
Stage 1: Any global bank today has more than 100 millions of customers making billions of transactions each month.
Stage 2: Social media websites or e-commerce websites track customer behavior on the website and then provide information / relevant product.
Traditional systems struggle to cope with this scale at the required rate in a cost-effective manner.
This is where Big Data platforms come to help.. In this article, we present to you the fascinating world of Hadoop. Hadoop is useful when dealing with huge data. It may not make the process faster, but it gives us the ability to use parallel processing power to handle big data. In summary, Hadoop gives us the ability to deal with the complexities of high volume, speed and variety of data (popularly known as 3V).
Note that, in addition to Hadoop, there are other big data platforms, for instance, NoSQL (MongoDB is the most popular), we will see them later.
Introduction to Hadoop
Hadoop is a complete ecosystem of open source projects that provides us with the framework for dealing with big data. Let's start by brainstorming the potential challenges of dealing with big data (in traditional systems) and then let's see the capacity of the Hadoop solution.
The following are the challenges I can think of when dealing with big data:
1. High capital investment in acquiring a server with high processing capacity.
2. Huge time invested
3. In case of a long query, imagine an error occurs in the last step. You will waste a lot of time doing these iterations.
4. Difficulty generating queries about the program
Here's how Hadoop solves all these problems:
1. Large capital investment in acquiring a high-throughput server: Hadoop clusters run on normal basic hardware and maintain multiple copies to ensure data reliability. A maximum of 4500 machines together using Hadoop.
2. Huge time invested : The process is divided into parts and runs in parallel, saving time. A maximum of 25 Petabytes (1 PB = 1000 TB) data using Hadoop.
3. In case of a long query, imagine an error occurs in the last step. You will waste a lot of time doing these iterations : Hadoop backs up data sets at all levels. Also runs queries on duplicate data sets to avoid loss of process in case of individual failure. These steps make Hadoop processing more precise and accurate.
4. Difficulty generating queries about the program : Queries in Hadoop are as simple as coding in any language. You just need to change the way you think about creating a query to allow parallel processing.
Hadoop Background
With an increase in internet penetration and internet usage, data captured by Google increased exponentially year over year. Just to give you an estimate of this number, in 2007 Google collected an average of 270 PB of data every month. The same number increased to 20000 PB every day in 2009. Obviously, Google needed a better platform to process such huge data. Google implementó un modelo de programación llamado MapReduceMapReduce is a programming model designed to efficiently process and generate large data sets. Powered by Google, This approach breaks down work into smaller tasks, which are distributed among multiple nodes in a cluster. Each node processes its part and then the results are combined. This method allows you to scale applications and handle massive volumes of information, being fundamental in the world of Big Data...., that could process these 20000 PB per day. Google ran these MapReduce operations on a special file system called Google File System (GFS). Regrettably, GFS is not open source.
Doug Cutting y Yahoo! realizó ingeniería inversa del modelo GFS y construyó un Distributed File SystemA distributed file system (DFS) Allows storage and access to data on multiple servers, facilitating the management of large volumes of information. This type of system improves availability and redundancy, as files are replicated to different locations, reducing the risk of data loss. What's more, Allows users to access files from different platforms and devices, promoting collaboration and... Hadoop (HDFSHDFS, o Hadoop Distributed File System, It is a key infrastructure for storing large volumes of data. Designed to run on common hardware, HDFS enables data distribution across multiple nodes, ensuring high availability and fault tolerance. Its architecture is based on a master-slave model, where a master node manages the system and slave nodes store the data, facilitating the efficient processing of information..) parallel. The software or framework that supports HDFS and MapReduce is known as Hadoop. Hadoop is open source and distributed by Apache.
Maybe you are interested: Introduction to MapReduce
Hadoop Processing Framework
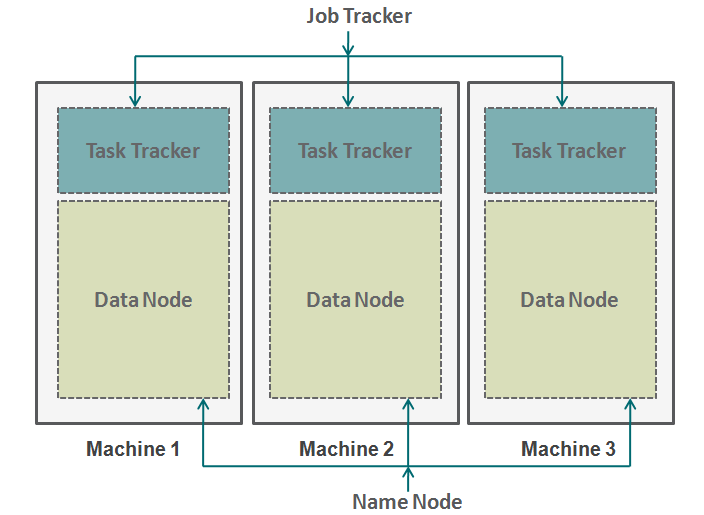
Let's draw an analogy from our daily life to understand how Hadoop works. The base of the pyramid of any company is the people who are individual taxpayers. They can be analysts, programmers, manual labor, chefs, etc. Managing your work is the project manager. The project manager is responsible for the successful completion of the task. Need to distribute labor, smooth the coordination between them, etc. What's more, most of these companies have a personnel manager, who is more concerned with retaining the squad.

Hadoop works in a similar format. At the bottom we have the machines arranged in parallel. These machines are analogous to the individual taxpayer in our analogy. Cada máquina tiene un nodeNodo is a digital platform that facilitates the connection between professionals and companies in search of talent. Through an intuitive system, allows users to create profiles, share experiences and access job opportunities. Its focus on collaboration and networking makes Nodo a valuable tool for those who want to expand their professional network and find projects that align with their skills and goals.... de datos y un rastreador de tareas. The data node is also known as HDFS (Hadoop Distributed File SystemThe Hadoop Distributed File System (HDFS) is a critical part of the Hadoop ecosystem, Designed to store large volumes of data in a distributed manner. HDFS enables scalable storage and efficient data management, splitting files into blocks that are replicated across different nodes. This ensures availability and resilience to failures, facilitating the processing of big data in big data environments....) and task tracker is also known as map shrinkers.
The data node contains the entire dataset and the task tracker performs all the operations. You can imagine the task tracker as your arms and legs, allowing you to perform a task and data node as your brain, containing all the information you want to process. These machines are working in silos and it is very important to coordinate them. Task Trackers (project manager in our analogy) on different machines are coordinated by a job tracker. Job Tracker**Job Tracker: Una Herramienta Esencial para la Búsqueda de Empleo** Job Tracker es una plataforma diseñada para facilitar la búsqueda de empleo, permitiendo a los usuarios organizar y seguir sus solicitudes de trabajo. Con características como la gestión de currículums, alertas de nuevas ofertas y análisis de tendencias laborales, Job Tracker ayuda a los solicitantes a optimizar su proceso de búsqueda y aumentar sus posibilidades de éxito en el competitivo... se asegura de que cada operación se complete y si hay una falla en el proceso en cualquier nodo, you need to assign a duplicate task to some task tracker. The job tracker also distributes the entire task to all machines.
Secondly, a named node coordinates all data nodes. It governs the distribution of data that goes to each machine. It also verifies any type of purge that has occurred in a machine. If such debugging occurs, finds duplicate data that was sent to another data node and duplicates it again. You can think of this name node as the people manager in our analogy, that cares more about the retention of the entire dataset.
When not to use Hadoop?
Up to now, we've seen how Hadoop has made big data handling possible. But in some scenarios Hadoop implementation is not recommended. Below are some of those scenarios:
- Low latency data access: quick access to small pieces of data
- Modification of multiple data: Hadoop is best suited only if we are primarily concerned with reading data and not writing data.
- Many small files: Hadoop fits better in scenarios, where we have few but large files.
Final notes
This article gives you an insight into how Hadoop comes to the rescue when dealing with huge data. Understanding how Hadoop works is very essential before you start coding it. This is because you need to change the way you think of a code. Now you need to start thinking about enabling parallel processing. You can perform many different types of processes in Hadoop, but you need to convert all these codes into a map reduction function. In the next articles, we will explain how you can convert your simple logic to Hadoop based Map-Reduce logic. We will also take specific R language case studies to build a solid understanding of the Hadoop application..
Was the article helpful to you? Share with us any practical Hadoop applications you have come across at work. Let us know your thoughts on this item in the box below..





