Note: This article was originally published on 10 October 2014 and the 27 March 2018.
Overview
- Understand the nearest neighbor (KNN): one of the most popular machine learning algorithms
- Learn how kNN works in python
- Choose the correct value of k in simple terms
Introduction
In the four years of my data science career, I have built more than 80% of classification models and only one 15-20% regression models. These ratios can be more or less generalized throughout the industry. The reason behind this bias towards classification models is that most analytical problems involve making a decision.
For instance, whether or not a customer will wear out, if we go to client X for digital campaigns, whether the client has high potential or not, etc. These analyzes are more insightful and are directly linked to an implementation roadmap.

In this article, we'll talk about another widely used machine learning. classification techniqueme called K-nearest neighbors (KNN). Our focus will be mainly on how the algorithm works and how the input parameter affects the output / prediction.
Note: People who prefer to learn through videos can learn the same through our free course – K-Nearest Neighbors Algorithm (KNN) in Python and R. And if you are an absolute beginner in data science and machine learning, check out our Certified BlackBelt program:
Table of Contents
- When do we use the KNN algorithm?
- How does the KNN algorithm work?
- How do we choose the K factor?
- Breaking it Down – KNN Pseudo Code
- Python implementation from scratch
- Comparing our model with scikit-learn
When do we use the KNN algorithm?
KNN can be used for predictive classification and regression problems. But nevertheless, most widely used in classification problems in industry. To evaluate any technique, we usually look at 3 important aspects:
1. Ease of interpreting the output
2. Calculation time
3. Predictive power
Let's take some examples to place KNN on the scale:
 KNN algorithm trade shows across all considerations parameters. It is commonly used for its easy interpretation and low calculation time.
KNN algorithm trade shows across all considerations parameters. It is commonly used for its easy interpretation and low calculation time.
How does the KNN algorithm work?
Let's take a simple case to understand this algorithm. Below is an extension of red circles (RC) and green squares (GS):
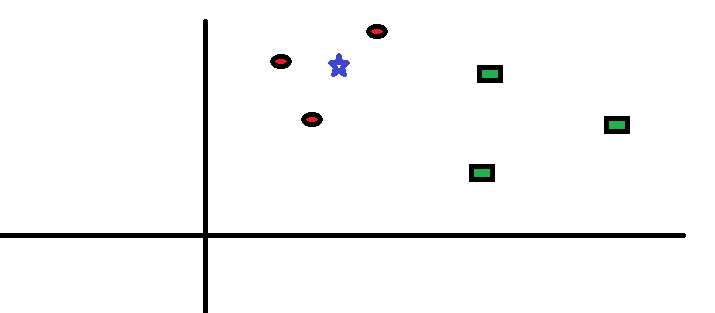 He intends to find out the class of the blue star (BS). BS can be RC or GS and nothing else. The algorithm “K” en KNN is the closest neighbor we want to vote for. Let's say that K = 3. Therefore, now we will make a circle with BS as the center so large as to enclose only three data points in the plane. Please refer to the following diagram for more details:
He intends to find out the class of the blue star (BS). BS can be RC or GS and nothing else. The algorithm “K” en KNN is the closest neighbor we want to vote for. Let's say that K = 3. Therefore, now we will make a circle with BS as the center so large as to enclose only three data points in the plane. Please refer to the following diagram for more details:
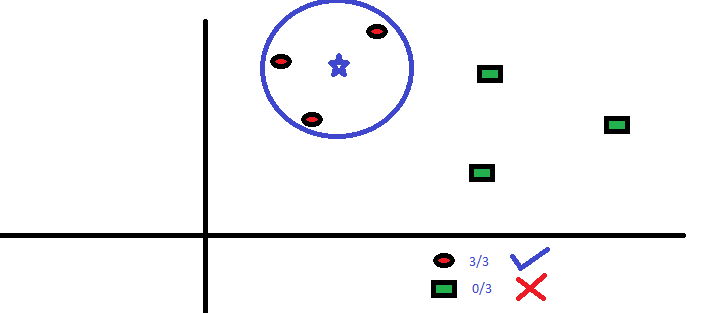 The three closest points to BS are all RC. Therefore, with a good level of confidence, we can say that the BS should belong to the RC class. Here, the choice became very obvious as the three closest neighbor votes went to RC. The choice of the parameter K is very important in this algorithm. Then, we will understand what are the factors to consider to conclude the best K.
The three closest points to BS are all RC. Therefore, with a good level of confidence, we can say that the BS should belong to the RC class. Here, the choice became very obvious as the three closest neighbor votes went to RC. The choice of the parameter K is very important in this algorithm. Then, we will understand what are the factors to consider to conclude the best K.
How do we choose the K factor?
Let's first try to understand what exactly K influences the algorithm. If we see the last example, since the 6 training observations remain constant, with a given K value we can set limits for each class. These limits will separate RC from GS. In the same way, let's try to see the effect of value “K” in the limits of the class. The following are the different limits that separate the two classes with different values of K.
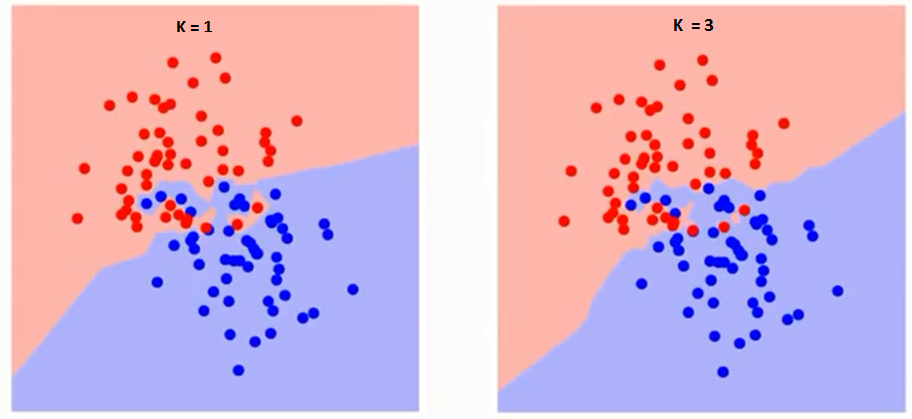
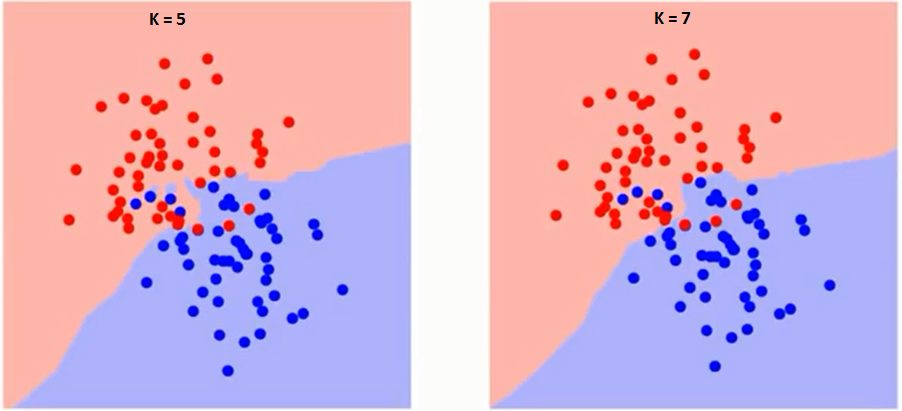
If you look closely, you can see that the limit becomes smoother as the value of K increases. With K increasing to infinity, it finally turns all blue or all red, depending on the total majority. The training error rate and the validation error rate are two parameters that we need to access different K-values.. Below is the curve for the training error rate with a variable value of K:
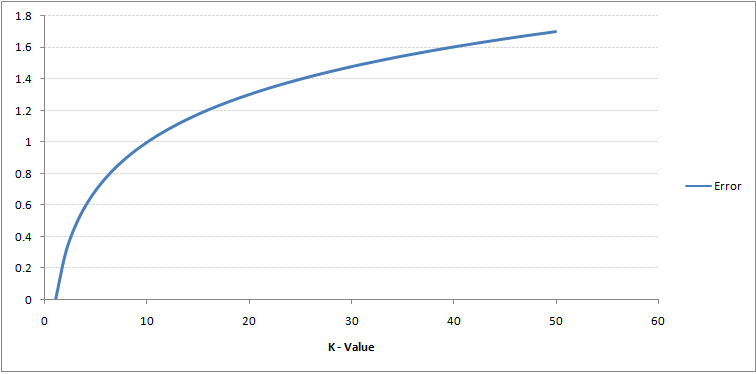 As you can see, the error rate in K = 1 is always zero for the training sample. This is because the closest point to any training data point is itself, so the prediction is always accurate with K = 1. If the validation error curve had been similar, our choice of K would have been 1. Below is the validation error curve with a variable value of K:
As you can see, the error rate in K = 1 is always zero for the training sample. This is because the closest point to any training data point is itself, so the prediction is always accurate with K = 1. If the validation error curve had been similar, our choice of K would have been 1. Below is the validation error curve with a variable value of K:
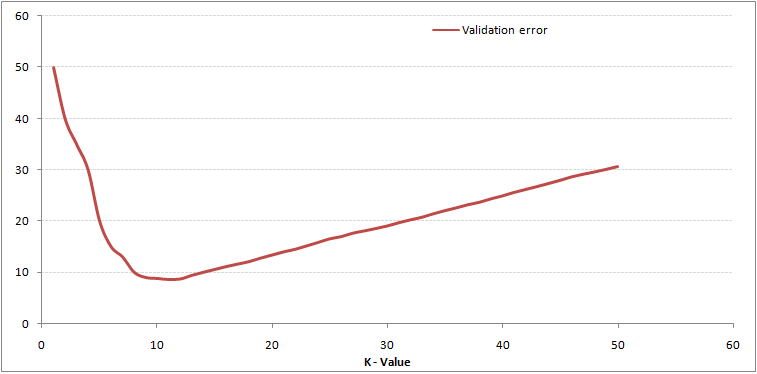 This clears the story. And K = 1, we were over-setting the limits. Therefore, the error rate initially decreases and reaches a minimum. After the minimum point, increases with increasing K. To obtain the optimal value of K, can segregate training and initial dataset validation. Now plot the validation error curve to obtain the optimal value of K. This value of K should be used for all predictions.
This clears the story. And K = 1, we were over-setting the limits. Therefore, the error rate initially decreases and reaches a minimum. After the minimum point, increases with increasing K. To obtain the optimal value of K, can segregate training and initial dataset validation. Now plot the validation error curve to obtain the optimal value of K. This value of K should be used for all predictions.
The above content can be understood more intuitively using our free course: Nearest Neighbors Algorithm (KNN) in Python and R
Breaking it Down – KNN Pseudo Code
We can implement a KNN model by following the steps below:
- Load data
- Initialize the value of k
- To get the predicted class, repeat from 1 up to the total number of training data points
- Calculate the distance between the test data and each row of training data. Here we will use the Euclidean distance as our distance metric, since it is the most popular method. The other metrics that can be used are Chebyshev, cosine, etc.
- Sort the calculated distances in ascending order based on the distance values
- Get the first k rows of the ordered matrix
- Get the most frequent class from these rows
- Returns the predicted class
Python implementation from scratch
We will use the popular Iris dataset to build our KNN model. You can download it from here.
Comparing our model with scikit-learn
from sklearn.neighbors import KNeighborsClassifier neigh = KNeighborsClassifier(n_neighbors=3) neigh.fit(data.iloc[:,0:4], data['Name']) # Predicted class print(neigh.predict(test)) -> ['Iris-virginica'] # 3 nearest neighbors print(neigh.kneighbors(test)[1]) -> [[141 139 120]]
We can see that both models predicted the same class (‘Iris-virginica’) and the same closest neighbors ( [141 139 120] ). Therefore, we can conclude that our model works as expected.
Implementation of kNN in R
Paso 1: import the data
Paso 2: verify data and calculate data summary
Production
#Top observations present in the data SepalLength SepalWidth PetalLength PetalWidth Name 1 5.1 3.5 1.4 0.2 Iris-silky 2 4.9 3.0 1.4 0.2 Iris-silky 3 4.7 3.2 1.3 0.2 Iris-silky 4 4.6 3.1 1.5 0.2 Iris-silky 5 5.0 3.6 1.4 0.2 Iris-silky 6 5.4 3.9 1.7 0.4 Iris-setosa #Check the dimensions of the data [1] 150 5 #Summarise the data SepalLength SepalWidth PetalLength PetalWidth Name Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 Iris-silky :50 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 Iris-versicolor:50 Median :5.800 Median :3.000 Median :4.350 Median :1.300 Iris-virginica :50 Mean :5.843 Mean :3.054 Mean :3.759 Mean :1.199 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Paso 3: divide the data
Paso 4: Calculate the Euclidean distance
Paso 5: write the function to predict kNN
Paso 6: Calculation of the label (Name) for K = 1
Production
For K=1 [1] "Iris-virginica"
In the same way, can calculate other values of K.
Comparison of our prediction function kNN with the library “Class”
Production
For K=1 [1] "Iris-virginica"
We can see that both models predicted the same class (‘Iris-virginica’).
Final notes
The KNN algorithm is one of the simplest classification algorithms. Even with such simplicity, can give highly competitive results. The KNN algorithm can also be used for regression problems. The only difference with the methodology discussed will be the use of averages of the closest neighbors instead of voting for the closest neighbors.. KNN can be encoded on a single line in R. I have yet to explore how we can use the KNN algorithm in SAS.
Was the article helpful to you? Have you used any other machine learning tools recently? Are you planning to use KNN in any of your business problems? If so, tell us how you plan to do it.





