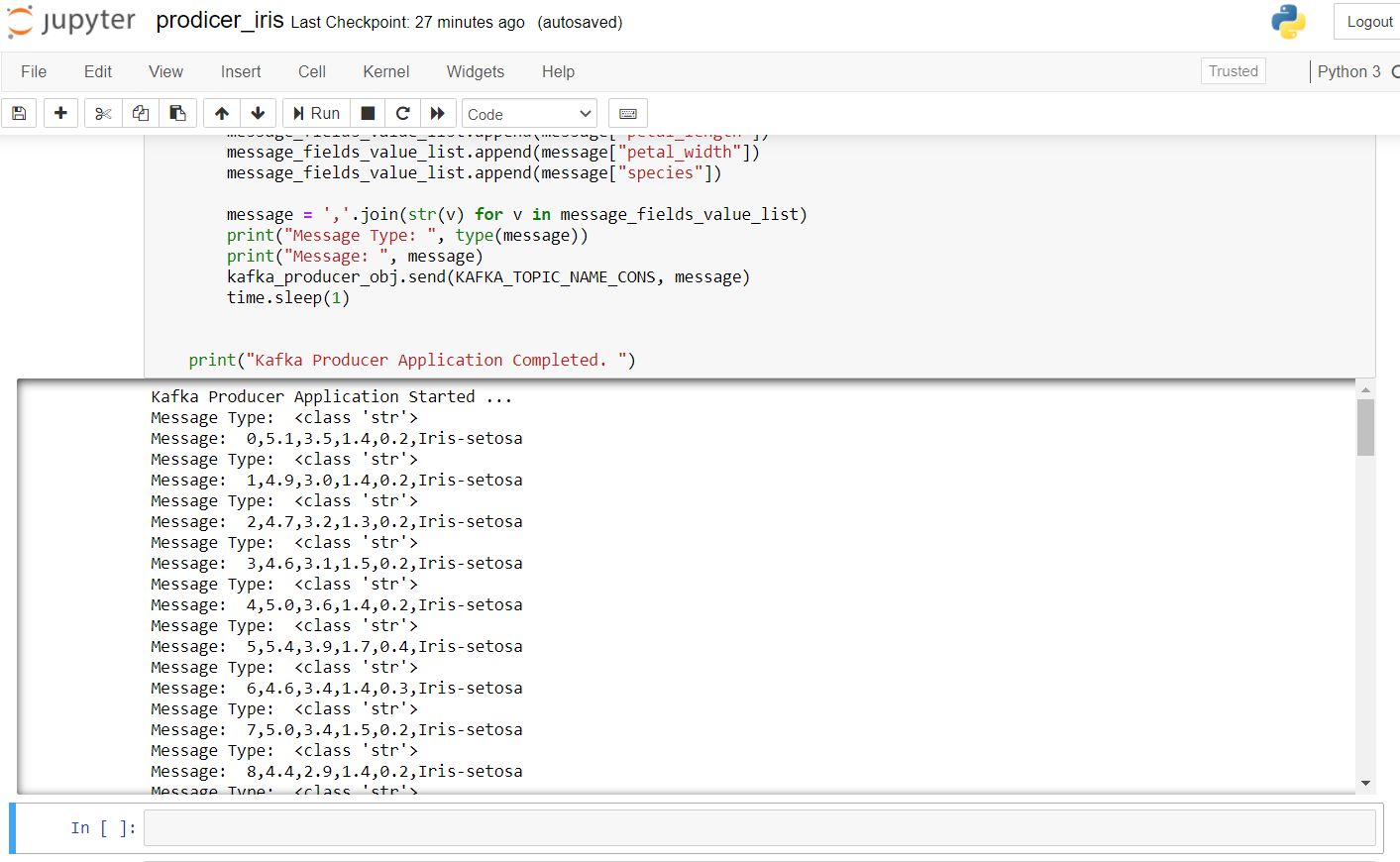
The following is the producer code for transmitting iris data:
To start the producer, we have to run zkserver as administrator at the Windows command prompt and then start Kafka using: .binwindowskafka-server-start.bat .configserver.properties from the command prompt in the Kafka directory. If you get an error from “no broker”, means that Kafka is not running properly.
the result after running this code in the jupyter binder looks like this:
Now, let's review the consumer. Run the following code to see if it works well on a new laptop.
Una vez que ejecute esto, debería obtener un resultado como este:
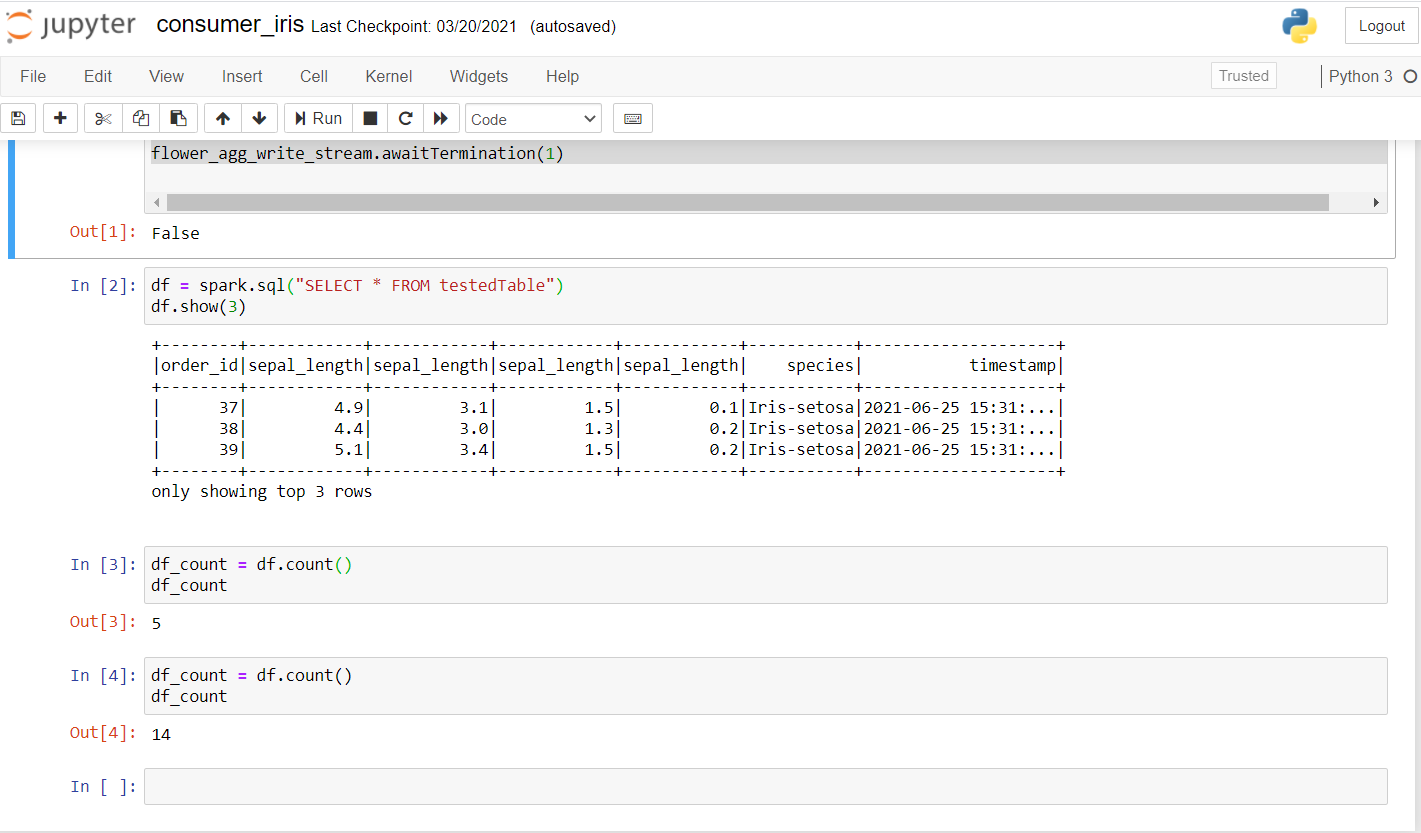
As you can see, ran a few inquiries and checked if the data was being transmitted. The first account was 5 Y, after a few seconds, the account increased to 14, confirming that data is being transmitted.
Here, basically, the idea is to create a spark context. We get the data by transmitting Kafka on our subject on the specified port. Spark session can be created using getOrCreate () as shown in the code. The next step includes reading the Kafka stream and the data can be loaded using load (). Since the data is being transmitted, it would be useful to have a timestamp in which each of the records has arrived. We specify the schema as we do in our SQL and finally create a data frame with the values of the transmitted data with its timestamp. Finally, with a processing time of 5 seconds, we can receive data in batches. We make use of SQL View to temporarily store data in memory in attached mode and we can perform all operations on it using our Spark data frame.
See the full code here:
https://github.com/Siddharth1698/Structured-Streaming-Tutorial
This is one of my Spark streaming projects, you can refer to it for more detailed queries and use of machine learning in Spark:
https://github.com/Siddharth1698/Spotify-Recommendation-System-using-Pyspark-and-Kafka
References
1. https://github.com/Siddharth1698/Structured-Streaming-Tutorial
2. https://dzone.com/articles/running-apache-kafka-on-windows-os
3. https://phoenixnap.com/kb/install-spark-on-windows-10
4. https://drive.google.com/drive/u/0/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw
5. https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
6. Thumbnail Image -> https://unsplash.com/photos/ImcUkZ72oUs
Conclution
If you follow these steps, you can easily configure all environments and run your first structured streaming program with Spark and Kafka. In case of any difficulty setting it up, Do not hesitate to contact me:
[email protected]
https://www.linkedin.com/in/siddharth-m-426a9614a/





