In the age of Big Data, Python has become the most searched language. In this article, Let's focus on one particular aspect of Python that makes it one of the most powerful programming languages: multiprocessing.
Now, before we dive into the essentials of multiprocessing, I suggest you read my previous article on Threading in Python, as it can provide a better context for the current article.
Suppose you are an elementary school student who has been given the daunting task of multiplying 1200 number pairs as homework. Suppose you are able to multiply a pair of numbers in 3 seconds. Later, total, are needed 1200 * 3 = 3600 seconds, What is it 1 time to solve all homework. But you have to catch up on your favorite TV show on 20 minutes.
What would you do? A smart student, although dishonest, call three more friends who have a similar ability and divide the task. Then you will have 250 multiplication tasks on your plate, that you will complete in 250 * 3 = 750 seconds, namely, 15 minutes. Therefore, you, along with his other 3 friends, will finish the task in 15 minutes, giving 5 minutes of time to have a snack and sit down to watch your TV show. The task only took 15 minutes when 4 of you worked together, what otherwise would have taken 1 time.
This is the basic ideology of multiprocessing. If you have an algorithm that can be divided into different workers (processors), then you can speed up the program. Today, the machines come with 4,8 Y 16 cores, which can then be implemented in parallel.
Multiple Processing in Data Science
Multiprocessing has two crucial applications in data science.
1. I / O processes
Any data intensive pipeline has input and output processes where millions of bytes of data flow throughout the system. As usual, the reading process (entry) of data won't take long, but the process of writing data to the datastores takes a long time. The writing process can be done in parallel, saving a lot of time.
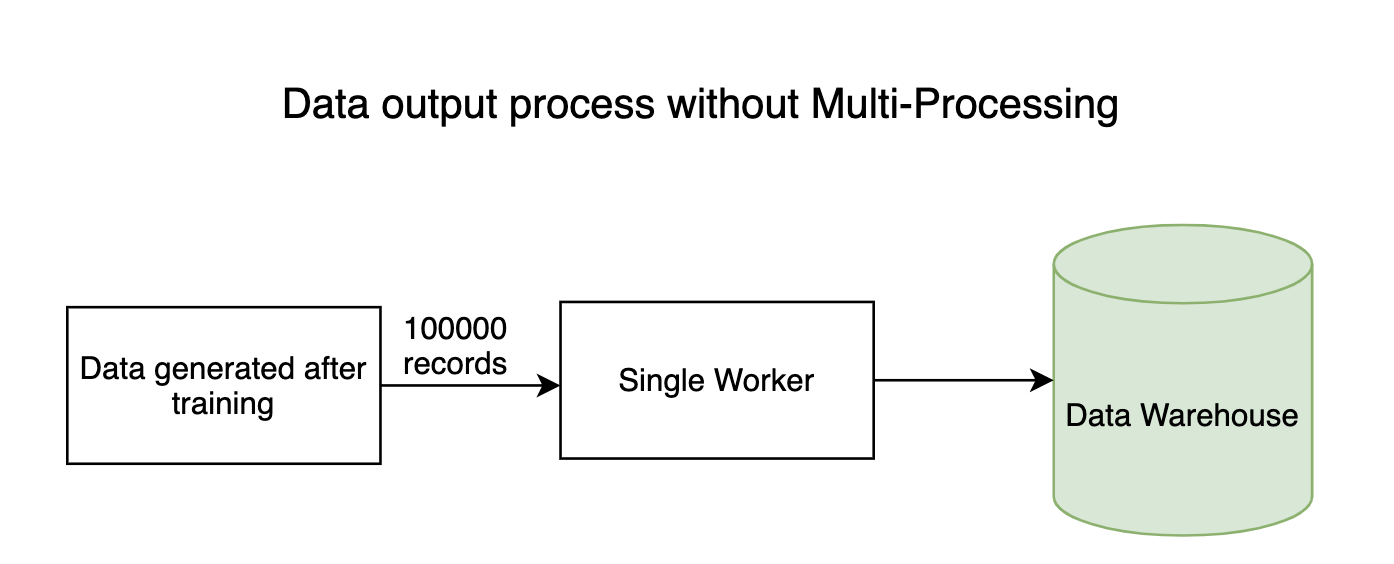
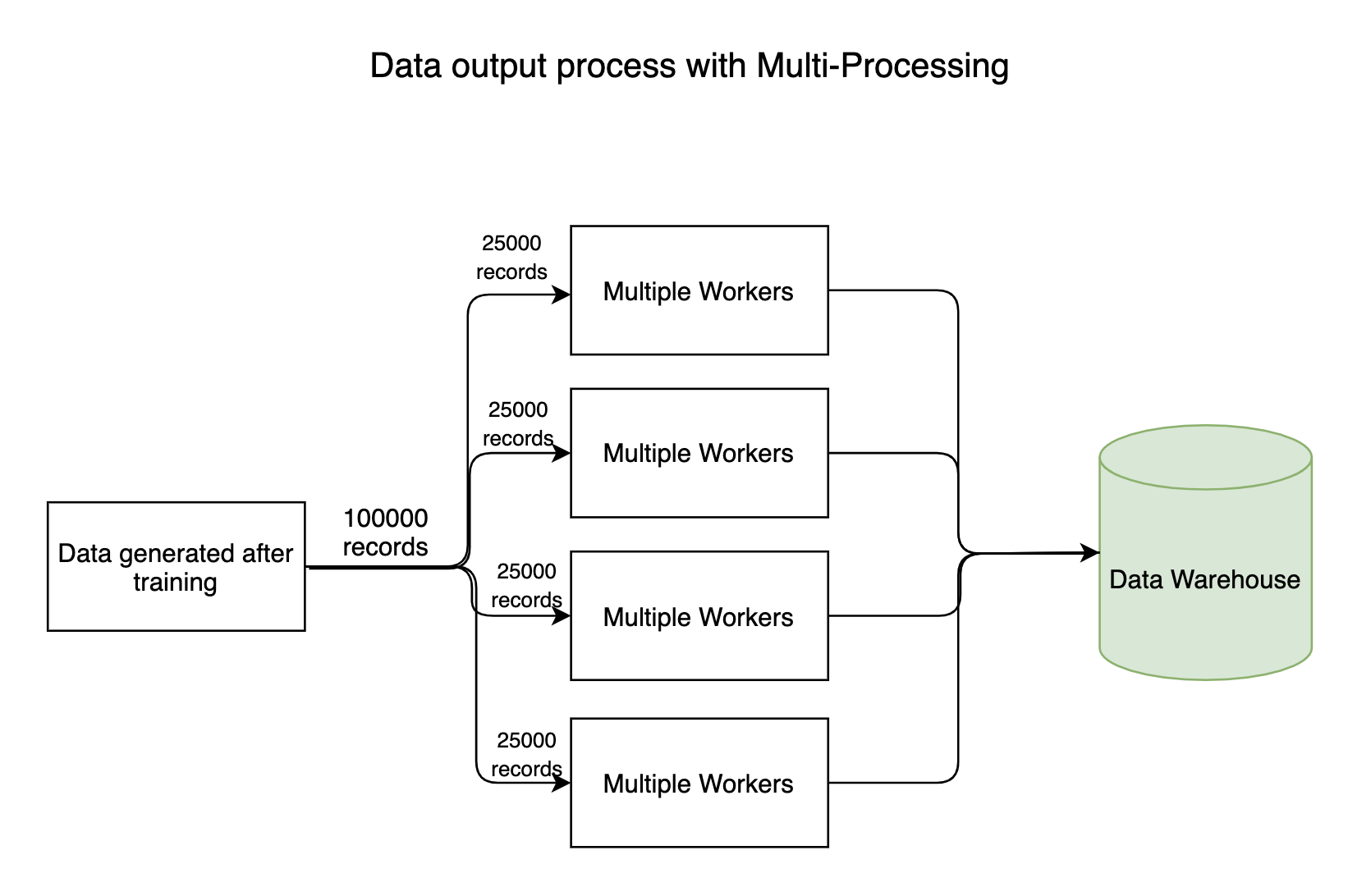
2. Training models
Although not all models can be trained in parallel, few models have inherent characteristics that allow them to be trained by parallel processing. For instance, the Random Forest algorithm implements multiple decision trees to make a cumulative decision. These trees can be built in parallel. In fact, the sklearn API comes with a parameter called n_jobs, which offers an option to use multiple workers.
Multiple processing in Python using Process class-
Now let's get our hands on it multiprocesamiento Python library.
Take a look at the following code
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
sleepy_man()
sleepy_man()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
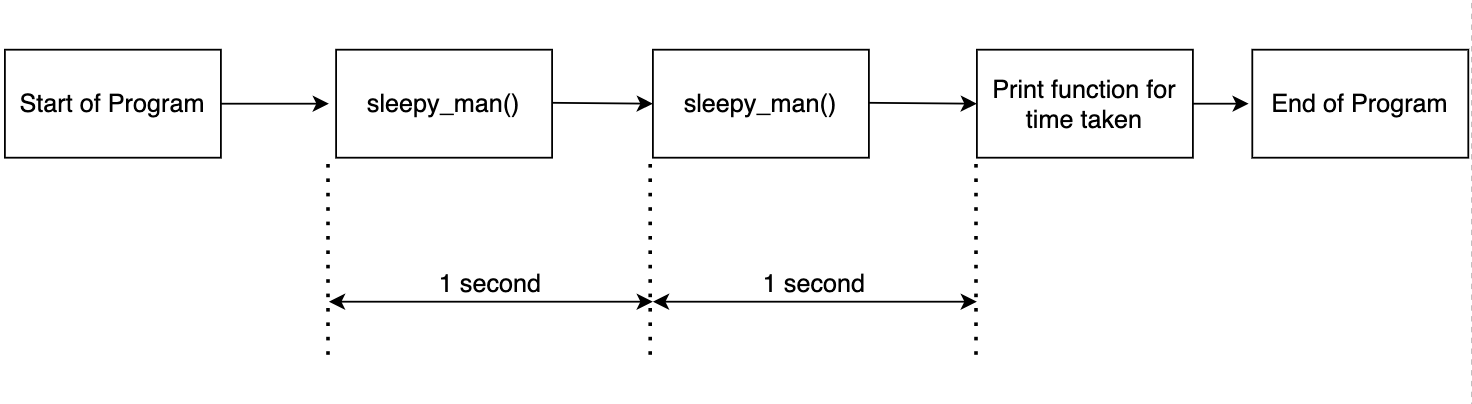
The above code is simple. The function sleepy_man sleep for a second and we call the function twice. We record the time required for the two function calls and print the results. The output is as shown below.
Starting to sleep Done sleeping Starting to sleep Done sleeping Done in 2.0037 seconds
This is expected as we call the function twice and record the time. The flow is shown in the following diagram.
Now let's incorporate multiprocessing into the code.
import multiprocessing import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
p1 = multiprocessing.Process(target= sleepy_man)
p2 = multiprocessing.Process(target= sleepy_man)
p1.start()
p2.start()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
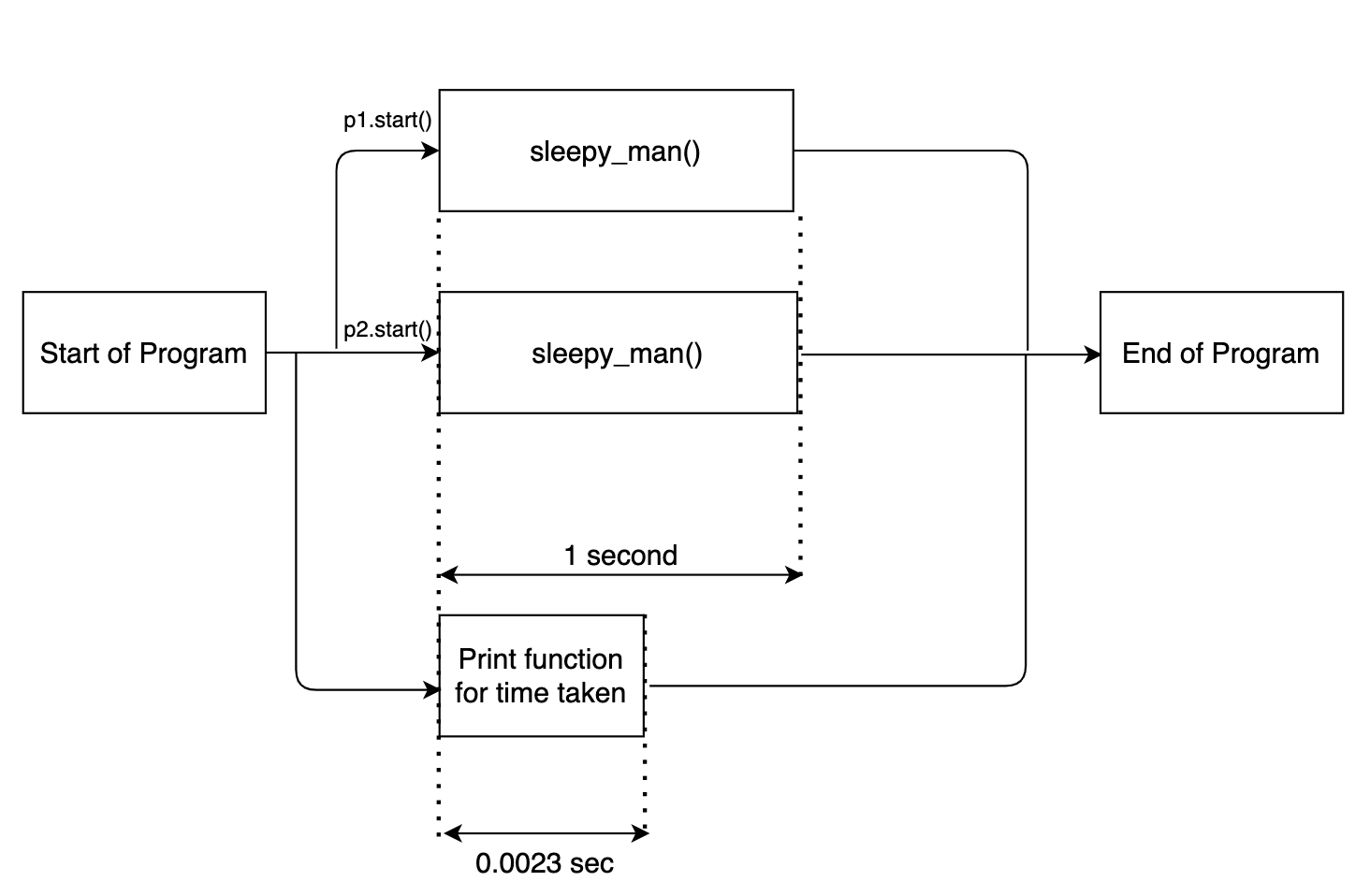
Here multiprocessing.process (target = sleepy_man) defines a multithreaded instance. We pass the required function to be executed, sleepy_man, as an argument. We activate the two instances by p1.start ().
The output is as follows:
Done in 0.0023 seconds Starting to sleep Starting to sleep Done sleeping Done sleeping
Now notice one thing. The time stamp print statement was executed first. This is because, along with multithreaded instances enabled for the sleepy_man function, the main code of the function was executed separately in parallel. The flow chart below will make things clear.
To run the rest of the program after the multithreaded functions run, we need to execute the function to enter().
import multiprocessing
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
p1 = multiprocessing.Process(target= sleepy_man)
p2 = multiprocessing.Process(target= sleepy_man)
p1.start()
p2.start()
p1.join()
p2.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
Now, the rest of the code block will only be executed after the multiprocessing tasks are done. The output is shown below.
Starting to sleep Starting to sleep Done sleeping Done sleeping Done in 1.0090 seconds
The flow chart is shown below.
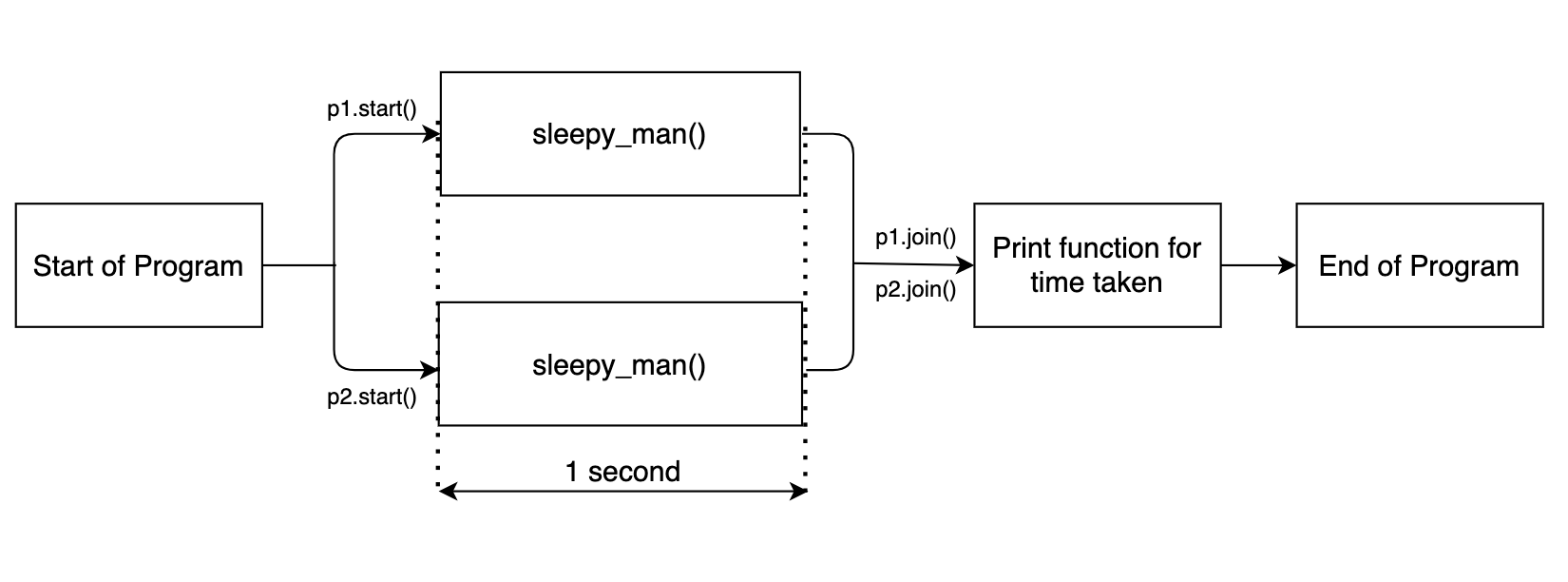
Since the two suspension functions run in parallel, the function as a whole takes about 1 second.
We can define any number of multiprocessing instances. Look at the code below. Define 10 different multiprocessing instances using a for a loop.
import multiprocessing
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
process_list = []
for i in range(10):
p = multiprocessing.Process(target= sleepy_man)
p.start()
process_list.append(p)
for process in process_list:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
The output of the above code is shown below.
Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done in 1.0117 seconds
Here, all ten function executions are processed in parallel and, Thus, the whole program takes just a second. Now my machine has no 10 processors. When we define more processes than our machine, multiprocessing library has logic to schedule jobs. So you don't have to worry about it.
We can also pass arguments to the Process function using arguments.
import multiprocessing
import time
def sleepy_man(sec):
print('Starting to sleep')
time.sleep(sec)
print('Done sleeping')
tic = time.time()
process_list = []
for i in range(10):
p = multiprocessing.Process(target= sleepy_man, args = [2])
p.start()
process_list.append(p)
for process in process_list:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
The output of the above code is shown below.
Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done in 2.0161 seconds
Since we pass an argument, the sleepy_man function slept during 2 seconds instead of 1 second.
Multiple processing in Python using Pool class-
In the last code snippet, we execute 10 different processes using a for loop. Instead, we can use the Pool method to do the same.
import multiprocessing
import time
def sleepy_man(sec):
print('Starting to sleep for {} seconds'.format(sec))
time.sleep(sec)
print('Done sleeping for {} seconds'.format(sec))
tic = time.time()
pool = multiprocessing.Pool(5)
pool.map(sleepy_man, range(1,11))
pool.close()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
Pool multiprocessing (5) defines the number of workers. Here we define the number as 5. pool.map () is the method that triggers the execution of the function. We call pool.map (sleepy_man, rank (1,11)). Here, sleepy_man is the function to be called with the parameters for the executions of functions defined by rank (1,11) (usually a list is passed). The output is as follows:
Starting to sleep for 1 seconds Starting to sleep for 2 seconds Starting to sleep for 3 seconds Starting to sleep for 4 seconds Starting to sleep for 5 seconds Done sleeping for 1 seconds Starting to sleep for 6 seconds Done sleeping for 2 seconds Starting to sleep for 7 seconds Done sleeping for 3 seconds Starting to sleep for 8 seconds Done sleeping for 4 seconds Starting to sleep for 9 seconds Done sleeping for 5 seconds Starting to sleep for 10 seconds Done sleeping for 6 seconds Done sleeping for 7 seconds Done sleeping for 8 seconds Done sleeping for 9 seconds Done sleeping for 10 seconds Done in 15.0210 seconds
Pool class is a better way to implement multiprocessing because it distributes tasks to available processors using the First In program, first out. It is almost similar to the map-reduce architecture, in essence, assigns the input to different processors and collects the output from all processors as a list. Running processes are stored in memory and other non-running processes are stored out of memory.
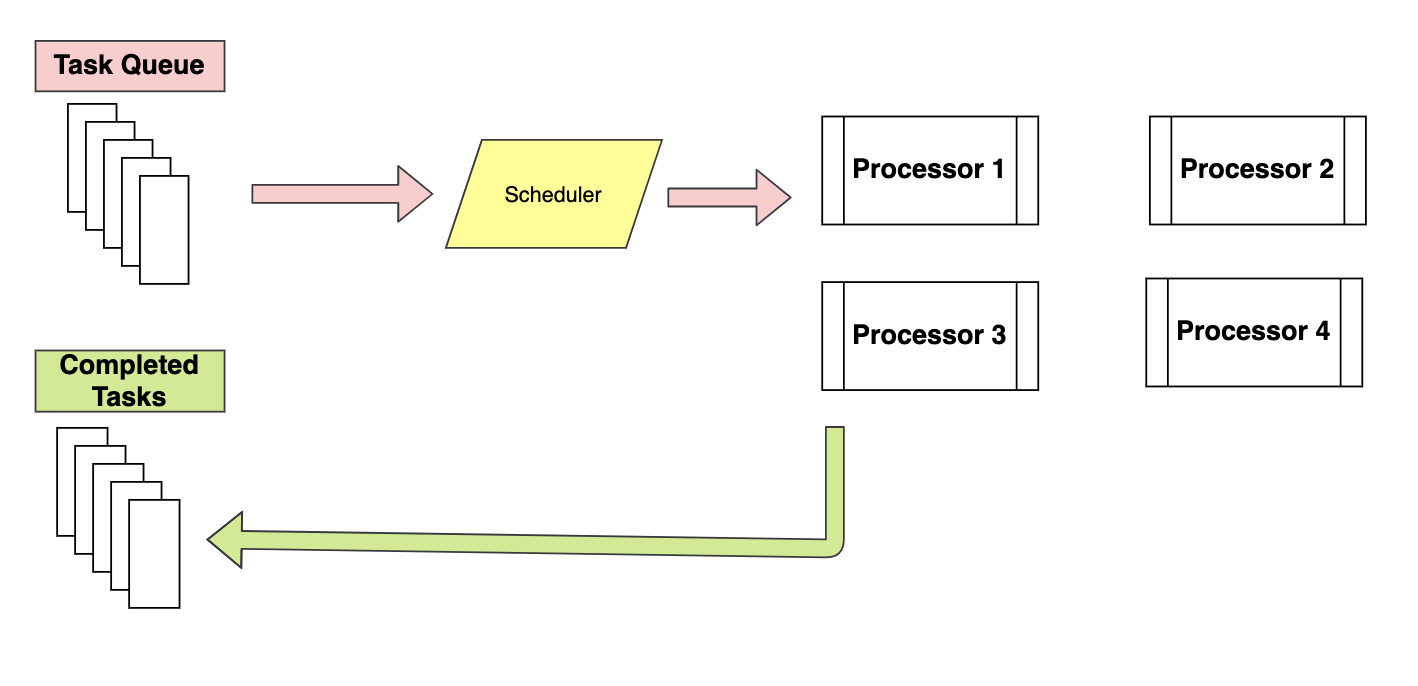
While in Process class, all processes are executed in memory and their execution is scheduled using the FIFO policy.
Comparing the performance of time to calculate perfect numbers-
Up to now, we play with multiprocesamiento functions in to sleep functions. Now let's take a function that checks if a number is a Perfect Number or not. For those who don't know, a number is a perfect number if the sum of its positive divisors is equal to the number itself. We will list the perfect numbers less than or equal to 100000. We will implement it from 3 shapes: using a for regular loop, using multiprocess.Process () y multiprocess.Pool ().
Using a regular for a loop
import time
def is_perfect(n):
sum_factors = 0
for i in range(1, n):
if (n % i == 0):
sum_factors = sum_factors + i
if (sum_factors == n):
print('{} is a Perfect number'.format(n))
tic = time.time()
for n in range(1,100000):
is_perfect(n)
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
The result of the above program is shown below.
6 is a Perfect number 28 is a Perfect number 496 is a Perfect number 8128 is a Perfect number Done in 258.8744 seconds
Using a process class
import time
import multiprocessing
def is_perfect(n):
sum_factors = 0
for i in range(1, n):
if(n % i == 0):
sum_factors = sum_factors + i
if (sum_factors == n):
print('{} is a Perfect number'.format(n))
tic = time.time()
processes = []
for i in range(1,100000):
p = multiprocessing.Process(target=is_perfect, args=(i,))
processes.append(p)
p.start()
for process in processes:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
The result of the above program is shown below.
6 is a Perfect number 28 is a Perfect number 496 is a Perfect number 8128 is a Perfect number Done in 143.5928 seconds
How could you see, we achieved a reduction of 44,4% in time when we implement multiprocessing using Process class, instead of a regular for loop.
Using a Pool class
import time
import multiprocessing
def is_perfect(n):
sum_factors = 0
for i in range(1, n):
if(n % i == 0):
sum_factors = sum_factors + i
if (sum_factors == n):
print('{} is a Perfect number'.format(n))
tic = time.time()
pool = multiprocessing.Pool()
pool.map(is_perfect, range(1,100000))
pool.close()
toc = time.time()
print('Done in {:.4f} seconds'.format(knock-tic))
The result of the above program is shown below.
6 is a Perfect number 28 is a Perfect number 496 is a Perfect number 8128 is a Perfect number Done in 74.2217 seconds
As you can see, compared to a regular for loop, we achieved a reduction of 71,3% in calculation time, and compared to the Process class, we achieved a reduction of 48,4% in calculation time.
Therefore, It is very evident that by implementing a suitable method from the multiprocesamiento library, we can achieve a significant reduction in calculation time.
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





