Intro:
unstructured data in a structured format? This is where Web Scraping comes in..
What is Web Scraping?
In plain language, Web scraping, web harvest, O web data extraction is an automated big data collection process (unstructured) of websites. The user can extract all the data on particular sites or the specific data according to the requirement. The collected data can be stored in a structured format for further analysis.
Uses of web scraping:
In the actual world, web scraping has gained a lot of attention and has a wide range of uses. Some of them are listed below:
- Social Media Sentiment Analysis
- Lead generation in the marketing domain
- Market analysis, online price comparison in the e-commerce domain
- Recopile datos de trainingTraining is a systematic process designed to improve skills, physical knowledge or abilities. It is applied in various areas, like sport, Education and professional development. An effective training program includes goal planning, regular practice and evaluation of progress. Adaptation to individual needs and motivation are key factors in achieving successful and sustainable results in any discipline.... y prueba en aplicaciones de aprendizaje automático
Steps involved in web scraping:
- Find the URL of the web page you want to scrape
- Select particular items by inspecting
- Writes the code to get the contents of the selected items
- Store data in the required format
That simple guys! .. !!
Libraries / Popular tools that are used for web scraping are:
- Selenium: a framework for testing web applications
- BeautifulSoup: Python library for getting HTML data, XML and other markup languages
- Pandas: Python library for data manipulation and analysis
In this article, we will create our own dataset by extracting Domino's Pizza reviews from the website. consumeraffairs.com/food.
We will use requests Y Beautiful soup by scraping and analysis the data.
Paso 1: find the URL of the web page you want to scrape
Open the URL “consumeraffairs.com/food"And search for Domino's Pizza in the search bar and press Enter.
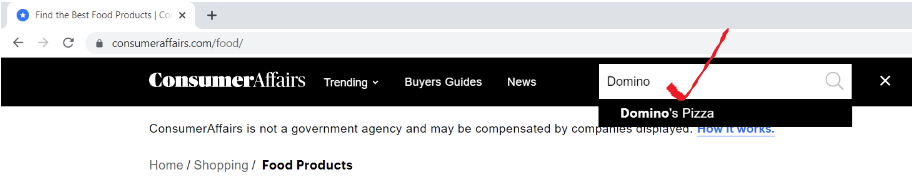
Below is what our reviews page looks like.
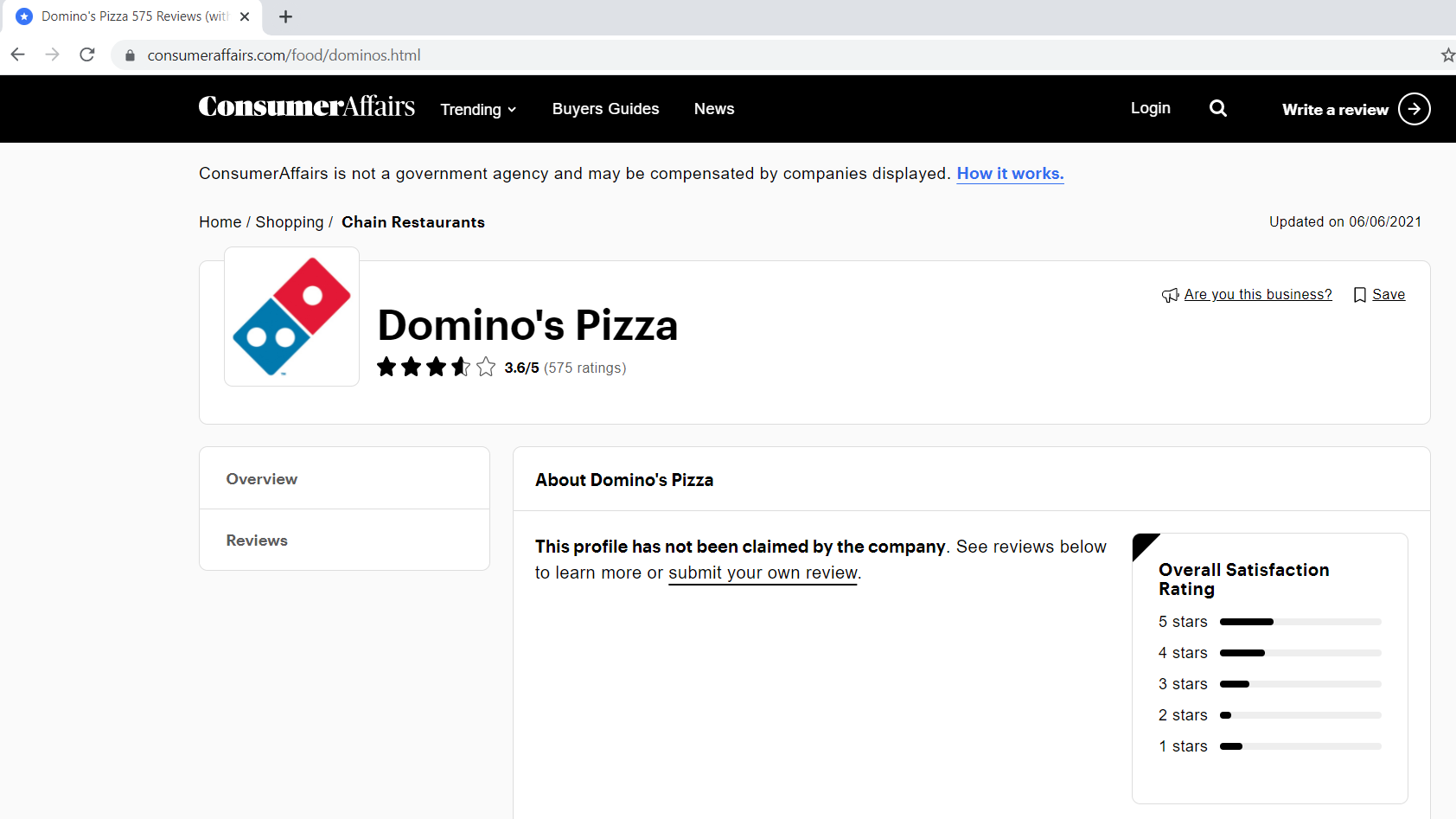
Paso 1.1: Defining the base URL, parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project.... de consulta
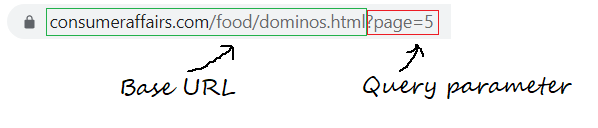
The base URL is the consistent part of your web address and represents the path to the website's search function.
base_url = "https://www.consumeraffairs.com/food/dominos.html?page="
query parameters represent additional values that can be declared on the page.
query_parameter = "?page="+str(i) # i represents the page number
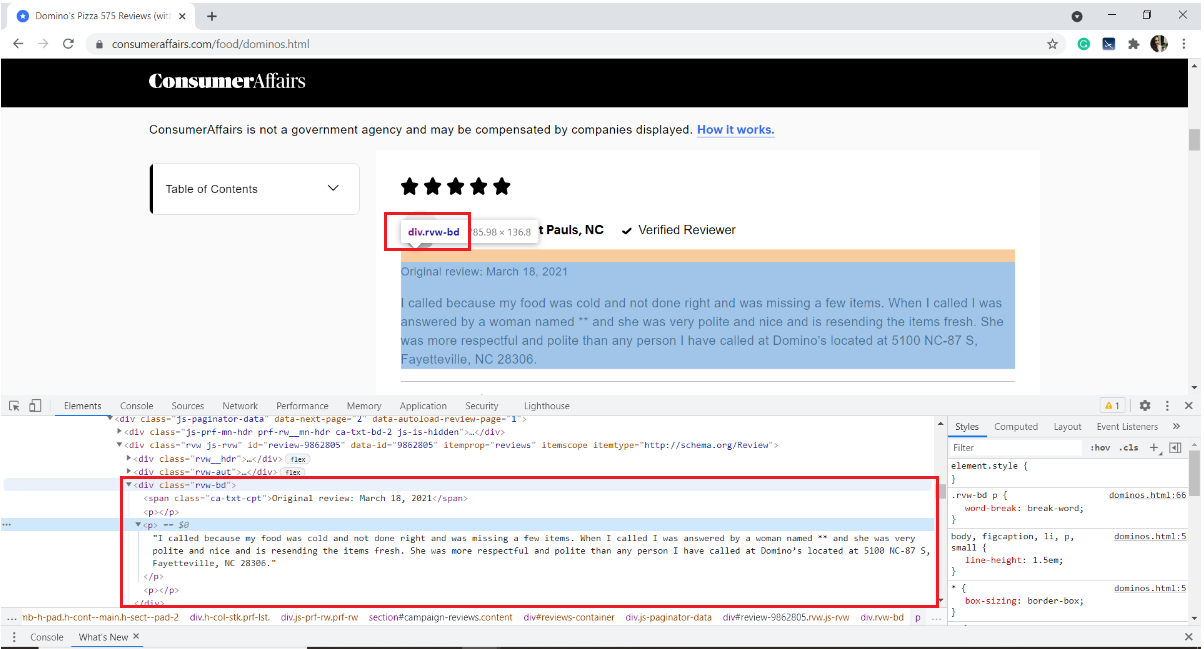
Paso 2: select particular items by inspecting
Below is an image of a sample review. Each review has many elements: the rating given by the user, the username, the date of the review and the text of the review along with some information about how many people you liked.

Our interest is to extract only the text of the review. For that, we need to inspect the page and get the HTML tags, the attribute names of the target element.
To inspect a web page, right-click the page, select Inspect or use the keyboard shortcut Ctrl + Shift + I.
In our case, the revision text is stored in the html tag
of the div with the class name "rvw-bd“
With this, we get acquainted with the website. Let's quickly jump to scraping.
Paso 3: Writes the code to get the contents of the selected items
Start by installing the modules / required packages
pip install pandas requests BeautifulSoup4
Import required libraries
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
pandas – to create a data frame
requests: to send HTTP requests and access HTML content from the destination web page
BeautifulSoup: is a Python library for parsing structured HTML data
Create an empty list to store all extracted reviews
all_pages_reviews = []
define a scraper function
def scraper():
Inside the scraper function, type a for the loop to run through the number of pages you would like to scrape. I'd like to scrape the five-page reviews.
for i in range(1,6):
Creando una lista vacía para almacenar las reseñas de cada página (of 1 a 5)
pagewise_reviews = []
Construye la URL
url = base_url + query_parameter
Envíe la solicitud HTTP a la URL mediante solicitudes y almacene la respuesta
response = requests.get(url)
Cree un objeto de sopa y analice la página HTML
soup = bs(response.content, 'html.parser')
Encuentre todos los elementos div del nombre de clase “rvw-bd” y guárdelos en una variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena....
rev_div = soup.findAll("div",attrs={"class","rvw-bd"})
Recorra todo el rev_div y agregue el texto de revisión a la lista pagewise
for j in range(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[j].find("p").text)
Anexar todas las reseñas de páginas a una sola lista “all_pages about”
for k in range(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[k])
Al final de la función, devuelve la lista final de reseñas.
return all_pages_reviews
Call the function scraper() and store the output to a variable 'reviews'
# Driver code
reviews = scraper()
Paso 4: almacene los datos en el formato requerido
4.1 almacenamiento en un marco de datos de pandas
i = range(1, len(reviews)+1) reviews_df = pd.DataFrame({'review':reviews}, index=i)
Now let us take a glance of our dataset
print(reviews_df)

4.2 Escribir el contenido del marco de datos en un archivo de texto
reviews_df.to_csv('reviews.txt', sep = 't')
With this, terminamos de extraer las reseñas y almacenarlas en un archivo de texto. Mmm, es bastante simple, ¿no?
Código Python completo:
# !pip install pandas requests BeautifulSoup4
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
base_url = "https://www.consumeraffairs.com/food/dominos.html"
all_pages_reviews =[]
-
def scraper(): for i in range(1,6): # fetching reviews from five pages pagewise_reviews = [] query_parameter = "?page="+str(i) url = base_url + query_parameter response = requests.get(url) soup = bs(response.content, 'html.parser') rev_div = soup.findAll("div",attrs={"class","rvw-bd"}) for j in range(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[j].find("p").text) for k in range(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[k]) return all_pages_reviews # Driver code reviews = scraper() i = range(1, len(reviews)+1) reviews_df = pd.DataFrame({'review':reviews}, index=i) reviews_df.to_csv('reviews.txt', sep = 't')
Final notes:
At the end of this article, we have learned the step-by-step process of extracting content from any web page and storing it in a text file.
- inspect the target item using the browser's development tools
- use requests to download HTML content
- parsing HTML content using BeautifulSoup to extract the required data
We can further develop this example by scraping usernames, reviewing text. Vectorize clean revision text and group users according to written revisions. Podemos usar Word2Vec o CounterVectorizer para convertir texto en vectores y aplicar cualquiera de los algoritmos de groupingThe "grouping" It is a concept that refers to the organization of elements or individuals into groups with common characteristics or objectives. This process is used in various disciplines, including psychology, Education and biology, to facilitate the analysis and understanding of behaviors or phenomena. In the educational field, for instance, Grouping can improve interaction and learning among students by encouraging work.. de Machine Learning.
References:
Biblioteca BeautifulSoup: Documentation, Video Tutorial
GitHub repository link to download source code
I hope this blog helps to understand web scraping in Python using the BeautifulSoup library. Happy learning !! 😊
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





