This article was published as part of the Data Science Blogathon
1. Target
El objetivo de este artículo es predecir los precios de los vuelos dados los distintos parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project..... The data used in this article is publicly available on Kaggle. Este será un problema de regresión ya que la variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... objetivo o dependiente es el precio (continuous numeric value).
2. Introduction
Airlines use complex algorithms to calculate flight prices given the various conditions present at that particular time.. These methods take into account financial factors, marketing and social to predict flight prices.
Today, the number of people using flights has increased significantly. It is difficult for airlines to maintain prices, since prices change dynamically due to different conditions. That is why we will try to use machine learning to solve this problem.. This can help airlines by predicting what prices they can keep. It can also help customers predict future flight prices and plan their trip accordingly..
3. Data used
Kaggle data was used, which is a free access platform for data scientists and machine learning enthusiasts.
Source: https://www.kaggle.com/nikhilmittal/flight-fare-prediction-mh
We are using jupyter-notebook to run the flight price prediction task.
4. Analysis of data
The procedure of extracting information from given raw data is called data analysis. Here we will use eda module data preparation library to do this step.
from dataprep.eda import create_report
import pandas as pd
dataframe = pd.read_excel("../output/Data_Train.xlsx")
create_report(dataframe)
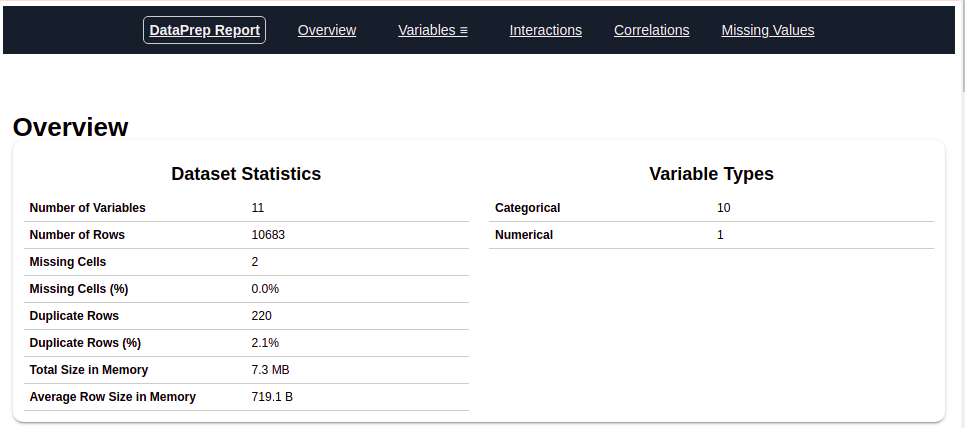
After running the above code, obtendrá un informe como se muestra en la figure"Figure" is a term that is used in various contexts, From art to anatomy. In the artistic field, refers to the representation of human or animal forms in sculptures and paintings. In anatomy, designates the shape and structure of the body. What's more, in mathematics, "figure" it is related to geometric shapes. Its versatility makes it a fundamental concept in multiple disciplines.... anterior. This report contains multiple sections or tabs. The section ‘General description’ of this report provides us with all the basic information of the data that we are using. For the current data we are using, we got the following information:
Number of variables = 11
Number of rows = 10683
Characteristic categorical type number = 10
Characteristic numeric type number = 1
Rows duplicated = 220, etc.
Let's explore other sections of the report one by one.
4.1 Variables
After selecting the variables section, you will get information as shown in the following figures.
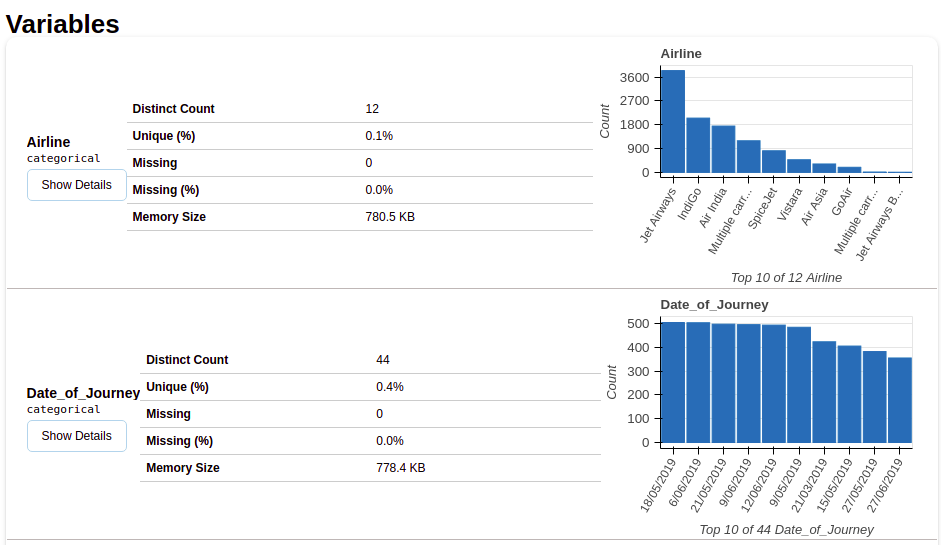
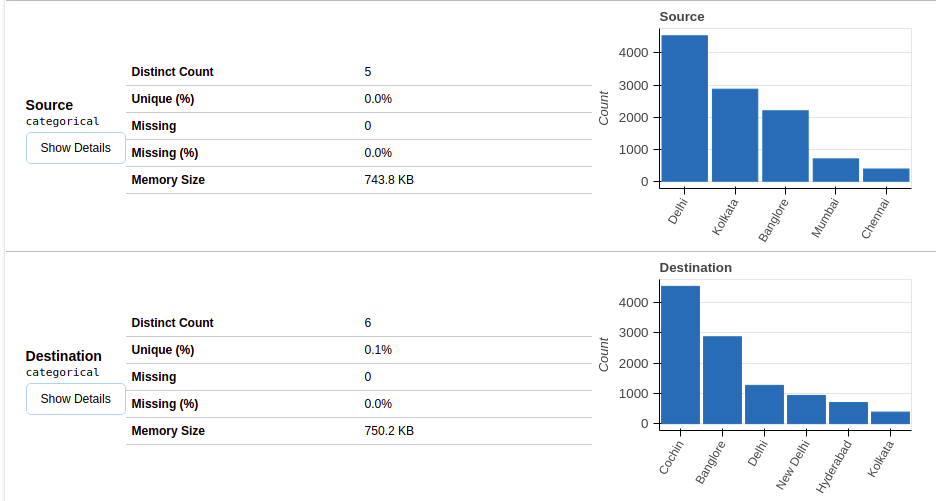
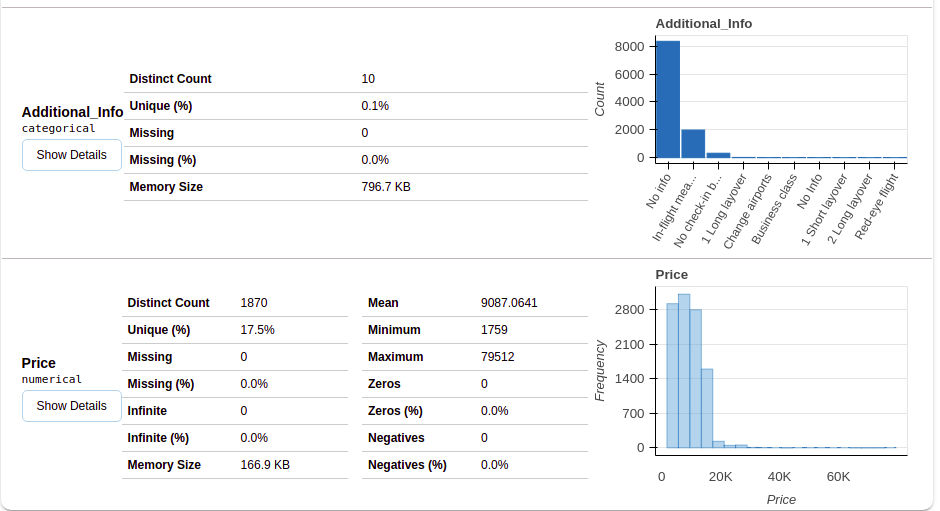
This section provides the type of each variable along with a detailed description of the variable..
4.2 Missing values
This section has several ways in which we can analyze missing values in variables. We will discuss three most used methods, bar graphicThe bar chart is a visual representation of data that uses rectangular bars to show comparisons between different categories. Each bar represents a value and its length is proportional to it. This type of chart is useful for visualizing and analyzing trends, facilitating the interpretation of quantitative information. It is widely used in various disciplines, such as statistics, Marketing and research, due to its simplicity and effectiveness...., espectro y heat mapa "heat map" is a graphical representation that uses colors to show the density of data in a specific area. Commonly used in data analytics, Marketing and behavioral studies, This type of visualization allows you to identify patterns and trends quickly. Through chromatic variations, Heat maps make it easier to interpret large volumes of information, helping to make informed decisions..... Let's explore each one by one.
4.2.1 Bar graphic
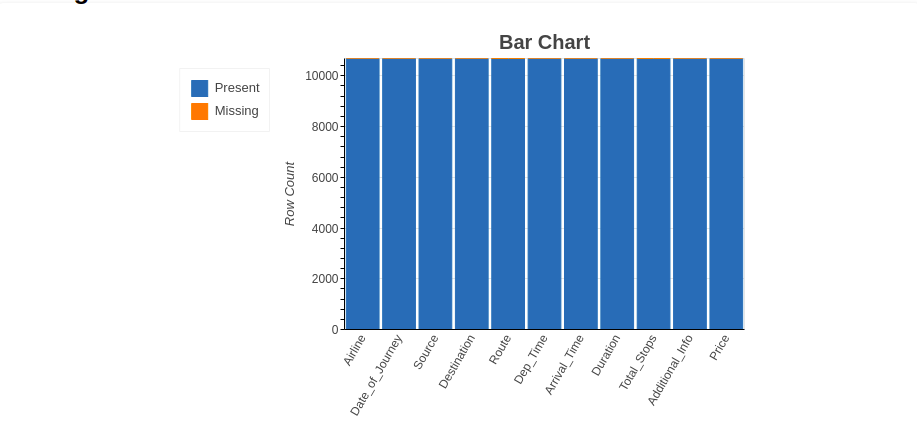
The bar chart method shows the 'number of missing and present values’ in each variable in a different color.
4.2.2 Spectrum
The spectrum method shows the percentage of missing values in each variable.
4.2.3 Heat map
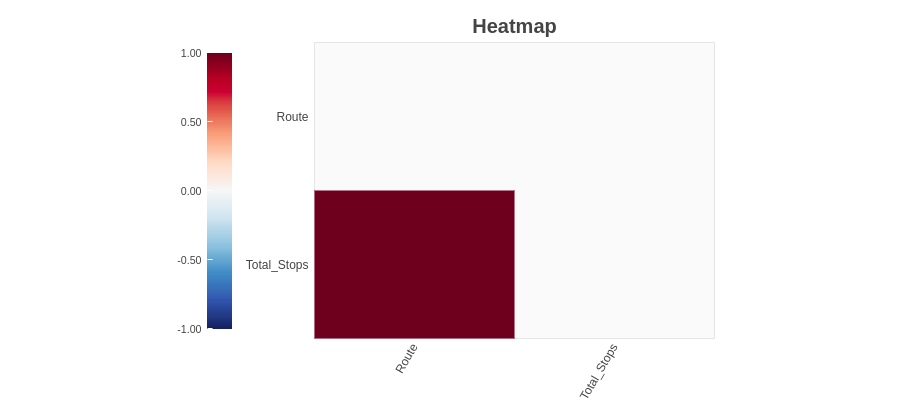
The heat map method shows the variables that have missing values in terms of correlation. Since ‘Route’ and ‘Total_Paradas’ are highly correlated, both have missing values.
As we can observe, the 'Path variables’ and ‘Total_Paradas’ have missing values. Since we did not find any missing value information from the spectrum bar chart method, but we find missing value variables using heat map method. Combining this information, we can say that the variables' Route’ and ‘Total_Paradas’ have missing values but are very low.
5. Data preparation
Before starting data preparation, let's take a look at the data first.
dataframe.head()

As we saw in Data Analysis, there is 11 variables in the given data. Below is the description of each variable.
Airline: Name of the airline used to travel
Date_of_Journey: Date a person traveled
Source: Flight start location
Destiny: Flight end location
Route: Contains information about the starting and ending location of the trip in the standard format used by airlines.
Dept_Time: Flight departure time from the starting point
Check In: Flight arrival time at destination
Duration: Flight duration in hours / minutes
Total_Stops: Total number of stopovers made by the flight before landing at the destination.
Additional Information: Show any additional information about a flight
Price: Flight price
Few observations on some of the variables:
1. ‘Price‘Will be our dependent variable and all the remaining variables can be used as independent variables.
2. ‘Total_Stops'Can be used to determine if the flight was direct or connecting.
5.1 Handling missing values
How we discovered, the 'Path variables’ and ‘Total_Paradas’ have very low missing values in the data. Let's now see the percentage of missing values in the data.
(dataframe.isnull().sum()/dataframe.shape[0])*100
Production :
Airline 0.000000 Date_of_Journey 0.000000 Source 0.000000 Destination 0.000000 Route 0.009361 Dept_Time 0.000000 Arrival_Time 0.000000 Duration 0.000000 Total_Stops 0.009361 Additional_Info 0.000000 Price 0.000000 dtype: float64
As we can observe, ‘Route’ y ‘Total_Stops’ they have both 0.0094% of lost values. In this case, it is better to remove missing values.
dataframe.dropna(inplace= True) dataframe.isnull().sum()
Production :
Airline 0 Date_of_Journey 0 Source 0 Destination 0 Route 0 Dept_Time 0 Arrival_Time 0 Duration 0 Total_Stops 0 Additional_Info 0 Price 0 dtype: int64
Now we have no lost value.
5.2 Handling date and time variables
Tenemos ‘Date_of_Journey’, a 'date type variable and’ Dept_Time',’ Arrival_Time 'that captures time information.
We can extract ‘Journey_day’ y ‘Journey_Month’ de la variable ‘Date_of_Journey’. “Travel day” shows the day of the month the trip started.
dataframe["Journey_day"] = pd.to_datetime(dataframe.Date_of_Journey, format="%d/%m/%Y").dt.day dataframe["Journey_month"] = pd.to_datetime(dataframe["Date_of_Journey"], format = "%d/%m/%Y").dt.month dataframe.drop(["Date_of_Journey"], axis = 1, inplace = True)
Similarly, we can extract ‘Departure time’ and ‘Departure time’ as well as ‘Arrival time and Arrival minute’ of the variables ‘Time_dep.’ And ‘Arrival time’ respectively.
dataframe["Dep_hour"] = pd.to_datetime(dataframe["Dept_Time"]).dt.hour dataframe["Dep_min"] = pd.to_datetime(dataframe["Dept_Time"]).dt.minute dataframe.drop(["Dept_Time"], axis = 1, inplace = True)
dataframe["Arrival_hour"] = pd.to_datetime(dataframe.Arrival_Time).dt.hour dataframe["Arrival_min"] = pd.to_datetime(dataframe.Arrival_Time).dt.minute dataframe.drop(["Arrival_Time"], axis = 1, inplace = True)
We also have information about the duration of the variable 'Duration'. This variable contains combined information of hours and minutes of duration.
We can extract ‘Duration_hours’ and ‘Duration_minutes’ separately from the variable 'Duration'.
def get_duration(x):
x=x.split(' ')
hours=0
mins=0
if len(x)==1:
x=x[0]
if x[-1]=='h':
hours=int(x[:-1])
else:
mins=int(x[:-1])
else:
hours=int(x[0][:-1])
mins=int(x[1][:-1])
return hours,mins
dataframe['Duration_hours']=dataframe.Duration.apply(lambda x:get_duration(x)[0])
dataframe['Duration_mins']=dataframe.Duration.apply(lambda x:get_duration(x)[1])
dataframe.drop(["Duration"], axis = 1, inplace = True)
5.3 Categorical data handling
Airline, Origin, Destiny, Route, Total_Stops, Additional information is the categorical variables that we have in our data. Let's handle each one by one.
Airline variable
Let's see how the variable Airline is related to the variable Price.
import seaborn as sns
sns.set()
sns.catplot(y = "Price", x = "Airline", data = train_data.sort_values("Price", ascending = False), kind="boxing", height = 6, aspect = 3)
plt.show()
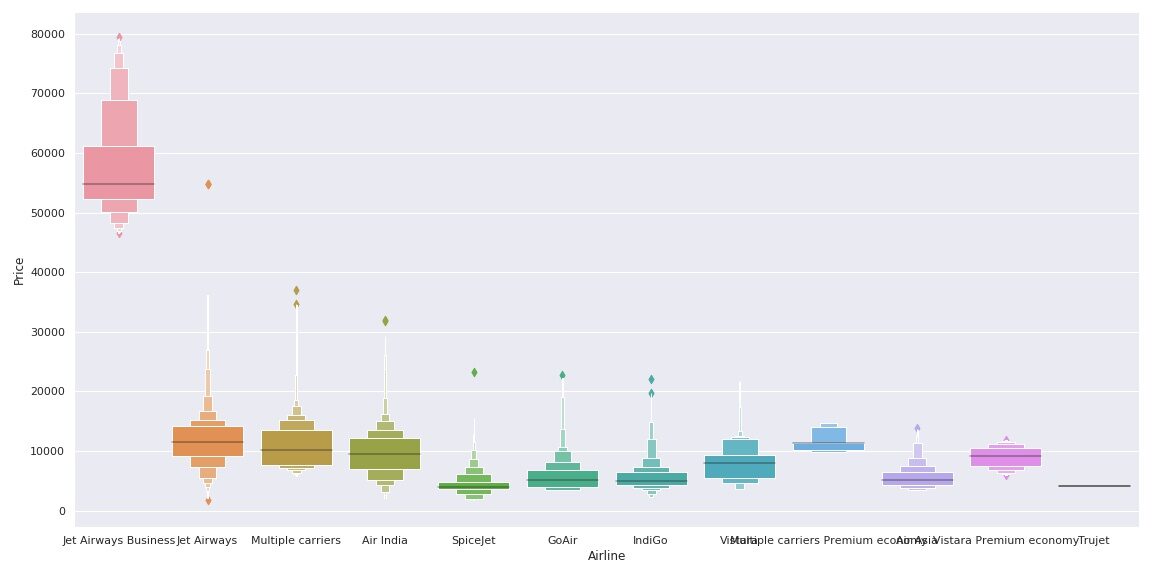
As we can see, the name of the airline matters. ‘JetAirways Business’ has the highest price range. The price of other airlines also varies.
From the Airline variable is Nominal categorical data (There is no order of any kind in the names of the airlines) we will use one-hot encoding to handle this variable.
Airline = dataframe[["Airline"]] Airline = pd.get_dummies(Airline, drop_first= True)
The data of ‘Airline’ encoded in One-Hot are stored in the variable Airline as shown in the code above.
Source and destination variable
Again, the 'Source variables’ and ‘Destination’ are nominal categorical data. We will use One-Hot encoding again to handle these two variables.
Source = dataframe[["Source"]] Source = pd.get_dummies(Source, drop_first= True) Destination = train_data[["Destination"]] Destination = pd.get_dummies(Destination, drop_first = True)
Path variable
The path variable represents the path of the journey. Since the variable ‘Total_Stops’ captures the information if the flight is direct or connected, I have decided to eliminate this variable.
dataframe.drop(["Route", "Additional_Info"], axis = 1, inplace = True)
Total_Stops Variable
dataframe["Total_Stops"].unique()
Production:
array(['non-stop', '2 stops', '1 stop', '3 stops', '4 stops'],
dtype=object)
Here, nonstop means 0 scales, what direct flight means. Similarly, the meaning of other values is obvious. We can see that it is a Ordinal categorical data then we will use LabelEncoder here to handle this variable.
dataframe.replace({"non-stop": 0, "1 stop": 1, "2 stops": 2, "3 stops": 3, "4 stops": 4}, inplace = True)
Variable Additional_Info
dataframe.Additional_Info.unique()
Production:
array(['No info', 'In-flight meal not included',
'No check-in baggage included', '1 Short layover', 'No Info',
'1 Long layover', 'Change airports', 'Business class',
'Red-eye flight', '2 Long layover'], dtype=object)
As we can see, This feature captures relevant information that can significantly affect the price of the flight.. The values ‘No information’ are also repeated.. Let's handle that first.
dataframe['Additional_Info'].replace({"No info": 'No Info'}, inplace = True)
However, this variable is also nominal categorical data. Let's use One-Hot Encoding to handle this variable.
Add_info = dataframe[["Additional_Info"]] Add_info = pd.get_dummies(Add_info, drop_first = True)
5.4 Final data frame
Now we will create the final data frame by concatenating all the tag-encoded and One-hot features into the original data frame. We will also remove the original variables with which we have prepared new encoded variables.
dataframe = pd.concat([dataframe, Airline, Source, Destination,Add_info], axis = 1) dataframe.drop(["Airline", "Source", "Destination","Additional_Info"], axis = 1, inplace = True)
Let's see the number of final variables we have in the data frame.
dataframe.shape[1]
Production:
38
Then, have 38 variables in final data frame, including the dependent variable 'Price'. There is only 37 variables para el trainingTraining is a systematic process designed to improve skills, physical knowledge or abilities. It is applied in various areas, like sport, Education and professional development. An effective training program includes goal planning, regular practice and evaluation of progress. Adaptation to individual needs and motivation are key factors in achieving successful and sustainable results in any discipline.....
6. Model building
X=dataframe.drop('Price',axis=1)
y = dataframe['Price']
#train-test split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, Y, test_size = 0.2, random_state = 42)
6.1 Lazy prediction app
One of the problems with the modeling exercise is “How to decide which machine learning algorithm to apply?”
This is where Lazy Prediction comes in.. Lazy Prediction is a machine learning library available in Python that can quickly provide us with the performance of multiple standard classifications or regression models on multiple performance matrices..
Let's see how it works ...
How we are working on a Regression task, we will use Regressors models.
from lazypredict.Supervised import LazyRegressor reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None) models, predictions = reg.fit(x_train, x_test, y_train, y_test) models.head(10)
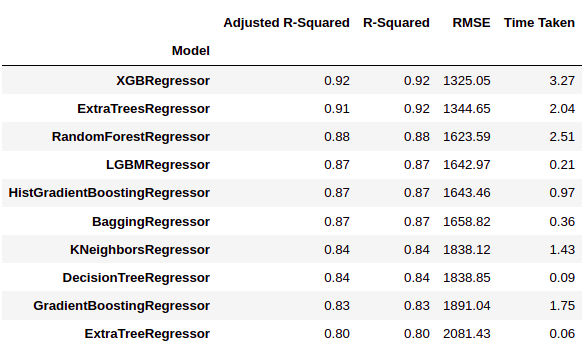
As we can see, LazyPredict gives us results from multiple models in multiple performance matrices. In the figure above, we have shown the ten best models.
Here ‘XGBRegressor’ and 'ExtraTreesRegressor’ significantly outperform other models. It takes a lot of training time over other models. In this step we can choose the priority if we want “weather” O “performance”.
We have decided to choose “performance” about training time. So we will train ‘XGBRegressor and visualize the final results.
6.2 Model training
from xgboost import XGBRegressor model = XGBRegressor() model.fit(x_train,y_train)
Production:
XGBRegressor(base_score=0.5, booster="gbtree", colsample_bylevel = 1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type="gain", interaction_constraints="",
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing = nan, monotone_constraints="()",
n_estimators = 100, n_jobs=0, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
Let's check the performance of the model …
y_pred = model.predict(x_test)
print('Training Score :',model.score(x_train, y_train))
print('Test Score :',model.score(x_test, y_test))
Production:
Training Score : 0.9680428701701702 Test Score : 0.918818721300552
As we can see, the model score is quite good. Let's visualize the results of some predictions.
number_of_observations=50
x_ax = range(len(y_test[:number_of_observations]))
plt.plot(x_ax, y_test[:number_of_observations], label="original")
plt.plot(x_ax, y_pred[:number_of_observations], label="predicted")
plt.title("Flight Price test and predicted data")
plt.xlabel('Observation Number')
plt.ylabel('Price')
plt.legend()
plt.show()
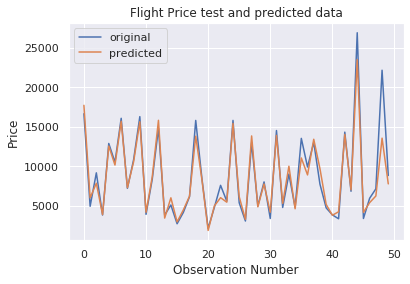
As we can see in the previous figure, model predictions and original prices overlap. This visual result confirms the high score of the model that we saw previously.
7. Conclution
In this article, we saw how to apply the Laze Prediction library to choose the best machine learning algorithm for the task at hand.
Lazy Prediction saves time and effort to create a machine learning model by providing model performance and training time. One can choose any according to the situation in question.
It can also be used to create a set of machine learning models. There are many ways the LazyPredict library functionalities can be used.
Hope this article has helped you understand the data analytics approaches, data preparation and modeling in a much easier way.
Contact the comment section in case of any query.
Thank you and have a nice day.. 🙂
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





