Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Sempre que criamos um modelo de aprendizado de máquina, nós o alimentamos com dados iniciais para treinar o modelo. E então alimentamos alguns dados desconhecidos (dados de teste) para entender o desempenho do modelo e generalizar os dados invisíveis. Se o modelo funcionar bem com dados invisíveis, é consistente e pode prever com boa precisão em uma ampla gama de dados de entrada; então este modelo é estável.
Mas nem sempre é assim!! Os modelos de aprendizado de máquina nem sempre são estáveis e temos que avaliar a estabilidade do modelo de aprendizado de máquina. É aí que entra a validação cruzada..
“Em termos simples, validação cruzada é uma técnica usada para avaliar o desempenho de nossos modelos de aprendizado de máquina em dados invisíveis”
De acordo com a Wikipedia, validação cruzada é o processo de avaliar como os resultados de uma análise estatística irão generalizar para um conjunto de dados independente.
Existem muitas maneiras de fazer a validação cruzada e aprenderemos sobre 4 métodos neste artigo.
Vamos primeiro entender a necessidade de validação cruzada!!
Por que precisamos de validação cruzada?

Suponha que você crie um modelo de aprendizado de máquina para resolver um problema e tenha treinado o modelo em um determinado conjunto de dados. Cuando verifica la precisión del modelo en los datos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina...., está perto de 95%. Isso significa que seu modelo foi muito bem treinado e é o melhor modelo devido à alta precisão?
Não, não é! Porque seu modelo é treinado nos dados fornecidos, conhece bem os dados, captura até as menores variações (barulho) e foi muito bem generalizado nos dados fornecidos. Se você expõe o modelo a dados completamente novos e invisíveis, pode não prever com tanta precisão e não pode generalizar para novos dados. Esse problema é chamado de overfitting..
As vezes, o modelo não treina bem no conjunto de treinamento porque não consegue encontrar padrões. Neste caso, também não funcionaria bem no equipamento de teste. Este problema é chamado de ajuste insuficiente.
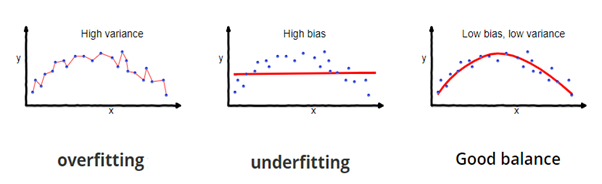
Fonte da imagem: fireblazeaischool.in
Para superar problemas de overfitting, usamos uma técnica chamada validação cruzada.
Validação cruzada é uma técnica de reamostragem com a ideia fundamental de dividir o conjunto de dados em 2 partes: dados de treinamento e dados de teste. Os dados de trem são usados para treinar o modelo e os dados de teste invisíveis são usados para a previsão. Se o modelo tem um bom desempenho nos dados de teste e oferece boa precisão, significa que o modelo não sobrecarregou os dados de treinamento e pode ser usado para predição.
Vamos mergulhar e aprender sobre algumas das técnicas de avaliação de modelo.
1. Método de espera
Este é o método de avaliação mais simples e amplamente utilizado em projetos de aprendizado de máquina.. Aqui, o conjunto de dados completo (população) é dividido em 2 conjuntos: conjunto de trem e conjunto de teste. Os dados podem ser divididos em 70-30 o 60-40, 75-25 o 80-20, o incluso 50-50 dependendo do caso de uso. Como uma regra geral, a proporção dos dados de treinamento deve ser maior do que os dados de teste.
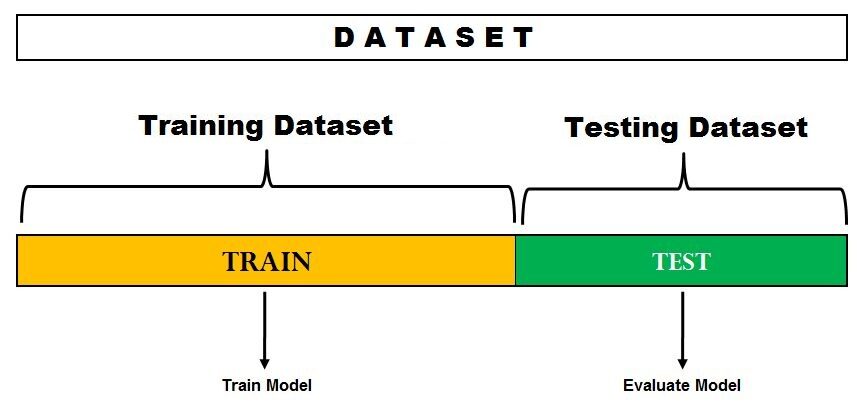
Fonte da imagem: DataVedas
A divisão de dados acontece aleatoriamente e não podemos ter certeza de quais dados acabam no trem e no armazém de teste durante a divisão, a menos que especifiquemos random_state. Isso pode levar a uma variação extremamente alta e cada vez que a divisão muda, a precisão também mudará.
Este método tem algumas desvantagens:
- No método Hold out, taxas de erro de teste são altamente variáveis (alta variância) e depende totalmente de quais observações terminam no conjunto de treinamento e no conjunto de teste.
- Apenas parte dos dados é usada para treinar o modelo (alto preconceito) o que não é uma ideia muito boa quando os dados não são grandes e isso levará a uma superestimação do erro de teste.
Uma das principais vantagens desse método é que ele é computacionalmente barato em comparação com outras técnicas de validação cruzada..
Implementação rápida do método Hold Out em Python
de sklearn.model_selection import train_test_split
X = [10,20,30,40,50,60,70,80,90,100]
Comboio, test = train_test_split (X, test_size = 0.3, random_state = 1)
imprimir (“Trem:”, X_train, “Teste:”, X_test)
Saída
Trem: [50, 10, 40, 20, 80, 90, 60] Teste: [30, 100, 70]
Aqui, random_state é a semente usada para reprodutibilidade.
2. Deixe um fora da validação cruzada
Neste método, dividimos os dados em conjuntos de teste e treinamento, mas com uma torção. Em vez de dividir os dados em 2 subconjuntos, selecionamos uma única observação como dados de teste, e todo o resto é marcado como dados de treinamento e o modelo é treinado. Agora a segunda observação é selecionada como dados de teste e o modelo é treinado com os dados restantes.
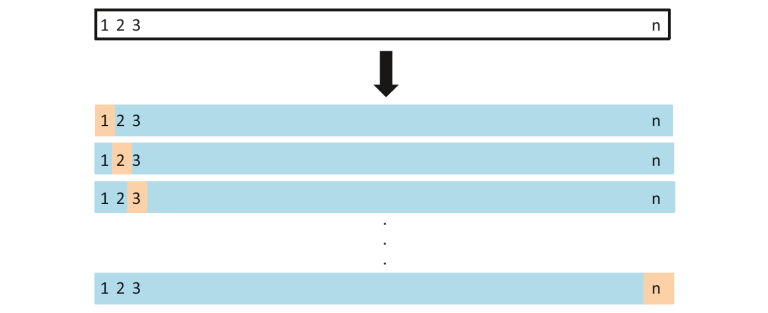
Fonte da imagem: ISLR
Este processo continua 'n’ vezes e a média de todas essas iterações é calculada e estimada como o erro do conjunto de teste.
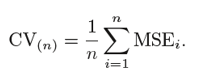
Quando se trata de estimativas de erros de teste, LOOCV fornece estimativas imparciais (baixo preconceito). Mas o viés não é a única preocupação nos problemas de estimativa. Devemos também considerar a variação.
LOOCV tem um alta variância porque estamos calculando a média da saída de n-modelos que se encaixam em um conjunto quase idêntico de observações, e seus resultados são correlacionados positivamente uns com os outros.
E você pode ver claramente que isso é caro do ponto de vista computacional, uma vez que o modelo executa 'n’ vezes para testar cada observação nos dados. Nosso próximo método resolverá esse problema e nos dará um bom equilíbrio entre viés e variância..
Implementação rápida da validação cruzada Leave One Out em Python
de sklearn.model_selection importar LeaveOneOut
X = [10,20,30,40,50,60,70,80,90,100]
l = LeaveOneOut()
para trem, teste em l.split(X):
imprimir("%WL"% (Comboio,teste))
Saída
[1 2 3 4 5 6 7 8 9] [0] [0 2 3 4 5 6 7 8 9] [1] [0 1 3 4 5 6 7 8 9] [2] [0 1 2 4 5 6 7 8 9] [3] [0 1 2 3 5 6 7 8 9] [4] [0 1 2 3 4 6 7 8 9] [5] [0 1 2 3 4 5 7 8 9] [6] [0 1 2 3 4 5 6 8 9] [7] [0 1 2 3 4 5 6 7 9] [8] [0 1 2 3 4 5 6 7 8] [9]
Esta saída mostra claramente como LOOCV mantém uma observação de lado conforme os dados de teste e todas as outras observações vão para os dados do trem.
3. Validação cruzada de K-Fold
Nesta técnica de reamostragem, todos os dados são divididos em k conjuntos de tamanhos quase iguais. O primeiro conjunto é selecionado como o conjunto de teste e o modelo é treinado nos conjuntos k-1 restantes. A taxa de erro de teste é calculada após ajustar o modelo aos dados de teste.
Na segunda iteração, o segundo conjunto é selecionado como o conjunto de teste e os conjuntos k-1 restantes são usados para treinar os dados e o erro é calculado. Este processo continua para todos os k conjuntos.
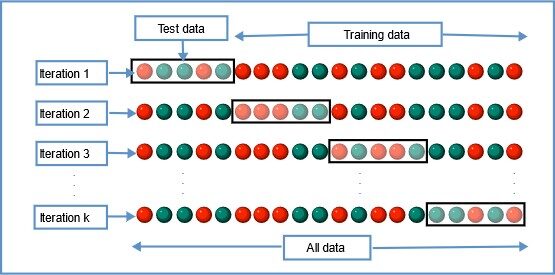
Fonte da imagem: Wikipedia
A média dos erros de todas as iterações é calculada como a estimativa do erro do teste CV.
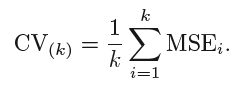
Um CV K-Fold, o número de dobras k é menor que o número de observações nos dados (k <n) e estamos calculando a média dos resultados de k modelos ajustados que são um pouco menos correlacionados uns com os outros porque a sobreposição entre os conjuntos de treinamento em cada modelo é menor. Isto leva a baixa variância então LOOCV.
A melhor parte desse método é que cada ponto de dados está no conjunto de teste exatamente uma vez e faz parte do conjunto de treinamento k-1 vezes.. UMA mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que aumenta el número de pliegues k, a variância também diminui (baixa variância). Este método leva a viés intermediário porque cada conjunto de treinamento contém menos observações (k-1) n / k do que o método Leave One Out, mas mais do que o método Hold Out.
Em geral, K vezes a validação cruzada é feita usando k = 5 o k = 10, uma vez que esses valores foram empiricamente mostrados para produzir estimativas de erros de teste que não têm um viés alto ou uma variância alta.
A principal desvantagem desse método é que o modelo precisa ser executado a partir de zero k vezes e é computacionalmente caro do que o método Hold Out., mas melhor do que o método Leave One Out.
Implementação simples de validação cruzada K-Fold em Python
de sklearn.model_selection import KFold
X = ["uma",'b','c','d','e','f']
kf = KFold(n_splits = 3, shuffle = False, random_state = None)
para trem, teste em kf.split(X):
imprimir("Dados de trem",Comboio,"Dados de teste",teste)
Saída
Trem: [2 3 4 5] Teste: [0 1] Trem: [0 1 4 5] Teste: [2 3] Trem: [0 1 2 3] Teste: [4 5]
4. Validação cruzada estratificada de K-Fold
Esta é uma pequena variação da validação cruzada K-Fold, O que você usa ‘Amostragem estratificada’ ao invés de “amostragem aleatória”.
Vamos entender rapidamente o que é a amostragem estratificada e como ela difere da amostragem aleatória.
Suponha que seus dados contenham análises de um produto cosmético usado pela população masculina e feminina. Quando realizamos amostragem aleatória para dividir os dados em conjuntos de teste e trens, existe a possibilidade de que a maioria dos dados que representam os homens não estejam representados nos dados de treinamento, mas eles podem acabar nos dados de teste. Quando treinamos o modelo com dados de treinamento de amostra que não são uma representação correta da população real, o modelo não irá prever os dados de teste com boa precisão.
É aqui que a amostragem estratificada vem em socorro.. Aqui, os dados são divididos de forma a representar todas as classes da população.
Vamos considerar o exemplo acima, quem tem uma revisão de produtos cosméticos de 1000 clientes, do qual o 60% eles são mulheres e ele 40% eles são homens. Quero dividir os dados em dados de teste e treinamento em proporção (80:20). o 80% dos 1000 os clientes serão 800 que será escolhido de tal forma que haja 480 avaliações associadas à população feminina e 320 representando a população masculina. de forma similar, a 20% a partir de 1000 os clientes serão escolhidos para os dados de teste (com a mesma representação feminina e masculina).
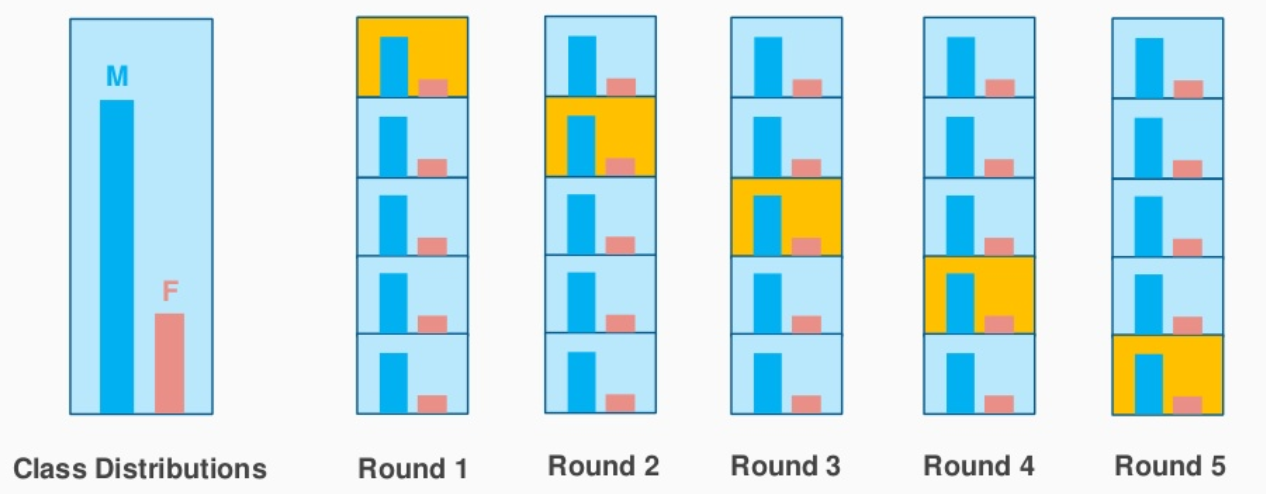
Fonte da imagem: stackexchange.com
Isso é exatamente o que o K-Fold Stratified CV faz e criará K-Folds preservando a porcentagem da amostra para cada classe. Isso resolve o problema de amostragem aleatória associado aos métodos Hold out e K-Fold..
Implementação rápida de validação cruzada estratificada K-Fold em Python
de sklearn.model_selection import StratifiedKFold
X = np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y = np.array([0,0,1,0,1,1])
skf = StratifiedKFold(n_splits = 3, random_state = None,shuffle = False)
para train_index,test_index em skf.split(X,e):
imprimir("Trem:",train_index,'Teste:',test_index)
X_train,X_test = X[train_index], X[test_index]
y_train,y_test = y[train_index], e[test_index]
Saída
Trem: [1 3 4 5] Teste: [0 2] Trem: [0 2 3 5] Teste: [1 4] Trem: [0 1 2 4] Teste: [3 5]
O resultado mostra claramente a divisão estratificada feita de acordo com as classes ‘0’ e 1’ dentro e'.
Tendência – Compensação de variância
Quando consideramos as estimativas da taxa de erro do teste, A validação cruzada K-Fold fornece estimativas mais precisas do que omitir uma validação cruzada. Embora o método Hold One Out CV geralmente leve a superestimações da taxa de erro de teste, porque nesta abordagem, apenas parte dos dados é usada para treinar o modelo de aprendizado de máquina.
Quando se trata de preconceito, o método Leave One Out fornece estimativas imparciais porque cada conjunto de treinamento contém n-1 observações (que são praticamente todos os dados). K-Fold CV leva a um nível intermediário de polarização, dependendo do número de k-fold em comparação com LOOCV, mas é muito menos comparado ao método Hold Out.
Para concluir, a técnica de validação cruzada que escolhemos é altamente dependente do caso de uso e do equilíbrio entre viés e variância.
Se você leu este artigo até agora, aqui está um bônus rápido para você. 👏
sklearn.model_selection tem um método cross_val_score o que simplifica o processo de validação cruzada. Em vez de iterar todos os dados usando a função 'dividir', podemos usar cross_val_score e verificar a pontuação de precisão do método de validação cruzada escolhido
Você pode verificar meu Github para implementação python de diferentes métodos de validação cruzada no Fatos sobre câncer de mama na UTI Kaggle.
Abaixo estão alguns dos meus artigos sobre aprendizado de máquina.
Inteligencia artificial Vs Aprendizaje automático Vs Aprendizagem profundaAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde...: Qual é exatamente a diferença entre essas palavras da moda?
Um guia completo para análise de dados usando pandas
Se você quiser compartilhar seus pensamentos, você pode se conectar comigo em LinkedIn.
Boa aprendizagem!
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





