Este artigo foi publicado como parte do Data Science Blogathon
Visualização de dados
As técnicas de visualização de dados envolvem a geração de representações gráficas ou pictóricas. De dados, Formulário que leva você a entender as informações em um determinado conjunto de dados. Esta técnica de visualização visa identificar os padrões, Tendências, Correlações e outliers de conjuntos de dados.
Benefícios da visualização de dados
- Padrões nas operações de negócios: As técnicas de visualização de dados nos ajudam a determinar padrões de operações de negócios. Compreender o enunciado do problema e identificar soluções em termos de padrões e aplicadas para eliminar um ou mais dos problemas inerentes.
- Identifique tendências de negócios e interaja com dados: Estão As técnicas nos ajudam a identificar tendências de mercado, coletando dados sobre as atividades diárias de negociação e preparando relatórios de tendências., que ajuda a rastrear a forma como a empresa influencia o mercado. Para que possamos entender a concorrência e os clientes. Certamente, Isso ajuda a ter uma perspectiva de longo prazo.
- Contação de histórias e tomada de decisão: Conhecimento de storytelling a partir de dados disponíveis é uma das habilidades de nicho para a comunicação empresarial, Especificamente para o domínio da ciência de dados, que está a desempenhar um papel vital. Usando a melhor visualização esta função pode ser melhorada muito melhor e atingindo os objetivos dos problemas de negócios.
- Compreender as informações comerciais atuais e definir metas: Las empresas pueden comprender la información de los KPIsKPIs, o Indicadores-chave de desempenho, Essas são métricas usadas pelas organizações para avaliar seu sucesso em atingir metas específicas. Esses indicadores permitem monitorar o progresso e tomar decisões informadas. Existem diferentes tipos de KPIs, que podem variar dependendo do setor e dos objetivos estratégicos da empresa. Sua correta implementação é essencial para melhorar a eficiência e eficácia das operações.... comerciais, Encontre metas tangíveis e planos de estratégia de negócios, para que eles pudessem otimizar os dados para planos de estratégia de negócios para atividades em andamento.
- Análise operacional e de desempenho:
- Aumentar a produtividade da unidade fabril: Com a ajuda de técnicas de visualização, clareza dos KPIs que representam as tendências de produtividade da unidade de manufatura e orientação foram para melhorar a produtividade da planta.
Visualização de dados em ciência de dados
As técnicas de visualização de dados são a parte mais importante da ciência de dados, Não haverá dúvida sobre isso.. E até mesmo no espaço de análise de dados, A visualização de dados desempenha um papel importante. Discutiremos isso em detalhes com a ajuda de pacotes Python e como isso ajuda durante o fluxo do processo de Ciência de Dados.. Este é um tópico muito interessante para todos os cientistas de dados e analistas..
eu. Gráfico de linhaO gráfico de linhas é uma ferramenta visual usada para representar dados ao longo do tempo. Consiste em uma série de pontos conectados por linhas, que permite observar tendências, Flutuações e padrões nos dados. Esse tipo de gráfico é especialmente útil em áreas como economia, Meteorologia e pesquisa científica, facilitando a comparação de diferentes conjuntos de dados e a identificação de comportamentos em geral..
Gráfico de linha é uma visualização de dados simples em Python, que está disponível em Matplotlib.
Gráficos de linha são usados para representar a relação entre dois dados X e Y no respectivo eixo. Vejamos alguns exemplos
Amostra #1 # importing the required libraries import matplotlib.pyplot as plt import numpy as np #simple array x = np.array([1, 2, 3, 4]) #genearting y values y = x*2 plt.plot(x, e) plt.show() Amostra #2 x = np.array([1, 2, 3, 4]) y = np.array([2, 4, 6, 8]) plt.plot(x, e) plt.xlabel("Hora em Hrs") plt.ylabel("Distância em Km") plt.title("Tempo Vs Distância") plt.show()
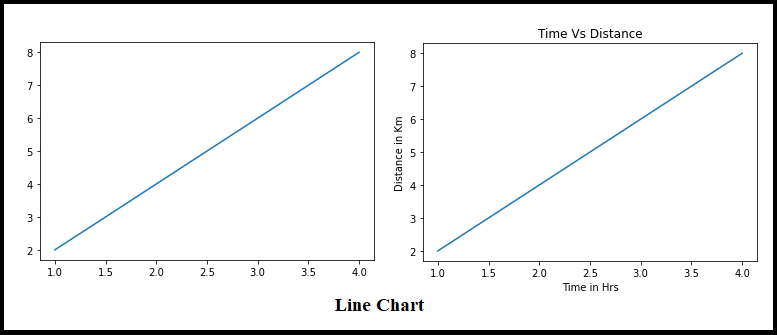
Gráfico de linhas sempre uma relação linear entre os eixos X e Y, Vemos isso na imagem acima.
II.Histograma
O histograma é a representação gráfica de um conjunto de distribuição numérica de dados. Es una especie de gráfico de barrasO gráfico de barras é uma representação visual de dados que usa barras retangulares para mostrar comparações entre diferentes categorias. Cada barra representa um valor e seu comprimento é proporcional a ele. Esse tipo de gráfico é útil para visualizar e analisar tendências, facilitar a interpretação de informações quantitativas. É amplamente utilizado em várias disciplinas, como estatísticas, Marketing e pesquisa, devido à sua simplicidade e eficácia.... con el eje X y el eje Y representa los rangos y la frecuencia de los intervalos, respectivamente. Como ler ou representar esta tabela.
Digamos o exemplo, Conjunto de marcações dos alunos nas faixas e frequências mostradas abaixo. Aqui pudemos entender exatamente o alcance e a frequência de corte.
from matplotlib import pyplot as plt
import numpy as np
fig,ax = plt.subplots(1,1)
a = np.array([25,42,48,55,60,62,67,70,30,38,44,50,54,58,75,78,85,88,89,28,35,90,95])
ax.hist(uma, bins = [20,40,60,80,100])
ax.set_title("Pontuação do aluno")
ax.set_xticks([0,20,40,60,80,100])
ax.set_xlabel('Marcas marcadas')
ax.set_ylabel('Não. dos Estudantes)
plt.show()
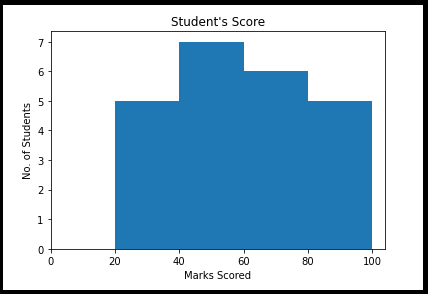
Características do histograma
- a Histograma Ele é usado para obter quaisquer observações incomuns no conjunto de dados DAR.
- Medido em uma escala de intervalo de valores numéricos dados com vários contêineres de dados.
- O eixo y representa o número de % de ocorrências nos dados
- O eixo x representa distribuições de dados.
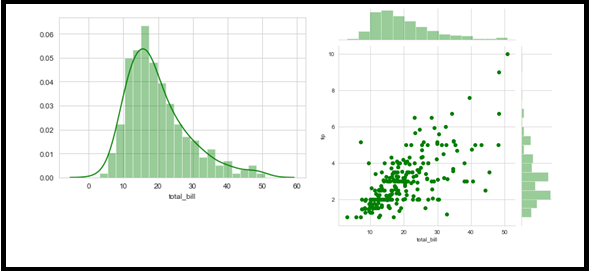
Programa – Isso é semelhante ao histograma no gráfico, mas com recursos adicionais. E trazendo Estimativa de densidade de grão (ONDE).
Parcela conjunta – Uma combinação de espalhamento e histograma.
import seaborn as sns
import matplotlib.pyplot as plt
from warnings import filterwarnings
df = sns.load_dataset('dicas')
sns.distplot(df['total_bill'], kde = verdadeiro, color ="verde", bins = 20)
sns.jointplot(x = 'total_bill',color ="verde", y ='dica', dados = df)
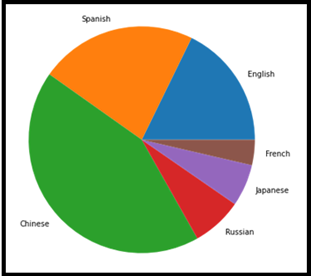
III.Gráfico de pizza
Este é um gráfico muito familiar e um gráfico estatístico de representação na forma de uma circular a partir de uma série de dados. Isso é comumente usado em apresentações de negócios para representar pedidos., vendas, Lucros, perdas, etc. Consiste em porções de dados que fazem parte da coleta de um mesmo conjunto e diferenciação por caracteres. Cada uma das fatias de bolo é chamada de cunha com valores de tamanhos diferentes.
Esta tabela é amplamente utilizada para representar a coleção de composição.. Perfeito para tipos de dados categóricos.
from matplotlib import pyplot as plt import numpy as np Language = ['Inglês', 'Espanhol', 'Chinês', 'Russo', 'Japonês', 'Francês'] dados = [379, 480, 918, 154, 128, 77.2] # Creating plot fig = plt.figure(figsize =(10, 7)) plt.pie(dados, labels = Idioma) # show plot plt.show()
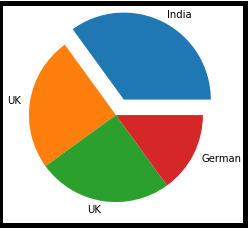
import matplotlib.pyplot as plt
import numpy as np
y = np.array([35, 25, 25, 15])
mylabels = ["Índia", "Reino Unido", "Reino Unido", "alemão"]
myexplode = [0.2, 0, 0, 0]
plt.pie(e, rótulos = mylabels, explode = meuexplode)
plt.show()
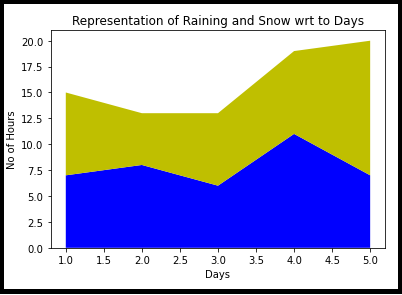
4. Parcela de área
Esto es muy similar a un gráfico de líneas con cercas rodeadas por una línea de límite de diferentes colores. Representación simple de la evolución de una variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... numérico.
import matplotlib.pyplot as plt
days = [1, 2, 3, 4, 5]
chuva = [7, 8, 6, 11, 7]
neve = [8, 5, 7, 8, 13]
plt.stackplot(dias, Chovendo, neve,cores =['b', 'e'])
plt.xlabel('Dias')
plt.ylabel('Sem horários')
plt.title('Representação da chuva e da neve para os dias')
plt.show()
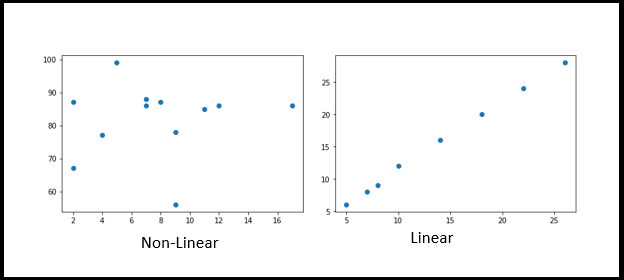
V. Gráficos de dispersión
Os gráficos de dispersão são usados para plotar pontos de dados em ambos os eixos (horizontal e vertical) e representar como cada eixo se correlaciona entre si. Principalmente na implementação de Data Science / Machine Learning e antes do processo EDA, Geralmente devemos analisar o quão dependentes e independentes eles se alinham. Pode ser positivo ou negativo ou, as vezes, estar espalhado no gráfico.
import matplotlib.pyplot as plt
x = [5,7,8,7,2,17,2,9,4,11,12,9]
y = [99,86,87,88,67,86,87,78,77,85,86,56]
plt.scatter(x, e)
plt.show()
import matplotlib.pyplot as plt
x = [5,7,8,10,14,18,22,26]
y = [6,8,9,12,16,20,24,28]
plt.scatter(x, e)
plt.show()
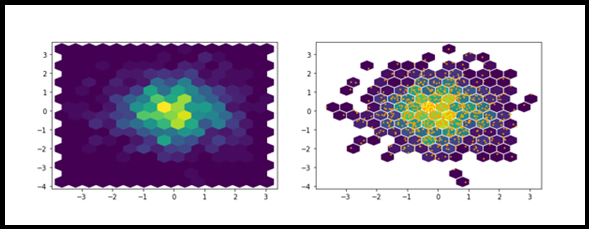
SERRA. Lotes Hexbins
O objetivo Hexbins é usado para agrupar os dois conjuntos de valores numéricos. Hexbins ajuda a melhorar a exibição de gráficos de dispersão. Porque para um conjunto de dados maior, uma Diagrama de dispersãoO gráfico de dispersão é uma ferramenta gráfica usada em estatística para visualizar a relação entre duas variáveis. Consiste em um conjunto de pontos em um plano cartesiano, onde cada ponto representa um par de valores correspondentes às variáveis analisadas. Este tipo de gráfico permite identificar padrões, Tendências e possíveis correlações, facilitando a interpretação dos dados e a tomada de decisão com base nas informações visuais apresentadas.... crea un puñado de puntos confusos. Podemos melhorar isso com Hexbins. Fornece dois modos de renderização: 1. Lista de coordenadas 2. Objeto geoespacial.
import numpy as np
import matplotlib.pyplot as plt
x = np.random.normal(tamanho =(1, 1000))
y = np.random.normal(tamanho =(1, 1000))
plt.hexbin(x, e, tamanho da grade=15)
plt.hexbin(x,e,tamanho da grade=15, mincnt=1, edgecolors="Branco") plt.scatter(x,e, s=2, c ="laranja") plt.show()
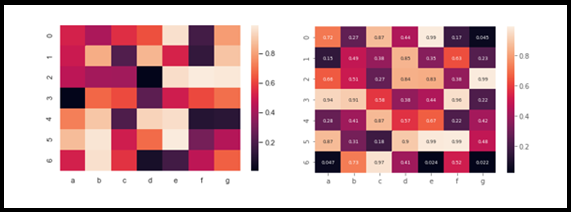
VII. Mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas....
UMA mapa de calor É uma das minhas técnicas de visualização favoritas entre os outros gráficos.. basicamente, Um conjunto de correlações variáveis é representado por várias tonalidades da mesma cor. Em geral, Os tons mais escuros no gráfico representam os valores de correlação mais altos do que o tom mais claro. Esse mapa ajudaria os cientistas de dados a descobrir como a variável de destino se correlaciona com outras variáveis dependentes no conjunto de dados fornecido.. Variáveis menos correlacionadas podem ser removidas para uma análise mais detalhada, Podemos dizer que isso nos ajuda durante o processo de seleção de recursos. Em seguida, agrupando-os em X, E como nosso objetivo e seguimos teste e divisão do trem.
import seaborn as sn import numpy as np import pandas as pd df=pd.DataFrame(np.random.random((7,7)),colunas =['uma','b','c','d','e','f','g']) sn.mapa de calor(df)
sn.mapa de calor(df,annot = True,annot_kws={'Tamanho':7})
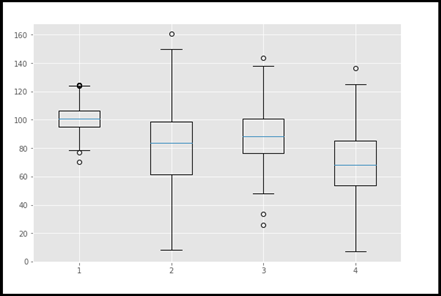
VIII. Box plot
Um gráfico de caixa é um tipo de gráfico que é frequentemente usado no ciclo de vida da ciência de dados., especialmente durante a análise de dados explicativos (EDA). Representando a distribuição dos dados na forma de quartis ou percentis. Q1 representa o primeiro quartil (percentil 25), Q2 é o segundo quartil (percentil 50 / medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos....), Q3 representa o terceiro quartil (3º T) e Q4 representa o quarto quartil ou maior valor.
Usando este gráfico, Conseguimos identificar outliers de forma muito rápida e fácil. Este é um enredo muito eficaz entre todas as tramas. Portanto, Depois de remover outliers, O conjunto de dados precisa passar por algum tipo de teste estatístico e ser ajustado para análise posterior..
#import matplotlib.pyplot as plt
np.random.seed(10)
um=np.random.normal(100,10,200)
dois=np.random.normal(80, 30, 200)
três=np.random.normal(90, 20, 200)
quatro=np.random.normal(70, 25, 200)
to_plot=[Um,Dois,Três,Quatro]
fig=plt.figura(1,figsize =(9,6))
ax=fig.add_subplot()
bp = ax.boxplot(to_plot)
fig.savefig('Boxplot.png',bbox_inches="apertado")
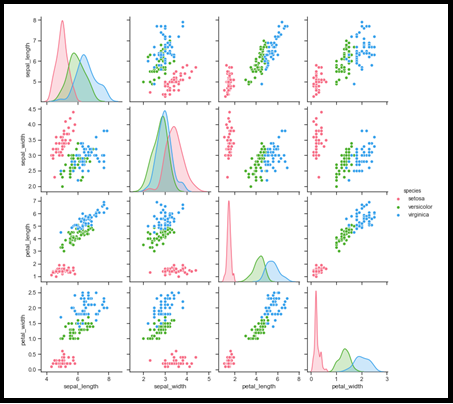
IX. Enredo
Um parcel é outro gráfico importante no ciclo de vida da ciência de dados durante o processo de EDA., para analisar como os recursos se relacionam entre si, na forma de uma representação gráfica em miniatura baseada em grade ao longo dos eixos X e Y, positivamente correlacionado ou negativamente correlacionado. . Então, obviamente, Poderíamos eliminar os negativamente correlacionados, considerando pares corrigidos positivamente e movendo-se para análise posterior. Isso é muito semelhante ao Mapa de Calor, Mas aqui pudemos ver a relação a olho nu. Isso aqui é especial.. Espero que você possa pagar isso. Novamente, Isso é melhor para executar o processo de seleção de recursos.
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('íris')
sb.set_style("Carrapatos")
sb.gráfico de pares(df,matiz ="espécie",diag_kind = "KDE",tipo = "espalhar",paleta = "husl")
plt.show()
O gráfico de linhas é sempre uma relação linear entre os eixos X e Y, Notamos que a imagem acima
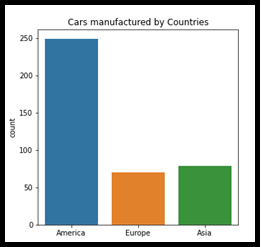
X. Gráfico de barras
Um gráfico de barras ou gráfico de barras é geralmente um gráfico muito familiar para apresentar dados categóricos com barras retangulares.. Pode ser plotado horizontalmente ou verticalmente. Esse gráfico representaria o impacto da categoria do indivíduo no conjunto de dados dado.. Primeiro do primeiro olhar. No gráfico abaixo, "América" tem muito mais impacto do que "Europa" e "Ásia". Isso levaria a alguma observação sobre o conjunto de dados e foco na afirmação do problema..
FIG, ax = plt.subplots(figsize = (5, 5)) sns.countplot(x = df_cars.origin.values, data=df_cars) a primeira coisa que fazemos é identificar se os dados são estacionários ou não estacionários [item.get_text() para item em ax.get_xticklabels()] rótulos[0] = 'America' labels[1] = 'Europe' labels[2] = 'Asia' ax.set_xticklabels(rótulos) ax.set_title("Carros fabricados por Países") plt.show()
Univariada – Análise bivariada e multivariada
Análise de variantes no processo de Ciência de Dados, poderia ser univariada (o) Bivariável (o) Multivariado.
- Univariada: apenas uma variável de cada vez.
- Bivariável: Comparar duas variáveis.
- Multivariado: Comparar mais de duas variáveis
Você pode muito bem referenciar os modelos anteriores com os gráficos / Visualização que discutimos desde o início do artigo. Basta verificá-lo novamente. Certamente, pode entender a importância dessas técnicas de visualização de dados.
Obrigado por ler este artigo e eu acho que é útil para você. e você pode perceber isso quando optar pela implantação da solução de Ciência de Dados antes da seleção do modelo. Mesmo depois de tudo a avaliação e as previsões do modelo são o resultado de comparações. Conforme mostrado abaixo nas tabelas de referência.
Obrigado! Mais uma vez. Entraremos em contato com outro tópico interessante. Até lá, adeus!! Até logo! – Shanthababu
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





