This article was published as part of the Data Science Blogathon
The sections of your main melody are a kind of scratches in the cobweb!! Regardless, words “web scratching” generally involve a connection that incorporates computerization. A couple of destinations could bypass it when custom debuggers collect your data, while others wouldn't care.
Hoping you are deliberately scratching a page for informational items, presumably you will have no problem. Taking into account everything, it is a good idea to do an isolated assessment and ensure that you are not ignoring the Terms of Service before starting a gigantic degree project. To get comfortable with the legal pieces of web scraping, take a look at Legal insights on data scraping from the modern web.
Why web scraping?
Just when we scratch the web, we create a code that sends a request that is working with the page we decide. The specialist will return the source code – HTML, for the most part – of the page (o pages) to which we made reference.
Until very recently, basically we are doing more than a web program: submit interest with a specific URL and mention that the specialist returns the code for that page.
In any case, unlike a web program, our web scratching code will not translate the source code of the page and will show the page ostensibly. Taking everything into account, we will think of some custom code that channels through the source code of the page looking for express parts that we have demonstrated and removing any substance that we have taught it to eliminate.
For instance, in case we expected to get the total data from inside a table that appeared on a site page, our code would be formed to follow these methods in gathering:
1 Substance application (source code) from a worker-specific URL
2 Unload the substance that is returned.
3 Distinguish the segments of the page that are fundamental to the table we need.
4 Concentrate and (if it is crucial) reformat those segments into a dataset that we can take apart or use in any way we need.
If all that sounds particularly complicated, Don't push! Python and Beautiful Soup have natural features proposed to make this for the most part immediate.
One thing that is critical to keep in mind: from a specialist's perspective, referencing a page through web scratching is comparable to stacking it in a web program. Exactly when we use code to enter these requests, we could be “stacking” pages significantly faster than a standard client, and in this way rapidly consuming the site owner's labor resources.
Web Scraping of data for machine learning:
In case you scrape the data for AI, promise you have verified low concentrations before approaching data extraction.
Data format:
Simulated intelligence models can simply abruptly increase the popularity of data that is in a simple or table-like association. In this sense, scraping unstructured data will require, this way, greater freedom to care for data before it can be used.
Data list:
Since the key objective is artificial intelligence, when you have the locations or pages of the web page that you want to delete, you should make an overview of the data centers or data sources you want to remove from each page of the site. If the case is with the end goal of missing a large number of data centers for each page of the site, then you have to cut back and choose the data centers that are usually present. The reason for this is that so many NA or empty features will decrease the presentation and accuracy of the AI model. (ML) that trains and tests with the data.
Data labeling:
Fact-checking can be brain agony. In any case, if you can accumulate the necessary metadata while the data is scratched and store it as an alternate data point, will benefit the corresponding stages in the data life cycle.
Clean up, prepare and store data
While this move may seem fundamental, is usually perhaps the most tangled and sad advance. This is the direct result of a clear clarification: there is no one-size-fits-all connection. It depends on what data you have deleted and where you have deleted it from. You will need quick strategies to clean the data.
Most importantly, you need to review the data to understand what degradations are found in the data sources.. You can do this using a library like Pandas (available in python). At the time your evaluation is done, you must create a substance to eliminate deformities in data sources and normalize data centers that are not like the others. Later, would run big checks to check if the data centers have all the data in a singular data type. A fragment that should contain numbers cannot have a data line. For instance, one that should contain data in dd config / mm / yyyy cannot contain data in some other association. Apart from these plan checks, missing features, the invalid characteristics and anything else that may break the data processing, must be perceived and corrected.
Why Python for Web Scraping?
Python is a known device for executing web scratching. The Python programming language is also used for other valuable activities identified with network security, entrance tests as well as advanced measurable applications. Using basic Python programming, web scraping can be done without using any other external device.
The Python programming language is gaining immense prevalence and the reasons that make Python a solid match for web scratching projects are as follows:
Scoring simplicity
Python has the simplest construction compared to other programming dialects. This Python element simplifies testing and an engineer can focus on additional programming.
Built-in modules
Another justification for using Python to scratch on the web is the incorporation of the valuable external libraries it has. We can perform numerous executions identified with web scratching using Python as the basis for programming.
Open source programming language
Python has great help from the local area as it is an open source programming language.
Wide range of applications
Python can be used for different programming assignments ranging from small shell contents to large enterprise web applications.
Python modules for web scraping
Web scraping is the path to developing a specialist who can extract, analyze, download and coordinate valuable data from the web accordingly. At the end of the day, instead of physically saving the information of the sites, web scratching programming will load and concentrate information from different sites according to our prerequisite.
Application
It's a simple Python web scratch library. It is a powerful HTTP library used to access pages. With the help of Requests, we can get the raw HTML from the site pages which could then be parsed to retrieve the information.
Beautiful soup
Beautiful Soup is a Python library for extracting information from HTML and XML records. Tends to be used with demands, since you need a piece of information (report the URL) to make a soup object, since you can't fetch a page from the site without the help of anyone else. You can use attached python content to assemble the page title and hyperlinks.
Code –
import urllib.request from urllib.request import urlopen, Request from bs4 import BeautifulSoup wiki= "https://www.thestar.com.my/search/?q=HIV&qsort=oldest&qrec=10&qstockcode =&pgno = 1" html=urlopen(wiki) bs= BeautifulSoup(html,'lxml') bs Beautiful Soup is used to extract the website page
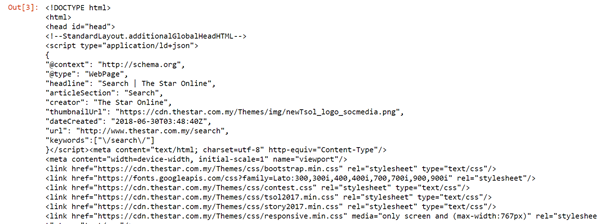
(image source: jupyter notebook)
Code-
from bs4 import BeautifulSoup
base_url="https://www.thestar.com.my/search/?q=HIV&qsort=oldest&qrec=10&qstockcode =&pgno ="
# Add 1 because Python range.
url_list = ["{}{}".format(base_url, str(page)) for page in range(1, 408)]
s=[]
for url in url_list:
print (url)
s.append(url)
Production-
The above code will list the number of web pages in the range of 1 a 407.
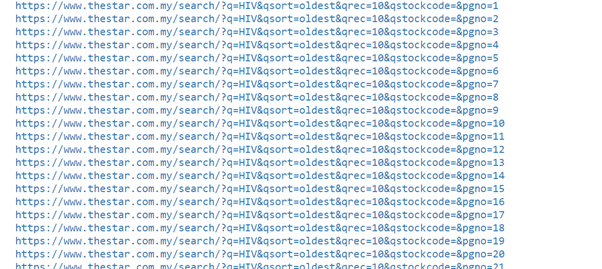
(image source: jupyter notebook)
Code –
data = []
data1= []
import csv
from urllib.request import urlopen, HTTPError
from datetime import datetime, timedelta
for pg in s:
# query the website and return the html to the variable 'page'
page = urllib.request.urlopen(pg)
try:
search_response = urllib.request.urlopen(pg)
except urllib.request.HTTPError:
pass
# parse the html using beautiful soap and store in variable `soup`
soup = BeautifulSoup(page, 'html.parser')
# Take out the <div> of name and get its value
ls = [x.get_text(strip=True) for x in soup.find_all("h2", {"class": "f18"})]
ls1 = [x.get_text(strip=True) for x in soup.find_all("span", {"class": "date"})]
# save the data in tuple
data.append((ls))
data1.append(ls1)
Production-
The above code will take all the data with the help of a beautiful soup and save it in the tuple.
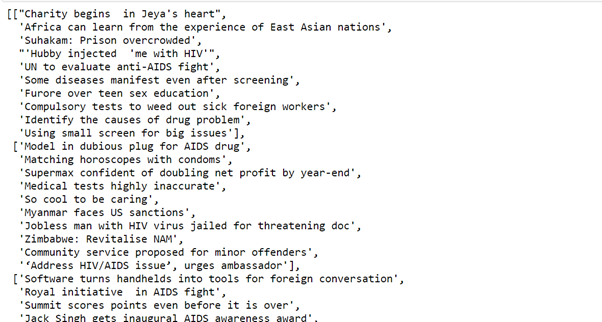
(image source: jupyter notebook)
Code
import pandas as p df=p.DataFrame(f,columns=['Topic of article']) df['Date']= f1
Production-
Pandas
Pandas is a fast open source information research and control instrument, amazing, adaptable and simple to use, based on top of the Python programming language.
The above code stores the value in the data frame.

(image source: jupyter notebook)
Hope you enjoy the code.
Small introduction
Me, Sonia Singla, I have done a master's degree in bioinformatics from the University of Leicester, United Kingdom. I have also done some projects on data science from CSIR-CDRI. He is currently an advisory member of the editorial board of IJPBS.
Linkedin – https://www.linkedin.com/in/soniasinglabio/
Media shown in this article about implementing machine learning models that take advantage of CherryPy and Docker is not the property of DataPeaker and is used at the author's discretion.





