Introduction
What is data cleansing? Removing null records, removing unnecessary columns, the treatment of missing values, rectification of unwanted values or outliers, restructuring the data to edit it to a more readable format, etc., it is known as data cleansing.

One of the most common examples of data cleansing is its application in data warehouses. A data warehouse stores a range of data from numerous sources and optimizes it for analysis before any model fit can be performed.
Data cleansing is not just removing existing information to add new information, but find a way to maximize the accuracy of a data set without necessarily giving up existing information. Different types of data will require different types of cleaning, but always remember that the right approach is the deciding factor.
After cleaning the data, will become consistent with other similar data sets in the system.. Let's see the steps to clean the data;
Clear null records / duplicates
If a particular row is missing a significant amount of data, then it would be better to delete that row, since it would not add any value to our model. can impute the value; provide an appropriate substitute for missing data. Also remember to always erase duplicate values / redundant of your dataset, since they could result in a bias in your model.
As an example, consider the student data set with the following records.
| Name | score | Address | height | weight |
| A | 56 | Go to | 165 | 56 |
| B | 45 | Bombay | 3 | Sixty-five |
| C | 87 | Delhi | 170 | 58 |
| D | ||||
| me | 99 | Mysore | 167 | 60 |
As we see that it corresponds to the student's name “D”, most data is missing, therefore, we discard that particular row.
student_df.dropna() # drops rows with 1 or more Nan value
#production
| Name | score | Address | height | weight |
| A | 56 | Go to | 165 | 56 |
| B | 45 | Bombay | 3 | Sixty-five |
| C | 87 | Delhi | 170 | 58 |
| me | 99 | Mysore | 167 | 60 |
Delete unnecessary columns
When we receive data from interested parties, in general it is huge. There may be a data record that might not add any value to our model. It is better to delete this data, since it would do it with valuable resources such as memory and processing time.
As an example, observing student performance on a test, the weight or height of the students have nothing to contribute to the model.
student_df.drop(['height','weight'], axis = 1,inplace=True) #Drops Height column form the dataframe
#Production
| Name | score | Address |
| A | 56 | Go to |
| B | 45 | Bombay |
| C | 87 | Delhi |
| me | 99 | Mysore |
Rename columns
It is always best to rename the columns and format them to the most readable format that both the data scientist and the company can understand.. As an example, in the student data set, rename column “Name” What “Sudent_Name” makes sense.
student_df.rename(columns={'name': 'Student_Name'}, inplace=True) #renames name column to Student_Name
#Production
| Student name | score | Address |
| A | 56 | Go to |
| B | 45 | Bombay |
| C | 87 | Delhi |
| me | 99 | Mysore |
Deal with missing values
There are many alternatives to take care of missing values in a dataset. It is up to the data scientist and data set at hand to select the most appropriate method. The most used methods are the imputation of the data set with mean, medianThe median is a statistical measure that represents the central value of a set of ordered data. To calculate it, the data is organized from lowest to highest and the number in the middle is identified. If there are an even number of observations, the two core values are averaged. This indicator is especially useful in asymmetric distributions, since it is not affected by extreme values.... o Fashion. Deleting those particular records with one or more missing values and, in some cases, creating machine learning algorithms like linear regression and nearest neighbor K is also used to deal with missing values.
| Student name | score | Address |
| A | 56 | Go to |
| B | 45 | Bombay |
| C | Delhi | |
| me | 99 | Mysore |
Student_df['col_name'].fillna((Student_df['col_name'].mean()), inplace=True) # Na values in col_name is replaced with mean
#Production
| Student name | score | Address |
| A | 96 | Go to |
| B | 45 | Bombay |
| C | 66 | Delhi |
| me | 99 | Mysore |
Detection of atypical values
Outliers can be considered as noise in the data set. There can be multiple reasons for outliers, as data entry error, error manual, error experimental, etc.
As an example, in the following example, student's score “B” you enter 130, which is clearly not correct.
| Student name | score | Address | height | weight |
| A | 56 | Go to | 165 | 56 |
| B | 45 | Bombay | 3 | Sixty-five |
| C | 66 | Delhi | 170 | 58 |
| me | 99 | Mysore | 167 | 60 |
Plotting the height on a box plot gives the following result
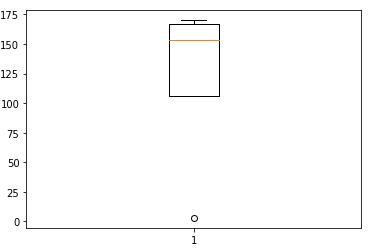
Not all extreme values are outliers, some may also lead to interesting discoveries, but that's a topic for another day. Tests such as the Z-score test can be used, the box plot or simply plotting the data on the graph will reveal the outliers.
Reform / restructure the data
Most of the business data provided to the data scientist is not in the most readable format. It is our job to reshape the data and bring it into a format that can be used for analysis.. As an example, creating a new variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... from existing variables or by combining 2 or more variables.
Footnotes
Certainly, there are many benefits of working with clean data, few of which are the improved accuracy of the models, better decision-making by stakeholders, the ease of model implementation and the adjustment of parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project...., saving time and resources, and many more. Always remember to clean the data as the first and most important step before fitting any model.
References
https://www.geeksforgeeks.org/
The media shown in this post is not the property of DataPeaker and is used at the author's discretion.





