Overview
- Hadoop is among the most popular tools in the data engineering and Big Data space
- Here's an introduction to everything you need to know about the Hadoop ecosystem.
Introduction
Nowadays, we have more than 4 1 billion Internet users. In terms of raw data, this is what the picture looks like:
9.176 Tweets per second
1.023 Instagram images uploaded per second
5.036 Skype calls per second
86,497 Google searches per second
86,302 YouTube videos viewed per second
2.957.983 Emails sent per second
and much more…
That is the amount of data we are dealing with at the moment: amazing! It is estimated that at the end of 2020 will have produced 44 zettabytes of data. That's 44 * 10 ^ 21!
This huge amount of data generated at a fierce rate and in all kinds of formats is what today we call Big Data. But it is not feasible to store this data in the traditional systems that we have been using for more than 40 years. To handle this big data, we need a much more complex framework consisting of not just one, but in multiple components that handle different operations.

We refer to this framework as Hadoop and along with all of its components, we call it Hadoop Ecosystem. But because there are so many components within this Hadoop ecosystem, sometimes it can be really challenging to really understand and remember what each component does and where it fits in this big world.
Then, in this article, we will try to understand this ecosystem and break down its components.
Table of Contents
- Problem with traditional systems
- What is Hadoop?
- Components of the Hadoop ecosystem
- HDFS (Hadoop distributed file system)
- Small map
- HILO
- HBase
- Pork
- Hive
- Sqoop
- Artificial canal
- Kafka
- Zookeeper
- Spark – spark
- Stages of Big Data processing
Problem with traditional systems
By traditional systems, I mean systems like relational databases and data warehouses. Organizations have been using them for the past 40 years to store and analyze your data. But the data that is generated today cannot be handled by these databases for the following reasons:
- Most of the data generated today is semi-structured or unstructured. But traditional systems have been designed to handle only structured data that has well-designed rows and columns.
- Relationship databases are vertically scalable, which means you need to add more processing, memory and storage to the same system. This can be very expensive
- The data stored today is in different silos. Collecting them and analyzing them for patterns can be a very difficult task.
Then, How do we handle Big Data? This is where Hadoop comes in!!
What is Hadoop?
People at Google also faced the challenges mentioned above when they wanted to rank pages on the internet.. They found relational databases to be very expensive and inflexible. Then, came up with their own novel solution. They created the Google file system (GFS).
GFS is a distributed file system that overcomes the drawbacks of traditional systems. Runs on inexpensive hardware and provides parallelization, scalability and reliability. This set the springboard for the evolution of Apache Hadoop.
Apache Hadoop is an open source framework based on Google's filesystem that can handle big data in a distributed environment.. This distributed environment is made up of a group of machines working closely together to give the impression of a single machine in operation..
Here are some of the important Hadoop properties you should know about:
- Hadoop is highly scalable because it handles the data in a distributed way
- Compared to vertical scaling in RDBMS, Hadoop offers horizontal scale
- Create and save data replicas by doing so fault tolerant
- Is economic since all the cluster nodes are basic hardware that is nothing more than cheap machines
- Hadoop uses the data locality concept to process the data on the nodes where it is stored instead of moving the data across the network, thus reducing traffic
- May handle any kind of data: structured, semi-structured and unstructured. This is extremely important today because most of our data (emails, Instagram, Twitter, IoT devices, etc.) do not have a defined format.
Now, Let's look at the components of the Hadoop ecosystem.
Components of the Hadoop ecosystem
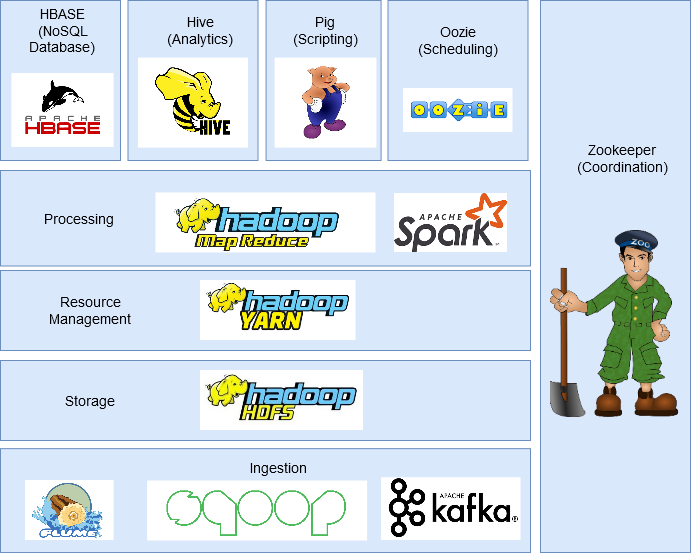
In this section, we will discuss the different components of the Hadoop ecosystem.
HDFS (Hadoop distributed file system)

It is the storage component of Hadoop that stores data in the form of files.
Each file is divided into blocks of 128 MB (configurable) and stores them on different machines in the cluster.
It has a master-slave architecture with two main components: Name Node and Data Node.
- Name node is the main node and there is only one per cluster. Your task is to know where each block that belongs to a file is located in the cluster.
- Data node is the slave node that stores the data blocks and there is more than one per cluster. Your task is to retrieve the data when necessary. Stays in constant contact with the Name node through heartbeats.
Small map

To handle Big Data, Hadoop is based on Algoritmo MapReduce introduced by Google and facilitates the distribution of a job and its execution in parallel in a cluster. Basically, splits a single task into multiple tasks and processes them on different machines.
In simple terms, works in a divide and conquer way and runs processes on machines to reduce network traffic.
It has two important phases: Map and Zoom Out.
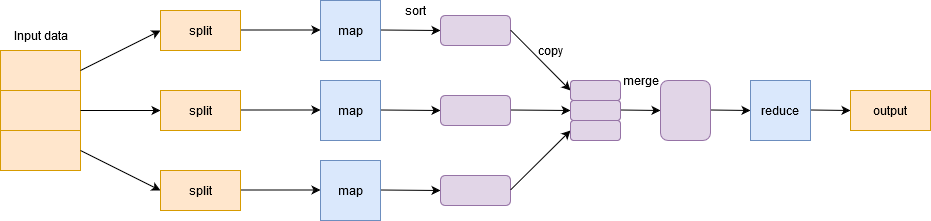
Cartographic phase filter, group and order the data. The input data is divided into multiple divisions. Each map task works on a parallel data slice on different machines and generates a key-value pair. The output of this phase is actuated by the reduce homework and is known as the Reduce phase. Add the data, summarizes the result and stores it in HDFS.
HILO

YARN or Yet Another Resource Negotiator manages the resources in the cluster and manages the applications through Hadoop. Allows data stored in HDFS to be processed and executed by various data processing engines, as batch processing, flow processing, interactive processing, graphics processing and many more. This increases efficiency with the use of YARN.
HBase

HBase is a column-based NoSQL database. It runs on HDFS and can handle any type of data. Allows real-time processing and read operations / random writes performed on the data.
Pork

Pig was developed to analyze large data sets and overcomes the difficulty of writing maps and reducing functions. It consists of the components: Pig Latin y Pig Engine.
Pig Latin is SQL-like scripting language. Pig Engine is the runtime that Pig Latin runs on. Internally, code written in Pig is converted to MapReduce functions and makes it very easy for programmers who are not fluent in Java.
Hive

Hive is a distributed data storage system developed by Facebook. Allows easy reading, writing and managing files in HDFS. It has its own query language for the purpose known as Hive Querying Language (HQL), which is very similar to SQL. This makes it very easy for programmers to write MapReduce functions using simple HQL queries..
Sqoop

Many applications still store data in relational databases, which makes them a very important data source. Therefore, Sqoop plays an important role in bringing data from relational databases to HDFS.
Commands written in Sqoop are internally converted into MapReduce tasks that run in HDFS. Works with almost all relational databases like MySQL, Postgres, SQLite, etc. Can also be used to export data from HDFS to RDBMS.
Artificial canal

Flume is an open source service, reliable and available that is used to collect, efficiently add and move large amounts of data from multiple data sources to HDFS. Can collect data in real time and in batch mode. Has a flexible architecture and is fault tolerant with multiple recovery mechanisms.
Kafka

There are many applications that generate data and a proportional number of applications that consume that data. But connecting them individually is a difficult task. That's where Kafka comes in. It is among the applications that generate data (producers) and applications that consume data (consumers).
Kafka is distributed and partitioned, built-in replication and fault tolerance. It can handle streaming data and also allows companies to analyze data in real time.
Oozie

Oozie is a workflow scheduling system that allows users to link jobs written on various platforms such as MapReduce, Hive, Pig, etc. With Oozie you can schedule a job in advance and can create a pipeline of individual jobs to run sequentially or in parallel to accomplish a larger task.. For instance, you can use Oozie to perform ETL operations on data and then save the output to HDFS.
Zookeeper

In a Hadoop cluster, coordinating and synchronizing nodes can be a challenging task. Therefore, Zookeeper is the perfect tool to solve the problem.
It is an open source service, distributed and centralized to maintain configuration information, to name, provide distributed synchronization and provide group services across the cluster.
Spark – spark

Spark is an alternative framework to Hadoop built in Scala, but it supports various applications written in Java, Python, etc. Compared to MapReduce, provides in-memory processing that represents faster processing. In addition to the batch processing offered by Hadoop, can also handle real-time processing.
What's more, Spark has its own ecosystem:

- Spark Core is the main runtime for Spark and other APIs built on top of it
- API de Spark SQL allows you to query structured data stored in DataFrames or Hive tables
- Streaming API allows Spark to handle data in real time. It can be easily integrated with a variety of data sources such as Flume, Kafka y Twitter.
- MLlib is a scalable machine learning library that will allow you to perform data science tasks while taking advantage of Spark properties at the same time
- GraphX is a graphics calculation engine that allows users to build, interactively transform and reason on structured data into scaled graphs and comes with a library of common algorithms
Stages of Big Data processing
With so many components within the Hadoop ecosystem, can be quite intimidating and difficult to understand what each component does. Therefore, it's easier to group some of the components based on where they are in the Big Data processing stage.
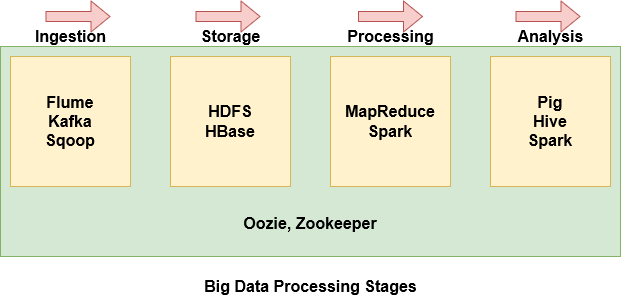
- Flume, Kafka and Sqoop are used to ingest data from external sources into HDFS
- HDFS is Hadoop's storage drive. Even data imported from Hbase is stored in HDFS
- MapReduce and Spark are used to process the data in HDFS and perform various tasks
- Pig, Hive and Spark are used to analyze the data.
- Oozie helps schedule tasks. Since it works with various platforms, used in all stages.
- Zookeeper synchronizes the cluster nodes and is also used in all stages.
Final notes
I hope this article has been useful to understand Big Data, why traditional systems can't handle it and what are the important components of the Hadoop ecosystem.
I encourage you to check out some more articles on Big Data that you may find helpful:





