This article was published as part of the Data Science Blogathon.
Introduction

Web Scraping is a method or art to obtain or delete data from the Internet or websites and store it locally on your system. Web Scripting is a programmed strategy to acquire a lot of information from sites.
The vast majority of this information is unstructured information in an HTML layout that is later converted into organized information in an accounting page or data set., so it tends to be used in different applications. There is a wide range of approaches to web scraping to obtain information from sites. These include the use of web applications, specific API o, in any case, make your code for web scraping without any preparation.
Numerous huge sites like Google, Twitter, Facebook, StackOverflow, etc. have APIs that allow you to access your information in an organized organization. This is the most ideal option, but different locale settings do not allow clients to access much information in an organized structure or, in essence, they do not progress so mechanically. Over there, it is ideal to use Web Scraping to find information on the site.

Web Scrapers can extract all the information about specific destinations or the particular information that a customer needs. Preferably, it is ideal if you indicate the information you need so that the web scraper simply concentrates that information quickly. For instance, you should scratch an Amazon page for the types of juicers available, but nevertheless, You may only need the information about the models of various juicers and not the customer audits.
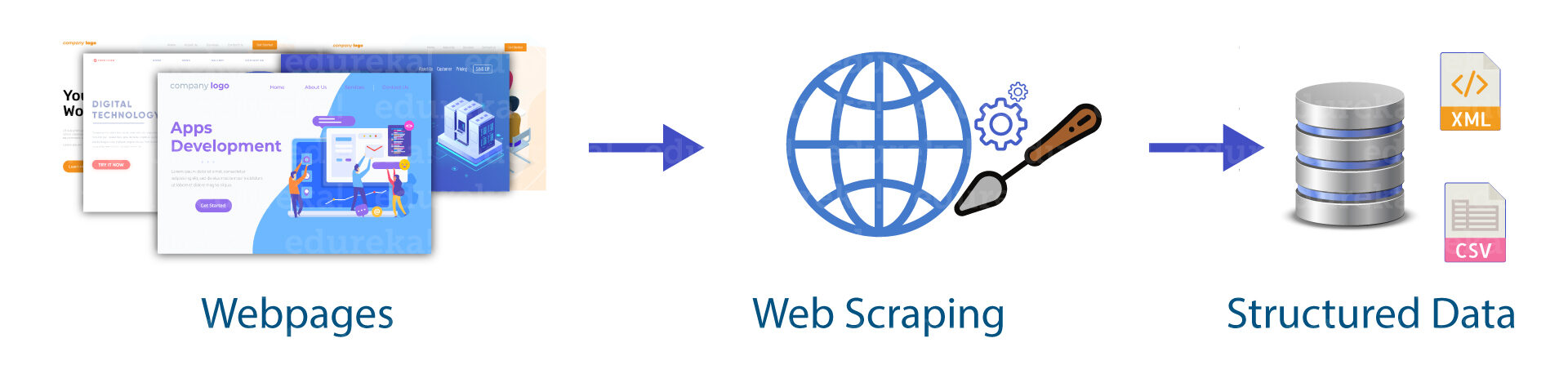
Then, when a web debugger needs to scratch a website, first you are provided with the URLs of the required locales. At that point, stack all the HTML code for those destinations and a more developed scraper can even concentrate all the CSS and Javascript components as well. At that point, the scraper acquires the necessary information from this HTML code and transfers this information to the organization indicated by the client.
Generally, this is like an excel accounting page or a csv record, but nevertheless, information can also be stored in different organizations, for instance, a JSON document.

Popular Python libraries for web scraping
- Petitions
- Beautiful soup 4
- lxml
- Selenium
- Scrapy
AutoScraper
It is a Python web scraping library to make web scraping smart, automatic, quick and easy. It is also lightweight, which means it won't affect your PC much. A user can easily use this data scraping tool due to its user-friendly interface.. To start, you just need to write a few lines of code and you will see the magic.
You just need to provide the URL or HTML content of the web page you want to remove data from, what's more, a summary of the test information that we should remove from that page. This information can be text, URL or any HTML tag on that page. Learn scratch rules on its own and return similar items.
In this article, we will investigate Autoscraper and see how we can use it to remove information from us.

Installation
There is 3 ways to install this library on your system.
- Install from git repository using pip:
pip install git+https://github.com/alirezamika/autoscraper.git
pip install autoscraper
python setup.py install
Importing library
We will only import an automatic scraper, as it is suitable only for web scratching. Below is the code to import:
from autoscraper import AutoScraper
Definition of web scraping function
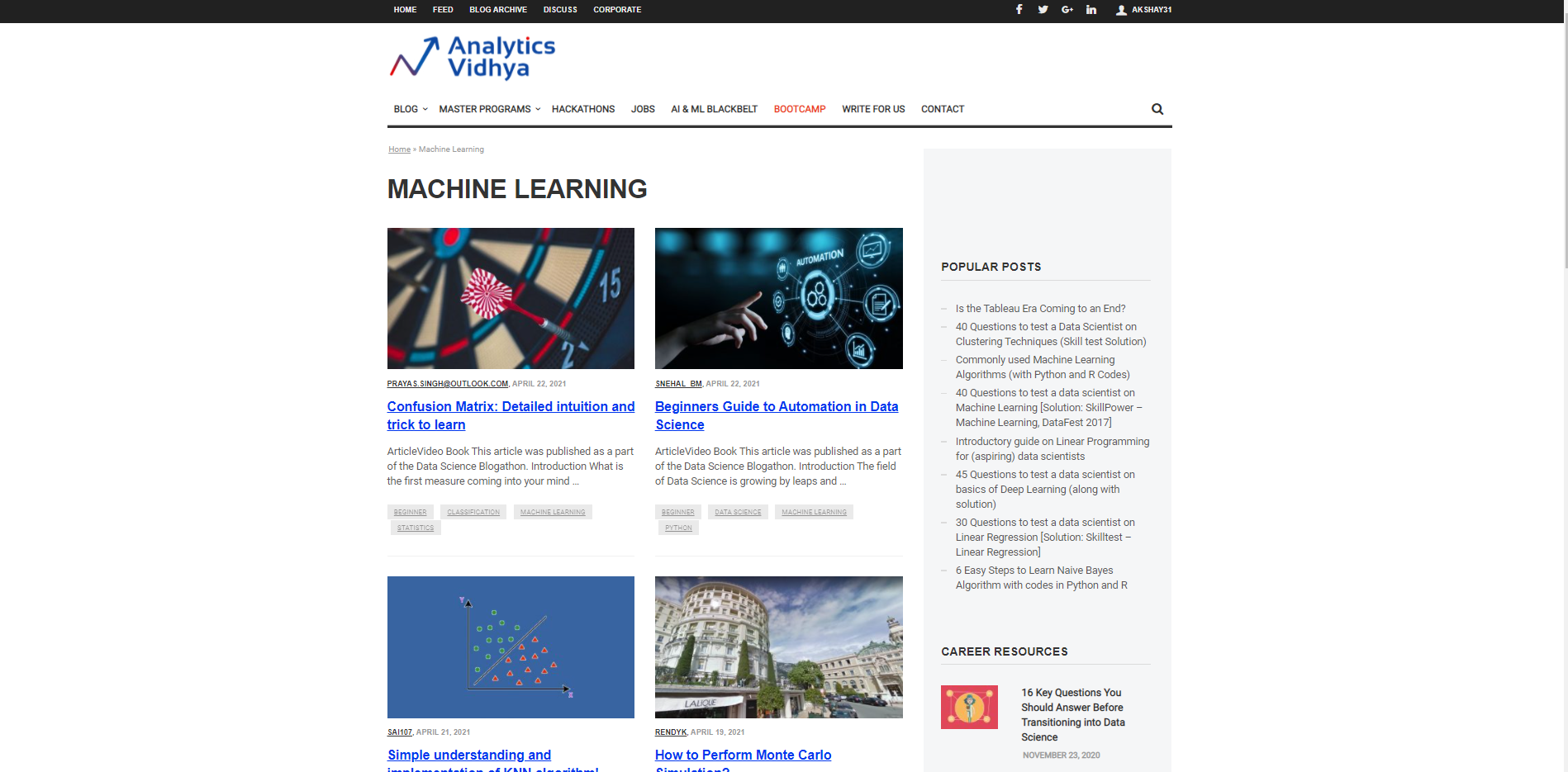
Let us start by characterizing a URL from which it will be used to bring in the information and proof of necessary information to be brought. Suppose we want to search for the Titles for different articles about Machine Learning on the DataPeaker website. Therefore, we have to pass the URL of the DataPeaker machine learning blog section and the second wanted list. The wanted list is a list that is Sample data that we want to extract from that page. For instance, here the wanted list is a title of any blog in DataPeaker's machine learning blog section.
url="https://www.analyticsvidhya.com/blog/category/machine-learning/" wanted_list = ['Confusion Matrix: Detailed intuition and trick to learn']
We can add one or more candidates to the wanted list. You can also put URLs in the wanted list to retrieve the URLs.
Start the AutoScraper
The next step after starting the URL and the wanted list is to call the AutoScraper function. Our goal is to use this feature to build the scraper model and perform web scraping on that particular page.
This can be started using the following code:
scraper = AutoScraper()
Building the Object
This is the final step in web scraping with this particular library. Here, create the object and show the result of the web scraping.
scraper = AutoScraper() result = scraper.build(url, wanted_list) print(result)

Here, in the picture above, you can see it comes back. the title of the blogs on the DataPeaker website in the machine learning section, similarly, we can get the URLs of the blogs by simply passing the sample url in the wanted list we defined earlier.
url="https://www.analyticsvidhya.com/blog/category/machine-learning/" wanted_list = ['https://www.analyticsvidhya.com/blog/2021/04/confusion-matrix-detailed-intuition-and-trick-to-learn/'] scraper = AutoScraper() result = scraper.build(url, wanted_list) print(result)
Here is the output of the above code. You can see that I have passed the url in the wanted list this time, as a result, you can see the result as blog urls

Save the model
It allows us to save the model that we have to build to be able to reload it when necessary.
To save the model, use the following code
scraper.save('blogs') #Give it a file path
To load the model, use the following code:
scraper.load('blogs')
Note: Apart from each of these functionalities, the automatic scraper also allows you to characterize proxy IP addresses so that you can use them to obtain information. We simply need to characterize the proxies and pass them as an argument to the build function as shown below:
proxies = {
"http": 'http://127.0.0.1:8001',
"https": 'https://127.0.0.1:8001',
}
result = scraper.build(url, wanted_list, request_args=dict(proxies=proxies))
For more information, check the link below: AutoScraper
Conclution
In this article, we perceive how we can use Autoscraper for web scraping by making a basic and simple to use model. We saw several formats in which information can be retrieved using Autoscraper. We can also save and load the model to use it later, which saves time and effort. Autoscraper is amazing, easy to use and efficient.
Thank you for reading this article and for your patience.. Leave me in the comment section about comments. Share this article, it will give me the motivation to write more blogs for the data science community.
Email identification: gakshay1210@ gmail.com
Follow me on LinkedIn: LinkedIn
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





